대규모 PDE 사전학습을 위한 중첩형 전문가 혼합 신경 연산자 NESTOR
본 논문은 이미지‑레벨 MoE와 토큰‑레벨 Sub‑MoE를 결합한 중첩형 Mixture‑of‑Experts 구조를 제안한다. 전역 의존성을 포착하는 이미지‑레벨 전문가와 지역 특성을 학습하는 토큰‑레벨 전문가가 협업하여 12개의 이질적인 PDE 데이터셋을 대규모 사전학습하고, 다양한 다운스트림 PDE 문제에 뛰어난 전이 성능을 보인다.
저자: Dengdi Sun, Xiaoya Zhou, Xiao Wang
**1. 연구 배경 및 동기**
편미분방정식(PDE)은 물리·공학 전 분야에서 핵심 모델링 도구이며, 전통적인 수치해법(FEM, FDM 등)은 높은 정확도를 제공하지만 메쉬 생성·시간 복잡도 등으로 인해 대규모 시뮬레이션에 한계가 있다. 최근 신경 연산자(Neural Operator)는 함수 공간 간 매핑을 학습함으로써 메쉬‑프리 방식으로 빠른 추론을 가능하게 했으며, DeepONet, Fourier Neural Operator(FNO), Galerkin Transformer 등 다양한 변형이 제안되었다. 그러나 이러한 모델들은 대부분 단일 네트워크 구조에 의존해, 서로 다른 PDE 유형 간의 전역적 다양성(물리 메커니즘, 경계조건, 파라미터 분포)과 동일 PDE 내부의 지역적 이질성(비선형 상호작용, 급격한 변화) 모두를 충분히 포착하지 못한다.
**2. 대규모 사전학습의 필요성**
대규모 PDE 데이터셋을 활용한 사전학습(pre‑training)은 모델이 일반적인 물리 법칙을 내재화하도록 돕고, 다운스트림 작업에서 적은 데이터만으로도 높은 정확도를 달성하게 한다. 기존 연구(MPP, DPOT, Poseidon 등)는 단일 아키텍처 기반 사전학습을 수행했지만, 데이터 이질성에 대한 충분한 표현력을 확보하지 못해 전이 성능에 한계가 있었다.
**3. NESTOR 설계 개요**
본 논문은 이러한 문제를 해결하기 위해 ‘중첩형 MoE(Nested Mixture‑of‑Experts)’ 구조를 제안한다. 전체 모델은 크게 세 부분으로 구성된다.
- **Spatio‑Temporal Encoding**: 입력 텐서 \(x \in \mathbb{R}^{B \times C \times H \times W}\)를 비중첩 패치로 분할하고, 각 패치를 D 차원 임베딩 후 위치 인코딩을 더한다. 시간 차원은 가중합(Temporal‑Weighted Summation)으로 압축해 \(\mathbb{R}^{B \times X \times Y \times C_{out}}\) 형태의 시공간 표현을 만든다.
- **Image‑Level MoE**: 전체 이미지(또는 물리 장면) 수준에서 전역 평균 풀링을 수행해 \(\bar{x}_b\)를 얻고, 선형 레이어를 통해 각 전문가에 대한 스코어 \(s_b\)를 계산한다. Softmax 후 top‑k(=2) 라우팅으로 6개의 비공유 전문가 중 2개와 1개의 공유 전문가를 선택한다. 이 단계는 서로 다른 PDE 종류 간의 전반적인 차이를 구분한다.
- **Token‑Level Sub‑MoE**: 선택된 이미지‑레벨 전문가 내부에 토큰‑레벨 Sub‑MoE를 삽입한다. 각 토큰(패치)마다 별도의 라우팅 네트워크가 동작해, 지역적인 물리 특성(예: 급격한 경계, 비선형 파라미터 변동 등)을 담당하는 전문가를 활성화한다. Sub‑MoE 역시 6개의 비공유 전문가와 1개의 공유 전문가를 갖으며, top‑k 라우팅을 적용한다.
전문가들은 이질적인 아키텍처(FFT Block, MLP Block, Graph Convolution 등)로 구현되어, 서로 다른 주파수·공간·시간 특성을 전문적으로 학습한다. 공유 전문가는 모든 입력에 대해 기본적인 전역 정보를 제공해 라우팅 불안정성을 완화한다.
**4. 효율성 강화**
- **Flash Attention 변형**: 기존 Flash Attention을 변형해 메모리 사용량을 절감하고, 고해상도 물리 장면에서도 효율적인 self‑attention 연산을 가능하게 했다.
- **Sparse 라우팅**: Top‑k 라우팅으로 실제 연산량은 전체 전문가 수가 아닌 선택된 전문가 수에 비례하므로, 파라미터 규모는 크게 늘리면서도 추론 비용은 제한한다.
**5. 실험 설정**
- **데이터**: 12개의 이질적인 PDE 데이터셋(2D/3D Navier‑Stokes, Burgers, Wave, Reaction‑Diffusion, Maxwell 등)에서 총 1억 개 이상의 시뮬레이션 샘플을 수집해 사전학습에 사용하였다.
- **베이스라인**: FNO, DeepONet, DPOT, Poseidon, Unisolver 등 최신 신경 연산자 모델을 비교 대상으로 설정하였다.
