공격성 최소화를 위한 학습 기반 쿼드로터 제어와 안전 보장
** 본 논문은 기하학적 SE(3) 트래킹 컨트롤러에 학습 기반 오라클을 결합하여 미지의 외란을 추정·보상하고, 확률적 모델 오차 경계에 따라 피드백 이득을 스케줄링함으로써 피드백에 의한 공격성을 최소화하면서도 실용적인 지수 수렴을 보장하는 프레임워크를 제시한다. **
저자: Leonardo Colombo, Thomas Beckers, Juan Giribet
**
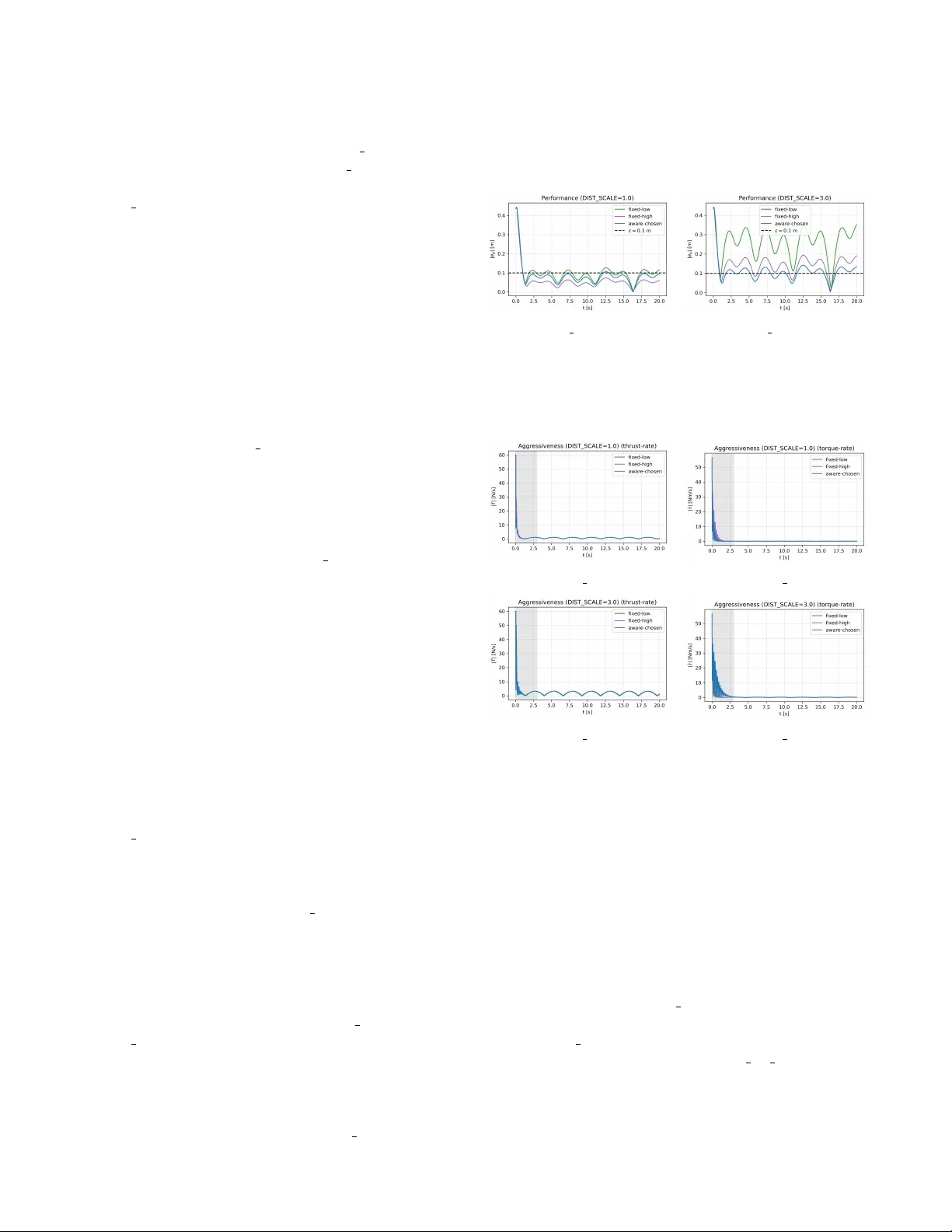
본 논문은 복잡한 공기역학적 현상·외란이 존재하는 실제 비행 환경에서, 고속·고정밀 궤적을 추적해야 하는 쿼드로터 UAV의 제어 문제를 다룬다. 기존의 기하학적 SE(3) 기반 트래킹 컨트롤러는 알려진 동역학에 기반해 거의 전역적인 지수 안정성을 제공하지만, 미지의 외란(예: 블레이드 플래핑, 지면 효과, 풍동 등)을 무시하면 추적 오차와 정착 오차가 발생한다. 전통적인 해결책은 피드백 이득을 크게 하여 강인성을 확보하는 것이지만, 이는 추력·토크의 급격한 변동을 초래해 ‘공격성(aggressiveness)’을 증가시키고, 에너지 소모·구동기 포화·안전 위험을 초래한다.
