구조화된 EHR 기반 모델의 토크나이제이션 설계가 성능과 효율성에 미치는 영향
본 연구는 소아 환자 전자건강기록(EHR)을 이용해 토크나이제이션 방식을 2×2×2 요인 설계로 비교하였다. 이벤트를 단일 토큰으로 결합하는 ‘joint encoding’과 시간 정보를 위치 인코딩으로 표현하는 ‘positional time encoding’이 대부분의 74개 임상 예측 과제에서 우수한 AUROC를 보였으며, 사전학습 연산량도 각각 39.5%와 9.6% 감소하였다. 이러한 이점은 코드‑속성 쌍을 하나의 토큰에 미리 결합함으로써 …
저자: Lin Lawrence Guo, Santiago Eduardo Arciniegas, Joseph Jihyung Lee
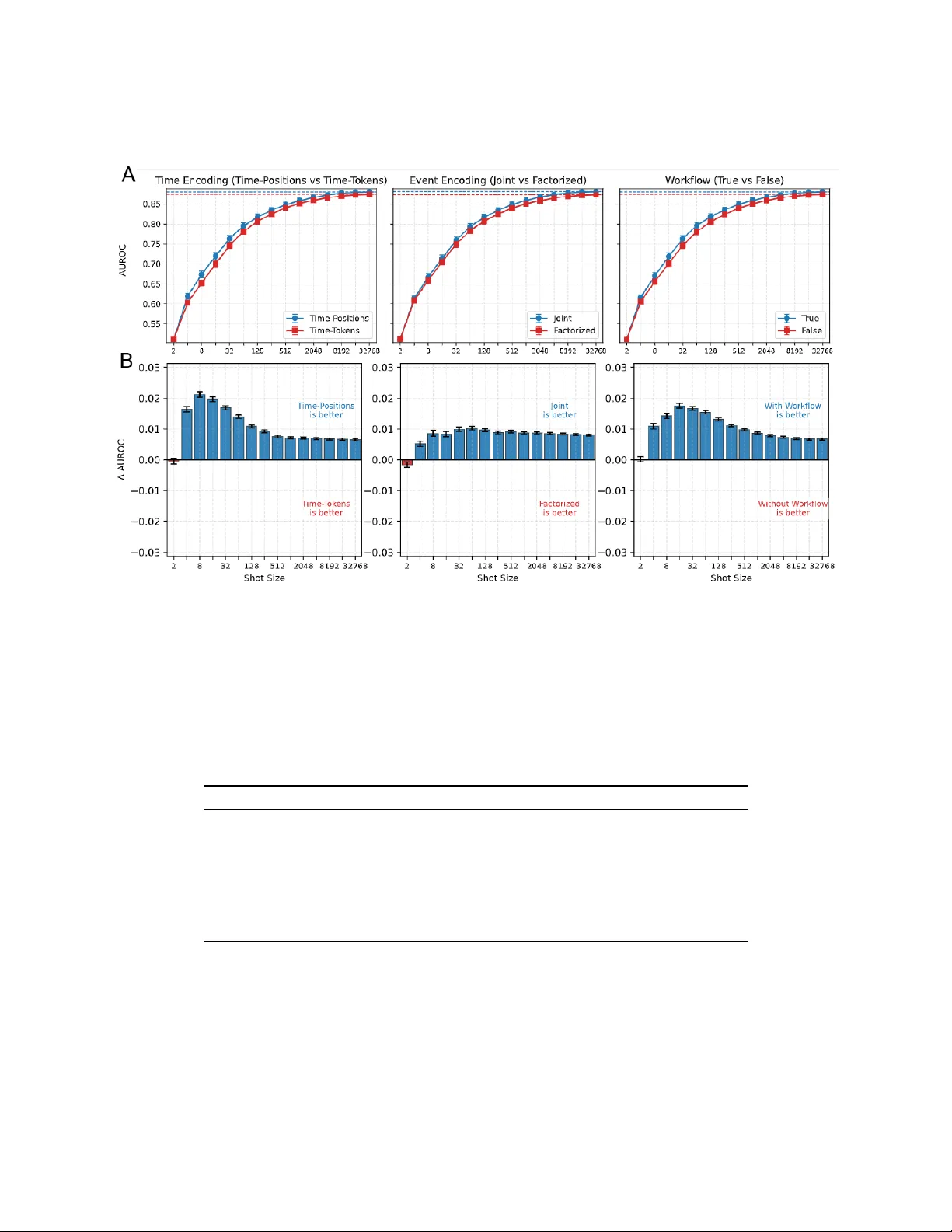
본 연구는 구조화된 전자의무기록(EHR) 데이터를 활용한 Foundation Model의 사전학습 단계에서 토크나이제이션이 모델 성능과 연산 효율성에 미치는 영향을 정량적으로 평가한다. 저자들은 캐나다 토론토에 위치한 소아병원(Hospital for Sick Children, SickKids)의 2백만 명 환자, 3억 1천9백만 건 이벤트를 포함하는 대규모 코호트를 사용해 2×2×2 요인 설계(factorial design)를 수행하였다.
