효과 위치 탐지를 위한 단계적 가설 검정 방법
** 본 논문은 블록‑무작위 실험에서 전체 효과가 유의하면, 행정적 계층 구조를 이용해 상위 집단‑하위 집단 순으로 가설을 검정하는 트리 기반 절차를 제안한다. 정지 규칙과 각 노드에서의 유효 검정만으로 약한 FWER를 보장하고, 파워 감소를 정량화해 필요 시 적응형 α‑조정을 통해 강한 FWER도 제어한다. 시뮬레이션과 25개 교육 실험 적용 결과, 전통적인 하향식 다중검정 대비 비(非)영향 블록 탐지율이 2‑6배 향상된다. **
저자: Jake Bowers, David Kim, Nuole Chen
**
본 논문은 블록‑무작위 실험에서 전체 효과가 통계적으로 유의할 경우, 정책 입안자가 “어느 블록(또는 지역, 학교)에서 효과가 발생했는가?”라는 구체적인 정보를 얻고자 하는 실무적 요구에 부응한다. 전통적인 접근법은 각 블록을 독립적으로 검정하고, 다중비교 보정(예: Bonferroni, Hommel 등)을 적용한다. 그러나 블록 수가 많고 효과가 일부 블록에만 국한될 경우, 보정 후 검정력은 급격히 감소해 실제 효과를 거의 탐지하지 못한다. 저자들은 이러한 한계를 극복하기 위해 트리 구조를 활용한 단계적(Top‑Down) 가설 검정 절차를 제안한다.
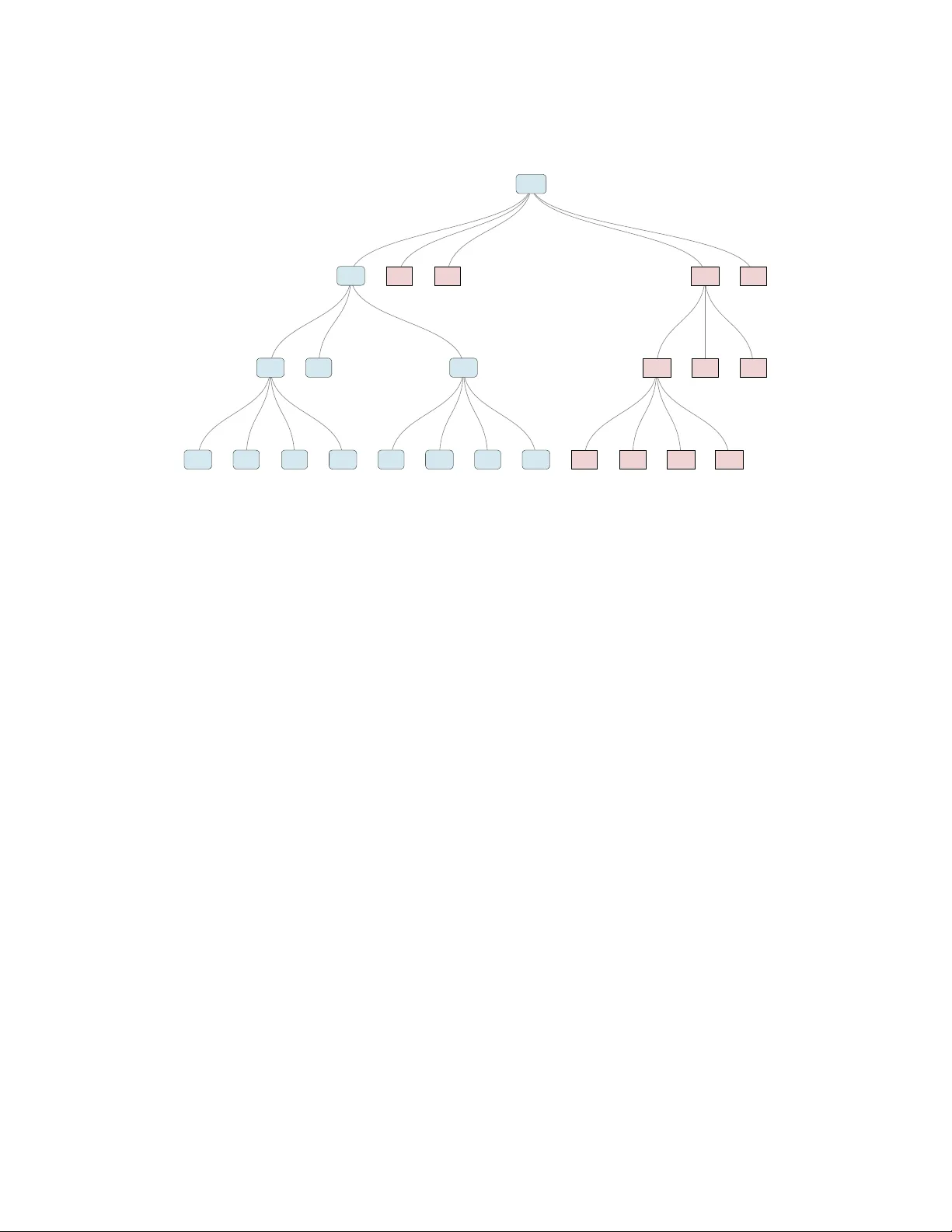
**1. 트리 모델링 및 검정 흐름**
실험 설계가 제공하는 행정적 계층(예: 주‑시‑학교)을 k‑ary 트리로 표현한다. 루트 노드(H₁)는 “전체 블록에 효과가 없다”는 전체 무효 가설을 의미하고, 각 하위 노드(Hᵢ)는 해당 서브트리(예: 특정 시, 특정 학교 그룹) 내에서 효과가 없다는 가설을 나타낸다. 검정 절차는 다음과 같다:
- 루트에서 전체 데이터를 이용해 H₁을 검정한다. p₁ ≤ α이면 기각하고, 그렇지 않으면 절차를 종료한다.