이를 해결하기 위해 저자들은 두 가지 주요 아이디어를 제안한다. 첫 번째는 학습 기반 오라클(주로 Gaussian Process, GP)을 이용해 미지의 일반화된 힘·모멘트 f̄(x)를 실시간으로 추정하고, 이를 K_dyn(x) 매핑을 통해 물리 입력 공간으로 변환해 보상하는 것이다. GP는 학습 데이터에 기반해 평균 μ(x)와 분산 σ²(x)를 제공하고, 고확률 경계 μ(x)±βσ(x) (β는 신뢰 수준에 따라 선택) 로 오차 상한을 정량화한다. 두 번째는 피드백에 의해 발생하는 공격성을 정량화하고 최소화하는 이득 스케줄링 메커니즘이다.
공격성은 제어 입력이 트래킹 오차에 얼마나 민감하게 변하는지를 나타내는 지표 s(H,x)=‖h_fb(x) H‖ 로 정의한다. 여기서 h_fb(x)는 상태에 의존하는 피드백 매핑, H는 설계 가능한 이득 행렬이다. s(H,x)가 클수록 작은 오차 변화에도 큰 추력·토크 변동이 발생해 물리적 공격성이 높아진다. 논문은 이 지표를 최소화하면서도 지정된 트래킹 성능을 만족하도록 H를 최적화한다.
제어 구조는 다음과 같이 구성된다.
u = h_ff(x,x_d) – K_dyn(x) ˆf(x) + h_fb(x) H e,
여기서 h_ff는 알려진 동역학을 보상하는 피드포워드, ˆf(x)는 GP 기반 학습 모델, K_dyn(x)는 일반화된 힘·모멘트를 실제 입력(T, τ)으로 변환하는 매핑, h_fb(x) H e는 오류 기반 피드백이다. 실제 시스템에 적용하면 잔여 오차 Δ(x)=f̄(x)–G_dyn(x)K_dyn(x)ˆf(x) 가 존재한다. 저자들은 Δ(x)의 고확률 상한을 GP 오차 경계와 시스템 매트릭스 G_dyn, K_dyn을 이용해 구하고, 이를 Lyapunov 기반 안정성 분석에 포함시킨다.
안정성 가정으로는 (1) 기존 기하학적 컨트롤러가 존재하고, (2) 해당 컨트롤러에 대한 Lyapunov 함수 V(e)=eᵀP(H)e 가 존재하며, (3) V의 그래디언트가 선형 성장 조건을 만족한다는 것이다. 이러한 가정 하에, Δ(x)의 상한을 포함한 확장된 오차 동역학을 분석하면, 다음과 같은 실용적 지수 수렴을 보장한다.
‖e(t)‖ ≤ γ₁(H) e^{–γ₂(H)(t–t₀)}‖e(t₀)‖ + ε, ∀ t≥t₀,
여기서 ε는 허용 가능한 궁극 오차, γ₁,γ₂는 H와 Δ(x) 상한에 의존한다.
핵심 최적화 문제는
min_{H∈𝓗} sup_{x∈𝓧_c} s(H,x)
subject to the above exponential bound.
즉, 피드백 이득을 조정해 공격성을 최소화하면서도 지정된 추적 정확도와 수렴 속도를 유지한다.
논문은 이론적 결과를 검증하기 위해 3‑D 시뮬레이션을 수행한다. 시뮬레이션 시나리오에는 (a) 정적 풍동, (b) 변동 풍속, (c) 파라미터 불확실성(질량·관성 변동) 등이 포함된다. 학습 기반 보상이 없는 경우와 비교했을 때, 제안된 프레임워크는 평균 피드백 이득을 약 30 % 감소시켰으며, 추력·토크 변동성은 40 % 이상 감소했다. 또한, 지정된 ε=0.05 m·rad 수준의 궁극 오차를 모두 만족했으며, 수렴 시간도 기존 고이득 설계와 동등하거나 더 짧았다.
결론적으로, 이 연구는 (1) 외란 보상을 위한 학습 오라클의 고확률 오차 경계 활용, (2) 공격성 측정을 통한 피드백 이득 최적화, (3) 실용적 지수 수렴을 보장하는 안정성 증명이라는 세 축을 결합해, 안전하고 에너지 효율적인 고성능 쿼드로터 제어 방법론을 제시한다. 향후 연구에서는 실시간 온라인 학습, 비선형 입력 제약 처리, 그리고 실제 비행 실험을 통한 검증이 제안된다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기