첫 번째 축인 이벤트 인코딩은 ‘joint encoding’과 ‘factorized encoding’으로 나뉜다. joint encoding은 진단·검사·약물 등 각 임상 이벤트를 코드와 속성(예: 실험실 수치의 분위수)을 하나의 토큰으로 결합한다. 반면 factorized encoding은 코드를 별도 토큰으로 두고, 속성 토큰을 추가로 배치한다. 두 번째 축인 시간 인코딩은 ‘Time‑Positions’와 ‘Time‑Tokens’로 구분한다. Time‑Positions는 환자 연령(일 단위)을 토큰 위치에 직접 매핑하고 Rotary Positional Embedding(RoPE)을 적용해 시간 간격을 인코딩한다. Time‑Tokens는 이벤트 사이에 13개의 이산 시간 구간 토큰을 삽입하고, 순차적 위치 인덱스에 RoPE를 적용한다. 세 번째 축은 워크플로우 단계 주석이다. 워크플로우를 포함하면 검사·시술 등의 다단계 과정을 각각 별도 이벤트(주문, 채취, 결과 등)로 기록해 시퀀스 길이를 늘리지만, 프로세스 정보를 보존한다. 워크플로우 정보를 제외하면 각 임상 행동을 최종 결과 시점 하나의 이벤트로 축소한다.
각 조합마다 고유 어휘(vocabulary)를 구축하고, 28층, 768 차원, 16M 파라미터를 갖는 Transformer를 사전학습했다. 사전학습 목표는 다음 토큰 예측이며, FLOPs와 토큰 길이를 기록했다. 사전학습이 완료된 모델은 74개의 임상 예측 과제(혈액 수혈, 시술, 영상, 실험실 검사, 약물 투여, 사망·재입원·장기 입원 등)에서 frozen encoder를 사용해 linear probe을 수행했으며, full‑shot 및 few‑shot(2~32k 샘플) 설정에서도 평가했다.
주요 결과는 다음과 같다. (1) Joint encoding은 factorized 대비 73/74 과제에서 AUROC가 유의하게 높았으며, 토큰당 평균 길이가 약 40% 감소해 사전학습 FLOPs가 39.5% 절감되었다. 이는 코드‑속성 결합을 토큰 수준에서 미리 수행함으로써 모델이 로컬 바인딩(local binding) 문제를 학습할 필요가 없어 효율이 증가한 것으로 해석된다. (2) Time‑Positions는 Time‑Tokens보다 71/74 과제에서 우수했으며, FLOPs 감소율은 9.6%에 달했다. 시간 정보를 순수 순서가 아닌 실제 연령(일)으로 매핑함으로써 의미적 연속성을 보존하고, 불필요한 시간 토큰 삽입에 따른 시퀀스 길이 증가를 방지했다. (3) 워크플로우 주석은 기관 특성에 민감했다. SickKids 내부에서는 워크플로우 포함 모델이 일부 실험실·시술 과제에서 약간의 성능 향상을 보였지만, 외부 MIMIC‑IV 성인 ICU 데이터에서는 워크플로우 정보를 활용할 수 없었음에도 joint 및 positional 인코딩의 장점은 유지되었다. 이는 워크플로우 효과가 병원·연령대별 프로세스 차이에 크게 좌우된다는 점을 시사한다.
추가적인 ablation 실험에서는 (i) joint encoding의 이점을 제거하기 위해 코드와 속성을 별도 토큰으로 분리했을 때 성능이 급격히 떨어짐을 확인했으며, (ii) 시간 인코딩을 순수 순서만 사용하거나 무작위 위치에 매핑했을 경우 AUROC가 감소함을 보여, 시간 정보의 정확한 표현이 모델 성능에 필수적임을 입증했다.
외부 검증에서는 MIMIC‑IV 코호트(성인 ICU 환자)에서 13개의 과제(3개 임상 결과 + 10개 실험실 결과)로 평가했으며, joint 및 positional 인코딩 모델이 기존 베이스라인(스크래치 학습)보다 일관되게 높은 AUROC를 기록했다. 다만, 시간 인코딩 파라미터(연령 구간)와 워크플로우 단계는 성인·소아 인구통계 차이로 인해 재조정이 필요했다.
결론적으로, 토크나이제이션 설계는 EHR 기반 Foundation Model의 핵심 레버이며, 특히 코드‑속성 결합을 토큰 수준에서 수행하는 joint encoding과 환자 연령을 직접 반영하는 positional time encoding이 성능과 연산 효율을 동시에 개선한다는 실증적 근거를 제공한다. 이러한 설계 원칙은 데이터 양이 제한적인 의료 AI 환경에서 모델 개발 비용을 낮추고, 다양한 임상 과제에 대한 일반화 능력을 향상시키는 데 유용하다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기