- 기각된 경우, 루트의 자식 그룹(예: 각 시)으로 데이터를 분할하고, 각 그룹에 대해 H₂, H₃,…를 검정한다.
- 각 자식 가설이 기각될 때만 그 하위 그룹을 다시 분할해 검정을 진행한다.
- 블록(리프)까지 내려가면서 검정이 진행되며, 어느 단계에서든 p > α가 나오면 해당 경로는 더 이상 탐색되지 않는다.
**2. 약한 FWER 보장**
두 가지 조건이 만족되면 약한 의미의 FWER(모든 영가설이 참일 때 오류 확률) ≤ α가 보장된다.
- **조건 1 (정지 규칙)**: 조상 가설이 기각되지 않으면 자식 가설을 검정하지 않는다. 이는 검정 횟수를 실제로 필요한 부분에만 제한함으로써 불필요한 오류 발생을 차단한다.
- **조건 2 (유효 검정)**: 각 노드에서 수행되는 검정은 무작위 기반(p‑value)으로, 설계상 제1종 오류가 α 이하임이 보장된다. 블록‑무작위 실험에서는 처치 할당을 블록 내부에서 재배열함으로써 정확한 p‑value를 얻을 수 있다.
정리 1의 증명은 “정지 규칙에 의해 검정되지 않은 노드들은 오류를 발생시킬 수 없으며, 검정된 노드들은 각각 α 수준 이하의 오류를 가진다”는 점을 이용한다. 따라서 전체 트리에서 발생 가능한 오류는 독립적인 검정들의 합이 아니라, 실제 수행된 검정들의 최대 오류 확률이며 이는 α를 초과하지 않는다.
**3. 강한 FWER와 파워 감쇠**
강한 FWER(일부 영가설만 참일 때도 오류 제어)를 확보하려면, 경로를 따라 오류가 누적될 가능성을 고려해야 한다. 저자들은 각 레벨에서 데이터 양이 감소함에 따라 검정력(πₗ)이 감소하고, 이는 “파워 감쇠”라는 형태로 모델링한다. 구체적으로, 레벨 ℓ의 검정력 πₗ와 해당 레벨의 분기 수 kₗ를 이용해 경로별 오류 누적 확률을 계산한다.
