고차원 선형 회귀에서 저정밀 훈련의 스케일링 법칙
본 논문은 고차원 스케치 선형 회귀 모델에 양자화된 SGD를 적용하여, 신호‑종속(곱셈) 양자화와 신호‑독립(덧셈) 양자화가 모델 크기와 데이터 크기에 미치는 영향을 이론적으로 규명한다. 두 양자화 방식 모두 효과적인 데이터 크기를 감소시키지만, 곱셈 양자화는 모델 용량을 유지하고, 덧셈 양자화는 모델 용량을 축소한다는 핵심 이분법을 제시한다. 정량적 위험 상한·하한을 통해 이러한 현상을 수학적으로 입증하고, 실험으로 검증한다.
저자: Dechen Zhang, Xuan Tang, Yingyu Liang
본 논문은 “저정밀 훈련”이라는 현대 딥러닝 실무에서 필수적인 문제를 이론적으로 해명하고자 한다. 대규모 언어 모델이 모델 파라미터 수 M과 데이터 샘플 수 N의 스케일링 법칙에 따라 성능이 향상된다는 기존 연구(Kaplan et al., 2020 등)를 출발점으로, 양자화 비트폭 Q가 추가된 세 축(M, N, Q)의 최적 배분 문제를 다룬다. 기존 경험적 스케일링 법칙은 양자화가 모델 용량을 감소시킨다(효과적 M_eff)거나, 단순히 손실에 추가적인 오류 δ를 더한다는 두 가지 형태로 제시되었지만, 이들 사이의 관계와 근본 메커니즘은 명확히 규명되지 않았다.
논문은 이를 해결하기 위해 고차원 스케치 선형 회귀 모델을 채택한다. 입력 데이터 x∈ℝ^p는 Hilbert 공간 H에 존재하고, 고정된 스케치 행렬 S∈ℝ^{M×H}가 Gaussian(0,1/M)으로 샘플링된다. 모델은 f_v(x)=⟨v, Sx⟩이며, 파라미터 v∈ℝ^M을 양자화된 SGD로 학습한다. 양자화 연산 Q_d, Q_s, Q_f, Q_l, Q_p, Q_a, Q_o는 각각 데이터, 스케치, 피처, 라벨, 파라미터, 활성화, 출력 그래디언트를 양자화한다. 모든 Q_i는 무편향(unbiased)이며, 두 가지 오류 구조—곱셈 양자화와 덧셈 양자화—를 정의한다.
곱셈 양자화는 오류 공분산이 입력 신호의 외적에 비례하는 형태(ε xxᵀ)이며, 이는 부동소수점(FP) 양자화에서 지수와 가수 비트가 신호 크기에 따라 동적으로 스케일링되는 특성을 반영한다. 반면 덧셈 양자화는 오류 공분산이 항등행렬에 비례(ε I)하는 형태로, 정수(INT) 양자화에서 고정된 양자화 단계가 신호 크기와 무관하게 일정한 분산을 부여하는 현상을 모델링한다.
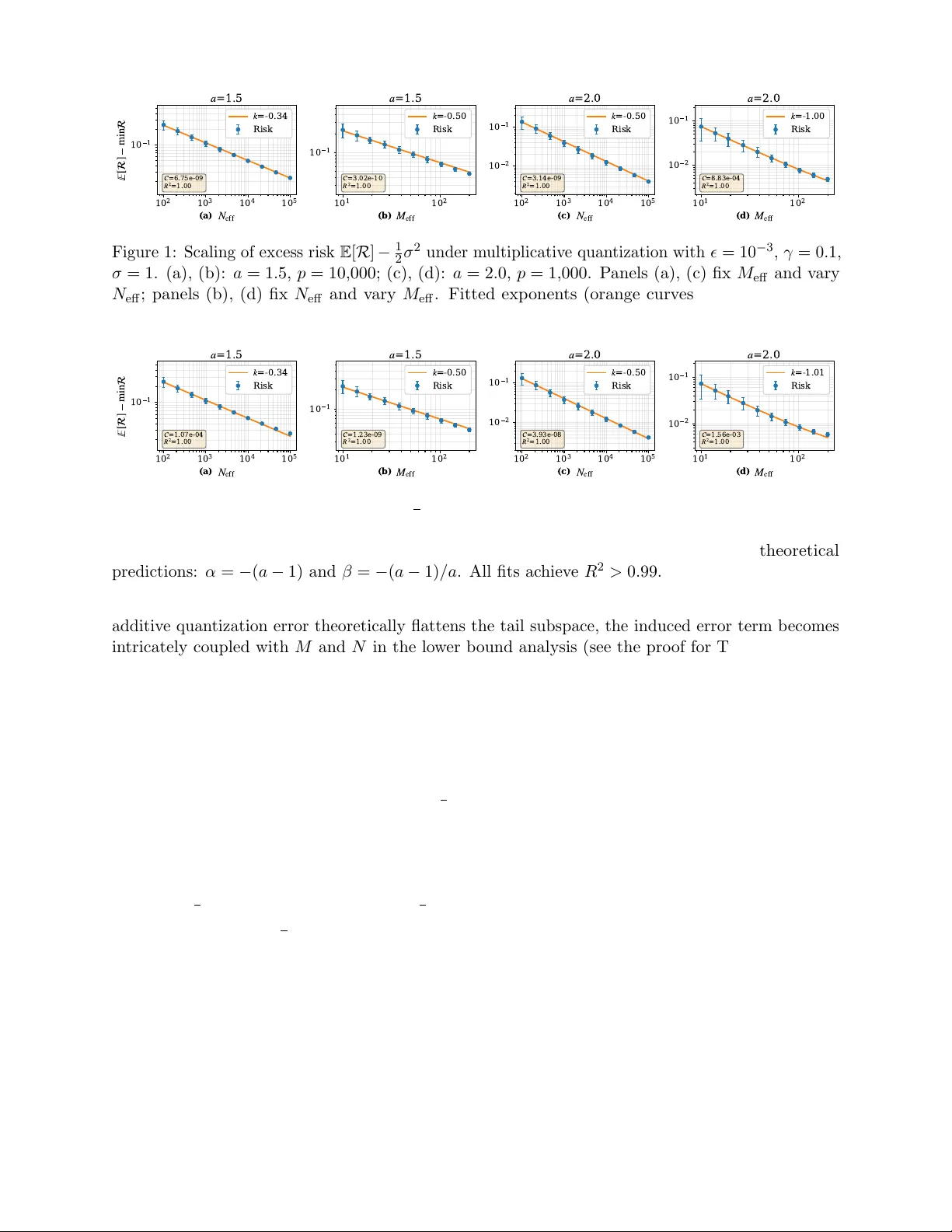
데이터 공분산 H는 파워‑로우 스펙트럼 λ_i∝i^{-a} (a>1)를 가정한다. 이는 실제 고차원 데이터가 저주파 성분에 에너지를 집중하는 현상을 수학적으로 포착한다. 이 스펙트럼 가정 하에, 논문은 위험(Risk) 상한을 다음과 같이 도출한다.