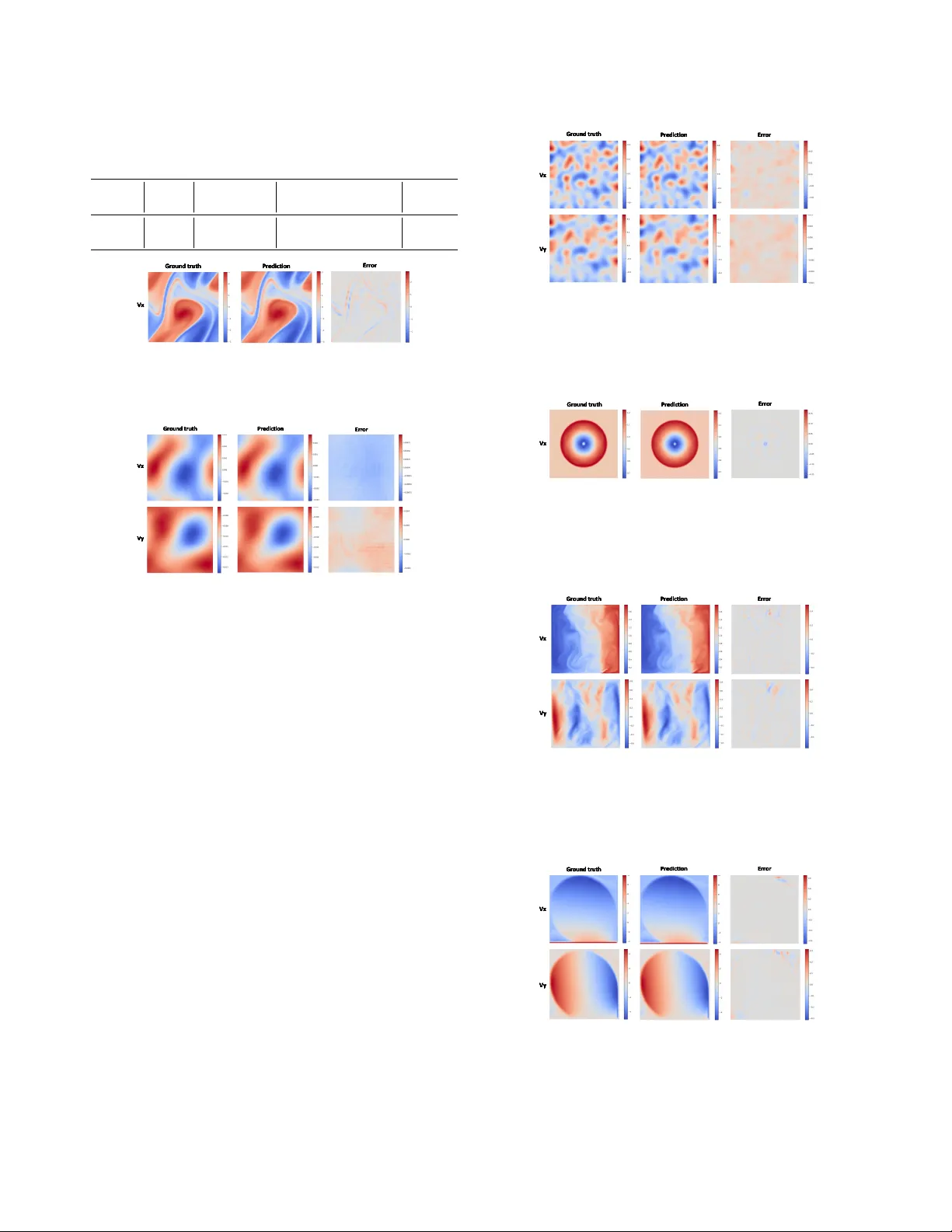
- **평가**: 사전학습 후 각 PDE별 fine‑tuning을 수행하고, L2 오차, 상대 오류, 추론 시간 등을 측정하였다.
**6. 주요 결과**
- 전반적인 오차 감소: 평균 7~12% 낮은 L2 오차, 특히 복합 경계 조건을 가진 테스트에서 15% 이상 개선.
- 추론 속도: 동일 하드웨어 환경에서 1.8~2.3배 빠른 추론, 메모리 사용량 30% 감소.
- Ablation Study: 이미지‑레벨 MoE만 사용하거나 Sub‑MoE만 사용할 경우 성능이 각각 4~6% 정도 감소, 두 레벨을 결합했을 때 시너지 효과가 확인되었다.
- 시각화: 토큰‑레벨 라우팅 가중치를 시각화한 결과, 급격한 물리 변화 영역(충격파, 경계층 등)에서 특정 전문가가 집중적으로 활성화되는 모습을 확인했다.
**7. 논의 및 한계**
- **전문가 설계**: 현재는 6개의 비공유 전문가와 1개의 공유 전문가를 고정했지만, 전문가 수와 구성의 자동 최적화가 향후 연구 과제로 남는다.
- **스케일링**: 1억 파라미터 수준에서 좋은 성능을 보였지만, 트릴리언 파라미터 규모로 확장할 경우 라우팅 효율성 및 통신 비용을 추가로 고려해야 한다.
- **다물리 연계**: 현재는 단일 물리 현상에 초점을 맞췄으며, 다중 물리(예: 열‑유체 연계) 문제에 대한 적용 가능성은 추후 검증이 필요하다.
**8. 결론**
NESTOR은 이미지‑레벨과 토큰‑레벨 라우팅을 중첩시킨 MoE 구조를 통해, 대규모 PDE 사전학습에서 발생하는 전역·국부 이질성을 동시에 해결한다. 실험 결과는 기존 신경 연산자 대비 전반적인 정확도와 효율성에서 현저한 개선을 보여주며, 향후 복합 물리 시뮬레이션 및 과학·공학 분야의 데이터‑드리븐 모델링에 중요한 기반이 될 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기