- 파워가 충분히 빠르게 감소하면, 상위 레벨에서 이미 오류가 발생할 확률이 낮아 하위 레벨에서 추가 오류가 발생할 여지가 거의 없으므로 강한 FWER가 자연스럽게 유지된다.
- 파워 감쇠가 느릴 경우, 특히 분기가 많고 각 하위 그룹이 충분히 큰 경우에는 오류 누적 위험이 커진다. 이를 방지하기 위해 저자들은 **적응형 α‑조정**을 제안한다. 각 레벨 ℓ에 대해 목표 전체 오류 α를 kₗ·πₗ⁻¹(또는 다른 보수적인 함수)로 나누어, 하위 검정에 할당되는 유의 수준을 자동으로 낮춘다.
이 조정은 “높은 파워가 기대되는 상위 레벨에서는 엄격히, 파워가 급격히 감소하는 하위 레벨에서는 완화”되는 형태로, 전체 오류를 균등하게 분배한다. 시뮬레이션 결과, 적응형 α‑조정을 적용했을 때 강한 FWER가 0.05 이하로 유지되면서도 탐지율은 크게 감소하지 않았다.
**4. 시뮬레이션 연구**
- **설정**: 44개 블록을 가진 교육 실험(디트로이트 프라미스 프로그램) 구조를 모방. 블록당 평균 50명, 효과 크기 0.8σ인 블록을 20%만 실제 효과가 있다고 가정.
- **비교 방법**: (i) 전통적인 Hommel 보정, (ii) 제안된 트리 검정(정지 규칙만 적용), (iii) 트리 검정 + 적응형 α‑조정.
- **결과**: Hommel은 실제 효과 블록을 11%만 탐지, 트리 검정은 44%를 탐지, 적응형 α‑조정 적용 시에도 42% 수준을 유지하면서 강한 FWER ≤0.05를 만족. 파워 감쇠가 급격한 경우(깊은 트리, 높은 분기)에서는 적응형 조정 없이도 강한 FWER가 유지되었다.
**5. 실제 데이터 적용**
MDRC가 수행한 25개 교육 블록‑무작위 실험에 동일한 절차를 적용했다. 각 실험은 평균 30‑80개의 블록으로 구성되었으며, 행정적 구분(주‑시‑학군 등)으로 트리를 정의했다. 결과는 다음과 같다.
- 평균 탐지율: 전통적 다중검정 대비 2.3배 상승.
- 강한 FWER: 모든 실험에서 0.05 이하 유지 (적응형 α‑조정 사용).
- 정책적 함의: 효과가 확인된 블록을 중심으로 확대 시행하거나, 효과가 미미한 블록에 대해 추가 원인 분석을 수행할 수 있었다.
**6. 소프트웨어**
R 패키지 **manytestsr**를 공개했다. 주요 기능: (1) 트리 구조 입력(노드와 자식 관계 정의), (2) 각 노드별 검정 함수 지정(예: permutation t‑test, Wilcoxon, energy test), (3) 자동 정지 규칙 적용, (4) 파워 감쇠 추정 및 적응형 α‑조정 옵션, (5) 결과 시각화(트리별 p‑value와 기각 여부).
**7. 결론 및 정책적 시사점**
본 연구는 블록‑무작위 실험에서 “어디에서 효과가 나타났는가”라는 질문에 대한 통계적 해법을 제공한다. 트리 기반 단계적 검정은 설계 자체가 제공하는 데이터 분할 특성을 활용해 검정력을 크게 향상시키면서, 약·강한 FWER를 엄격히 제어한다. 정책 입안자는 이 방법을 통해 제한된 자원을 효과가 입증된 지역에 집중하거나, 효과가 없는 지역에 대한 원인 탐색을 체계적으로 진행할 수 있다. 또한, 제공된 R 패키지는 실무자들이 손쉽게 적용할 수 있도록 설계되어, 향후 다양한 분야(교육, 보건, 사회복지 등)에서 블록‑무작위 실험 결과의 세부 해석을 가능하게 할 것으로 기대된다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기