R_M(v_N) ≲ R* + 1/M_eff^{a-1} + 1/N_eff^{a-1} + δ(ε)
여기서 R*는 불가피한 최소 위험, ε는 양자화 오차, δ(ε)는 ε에 의존하는 추가 오류, M_eff와 N_eff는 각각 양자화에 의해 조정된 효과적 모델 크기와 데이터 크기이다.
핵심 결과는 두 양자화 방식이 M_eff와 N_eff에 미치는 영향이 다르다는 점이다.
- 곱셈 양자화: N_eff는 양자화 노이즈와 스펙트럼 왜곡에 의해 감소하지만, M_eff≈M을 유지한다. 즉, 모델 용량은 그대로이며, 성능 저하는 주로 데이터 효율성 감소에 기인한다.
- 덧셈 양자화: N_eff는 동일하게 감소하지만, 추가적으로 M_eff≈M·(1‑c·ε)와 같이 ε에 비례해 감소한다. 이는 정수 양자화가 모델 파라미터 자체의 표현력을 제한한다는 실험적 관찰을 이론적으로 설명한다.
정리 4.1·4.2는 위 상한을 정식으로 증명하고, 정리 4.3·4.4는 위험 하한을 제공한다. 하한은 ε>0인 경우 반드시 존재하는 최소 위험을 제시함으로써, 상한이 단순히 분석적 완화가 아니라 실제 최적 성능에 근접함을 보장한다.
실험 부분에서는 Gaussian 스케치를 사용해 M을 10³~10⁶, N을 10⁴~10⁷ 범위에서 다양한 스케일을 테스트하였다. 양자화 포맷으로는 FP8(E4M3)과 INT8을 각각 곱셈·덧셈 양자화에 매핑하였다. 결과는 이론적 예측과 일치한다. FP8에서는 M_eff가 유지되어 모델 파라미터 수가 감소하지 않음에도 불구하고, N_eff 감소에 따른 약간의 성능 저하만 관찰된다. 반면 INT8에서는 동일 비트폭에도 불구하고 M_eff가 눈에 띄게 감소해, 동일 데이터 양에서도 손실이 크게 증가한다.
논문의 의의는 다음과 같다. 첫째, 양자화 효과를 “효과적 데이터 크기 감소”와 “효과적 모델 크기 감소”라는 두 축으로 명확히 구분함으로써, 기존 경험적 스케일링 법칙을 이론적으로 통합한다. 둘째, 고차원 스케치 선형 회귀라는 모델을 통해 실제 딥러닝에서 관찰되는 과잉 파라미터 현상과 데이터 효율성 감소를 동시에 설명한다. 셋째, 정량적 위험 상·하한을 제공함으로써, 실무에서 비트폭 선택, 모델·데이터 규모 배분, 멀티패스 SGD 설계 등에 대한 구체적인 가이드라인을 제시한다.
결론적으로, 저정밀 훈련이 모델 용량을 유지하면서도 데이터 효율성을 감소시키는 경우(FP 양자화)와, 양쪽 모두를 감소시키는 경우(INT 양자화)를 명확히 구분함으로써, 향후 하드웨어 설계와 학습 전략 수립에 중요한 이론적 토대를 마련한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기