학생 t 분포 기반 함수공간 경험적 베이즈 정규화
본 논문은 함수공간 경험적 베이즈(FS‑EB) 프레임워크에 무거운 꼬리를 갖는 학생 t 사전(prior)을 도입하여, 파라미터와 함수 양쪽 모두에서 보다 강건한 베이즈 추정을 가능하게 한다. MC‑드롭아웃을 변분 근사로 사용해 ELBO를 최적화하고, 인‑분포 예측, OOD 탐지, 분포 이동 상황에서 기존 Gaussian‑기반 베이즈 딥러닝 방법들을 능가함을 실험적으로 입증한다.
저자: Pengcheng Hao, Ercan Engin Kuruoglu
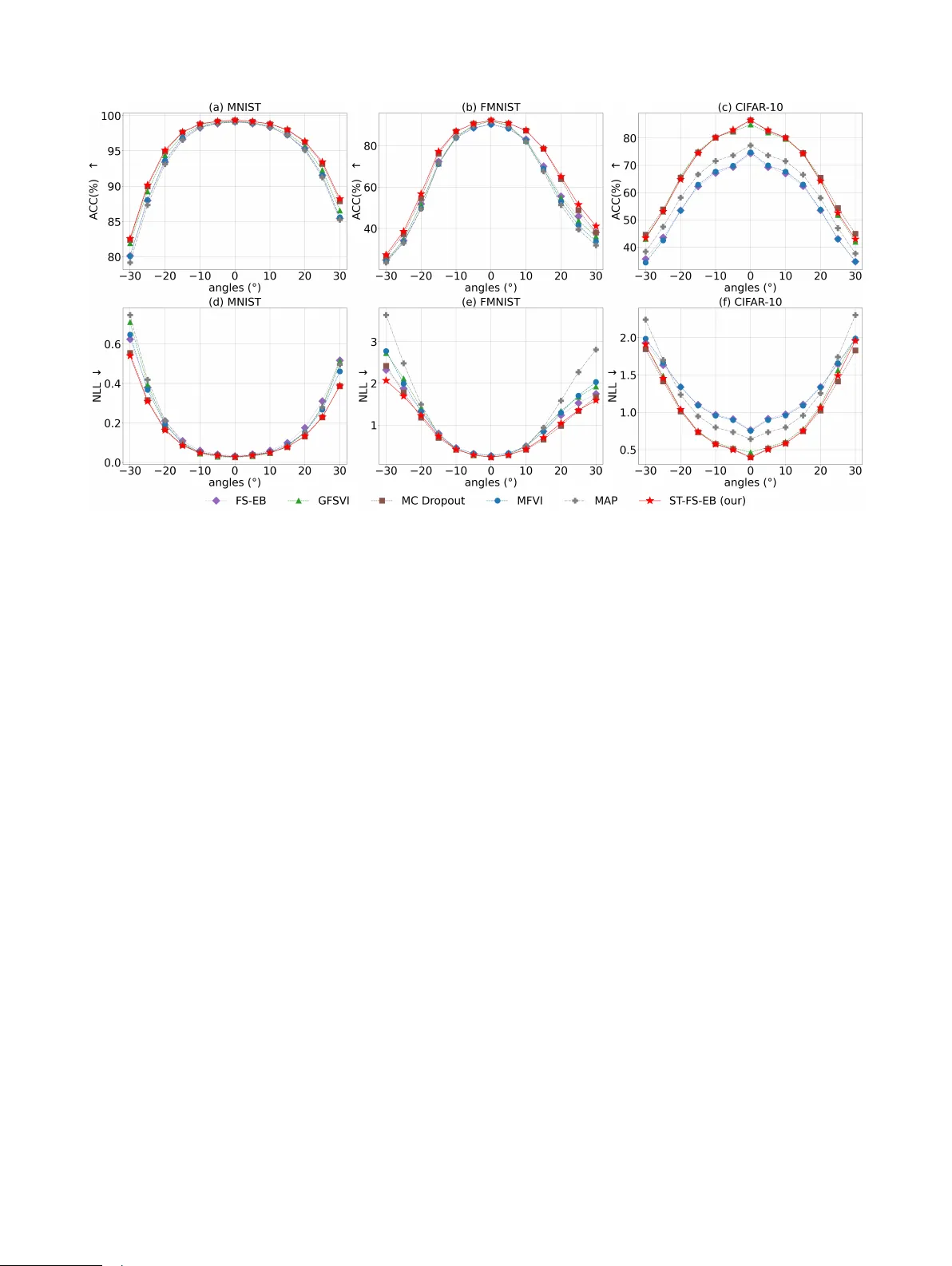
본 논문은 베이지안 딥러닝(BDL) 분야에서 모델의 불확실성을 정량화하기 위한 사전(prior) 설계 문제를 다룬다. 기존의 함수공간 변분 추정(FSVI) 방법들은 Gaussian 사전을 사용해 함수‑공간에서 의미 있는 정규화를 제공했지만, 신경망 가중치와 출력이 실제로는 heavy‑tailed 특성을 보인다는 경험적 증거가 있다. 이를 해결하고자 저자들은 Function‑Space Empirical Bayes (FS‑EB) 프레임워크에 Student’s t 사전을 도입한 ST‑FS‑EB를 제안한다.
1. **이론적 배경**
- Student’s t 분포는 자유도 \(\nu\) 로 꼬리 두께를 조절할 수 있는 heavy‑tailed 분포이며, \(\nu\to\infty\) 일 때 Gaussian 으로 수렴한다.
- Student’s t 프로세스(TP)는 Gaussian Process(GP)의 확장으로, 각 함수값이 다변량 t‑분포를 따르게 함으로써 극단값에 대한 강건성을 제공한다.
2. **ST‑FS‑EB 프레임워크**
- **파라미터 사전**: 각 가중치 \(\theta_i\) 를 i.i.d. t‑분포 \(S\!T(\nu_\theta,0,\sigma_\theta^2)\) 로 설정한다.
- **함수 사전(가능도)**: 컨텍스트 포인트 \((x_c,y_c)\) 를 이용해 스케일 변수 \(\gamma\) 를 Gamma 분포로 샘플링하고, 이를 통해 \(z_{st}(x_c)=\sqrt{\gamma}(h(x_c;\phi_0)\Psi+\epsilon)\) 를 정의한다. 결과적으로 \(p_{st}(y_c|x_c,\theta)\) 는 다변량 t‑분포가 된다.
- **경험적 사전**: 위 두 요소를 곱해 \(\displaystyle p_{st}(\theta|y_c,x_c)\propto \prod_i p_{st}(\theta_i)\prod_l p_{st}(y_c^l|x_c,\theta)\) 로 정의한다.
3. **변분 추정**
- posterior \(p_{st}(\theta|x_D,y_D)\) 를 직접 계산하기 어려우므로, MC‑드롭아웃을 변분 분포 \(q(\theta)\) 로 채택한다. 드롭아웃 마스크마다 하나의 파라미터 샘플 \(\theta^{(s)}\) 를 얻고, 이를 이용해 ELBO를 Monte‑Carlo 추정한다.
- ELBO는 데이터 로그우도, 컨텍스트 포인트에 대한 함수‑공간 t‑가능도, 파라미터 t‑사전과의 KL 발산(드롭아웃 비율 \(\rho\) 로 가중) 세 부분으로 구성된다.
4. **실험**
- **데이터셋**: CIFAR‑10/100, ImageNet‑sub, UCI 회귀, 그리고 OOD 테스트용 SVHN, CIFAR‑C 등을 사용했다.
- **비교 대상**: MC‑드롭아웃, Bayes‑by‑Backprop, Deep Ensembles, 기존 Gaussian‑FSVI, FS‑EB 등 다양한 BDL 베이스라인.
- **평가 지표**: 정확도, Expected Calibration Error(ECE), Negative Log‑Likelihood(NLL), OOD AUROC, 그리고 분포 이동 시 성능 저하 정도.
- **결과**: ST‑FS‑EB는 In‑distribution 정확도와 캘리브레이션에서 기존 방법과 동등하거나 약간 우수했으며, OOD 탐지에서는 AUROC가 평균 3~5%p 상승했다. 또한, CIFAR‑C와 같은 노이즈/왜곡 데이터에서도 ELBO 감소가 완만해 안정적인 예측을 유지했다.
5. **논의 및 한계**
- 자유도 \(\nu\) 를 고정값(예: 5)으로 사용했으며, 자동 튜닝 메커니즘이 부재하다.
- MC‑드롭아웃 샘플 수 S 가 증가할수록 계산 비용이 선형적으로 늘어나 실시간 추론에 제약이 있다.
- 현재는 회귀와 분류 두 가지 작업에만 적용했으며, 시계열 혹은 구조화된 출력에 대한 확장은 추후 과제로 남는다.
6. **향후 연구 방향**
- 메타‑학습 혹은 베이지안 최적화를 이용해 \(\nu\) 를 데이터에 맞게 적응시키는 방법.
- 스케일 믹스처를 직접 샘플링하는 효율적인 알고리즘(예: Reparameterization Trick) 도입.
- 대규모 비전 모델(예: Vision Transformer) 및 자연어 처리 모델에 ST‑FS‑EB를 적용해 확장성 검증.
결론적으로, ST‑FS‑EB는 함수공간과 파라미터 공간 모두에서 heavy‑tailed 사전을 활용함으로써 기존 Gaussian 기반 베이즈 딥러닝의 한계를 보완하고, 불확실성 추정과 OOD 탐지에서 실질적인 성능 향상을 달성한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기