신뢰성 높은 신장 기증 폐기 예측을 위한 머신러닝 모델 비교 연구
본 연구는 독일 4,080명의 사망 기증자를 대상으로, 표준화된 전처리·특징 선택·베이지안 하이퍼파라미터 최적화를 적용한 다섯 가지 머신러닝 모델(로지스틱 회귀, 결정 트리, 랜덤 포레스트, 그래디언트 부스팅, 딥러닝)과 앙상블을 비교한다. 모델 성능은 MCC, AUC, F1 점수 등 판별력, Brier 점수 등 보정력, SHAP 기반 설명력을 기준으로 평가하였다. 앙상블이 가장 높은 MCC 0.76·AUC 0.87·F1 0.90을 기록했으며,…
저자: Peer Schliephacke, Hannah Schult, Leon Mizera
본 논문은 “신장 기증 폐기 예측을 위한 머신러닝 모델 비교 평가”라는 주제로, 기존 연구들이 데이터셋·특징 선택·평가 방법의 이질성으로 인해 모델 성능을 직접 비교하기 어려웠던 문제를 해결하고자 한다. 연구팀은 독일 전역의 사망 기증자 4,080명을 대상으로, 기증자 수준에서 폐기 여부(22.8% 폐기, 77.2% 이식)를 라벨링한 대규모 데이터베이스를 구축했다. 변수는 총 1,128개이며, 여기에는 연령·성별·신체계측·혈액·소변·생리학적 파라미터·약물 투여·ICD‑10 진단 코드 등 다양한 형태가 포함돼 있었다.
데이터 전처리와 특징 엔지니어링은 논문의 핵심 절차다. 시간에 따라 측정된 49개의 실험실 변수는 “첫값·마지막값·관측 횟수·시간 간격·최소·최대·표준편차·선형 추세(β0, β1)” 등 8가지 파생 특징으로 변환돼 364개의 시계열 특징을 생성했다. 약물 데이터는 1,772개의 원시 명칭을 첫 단어 기준으로 1,103개로 축소하고, 가장 빈번한 40개 약물을 선택해 이진 변수(투여 여부)로 전환했다. 범주형 변수는 원‑핫 인코딩을 적용했으며, 1% 이하 빈도 코드는 결측치로 처리했다. 결측치 처리 전략은 다층적이었다. 논리적 규칙에 따라 부정적인 진단을 0으로 대체하고, 일부 범주형 변수는 별도 ‘결측’ 카테고리를 부여했으며, 연속형 변수는 중앙 95% 구간 내 정규분포 샘플링으로 보완했다. 고결측(>70%) 변수는 이진화하고, 나머지 328개 변수는 리지 회귀 기반 반복 임퓨테이션(IterativeImputer)으로 채웠다. 이 전략은 HistGradientBoosting의 내장 임퓨테이션보다 F1·MCC 점수에서 우수함을 검증했다.
모델링 단계에서는 로지스틱 회귀(LR), 결정 트리(DT), 랜덤 포레스트(RF), 그래디언트 부스팅(GB), 딥러닝(DL) 5가지 기본 모델을 구축하고, 이들의 예측을 평균한 스태킹 앙상블을 추가했다. 각 모델은 베이지안 최적화(베이스라인은 5‑fold 교차 검증)로 하이퍼파라미터를 탐색했으며, 훈련·검증·테스트 데이터를 기증자 ID 기준으로 80% 훈련, 10% 검증, 10% 테스트로 분리해 데이터 누수를 방지했다.
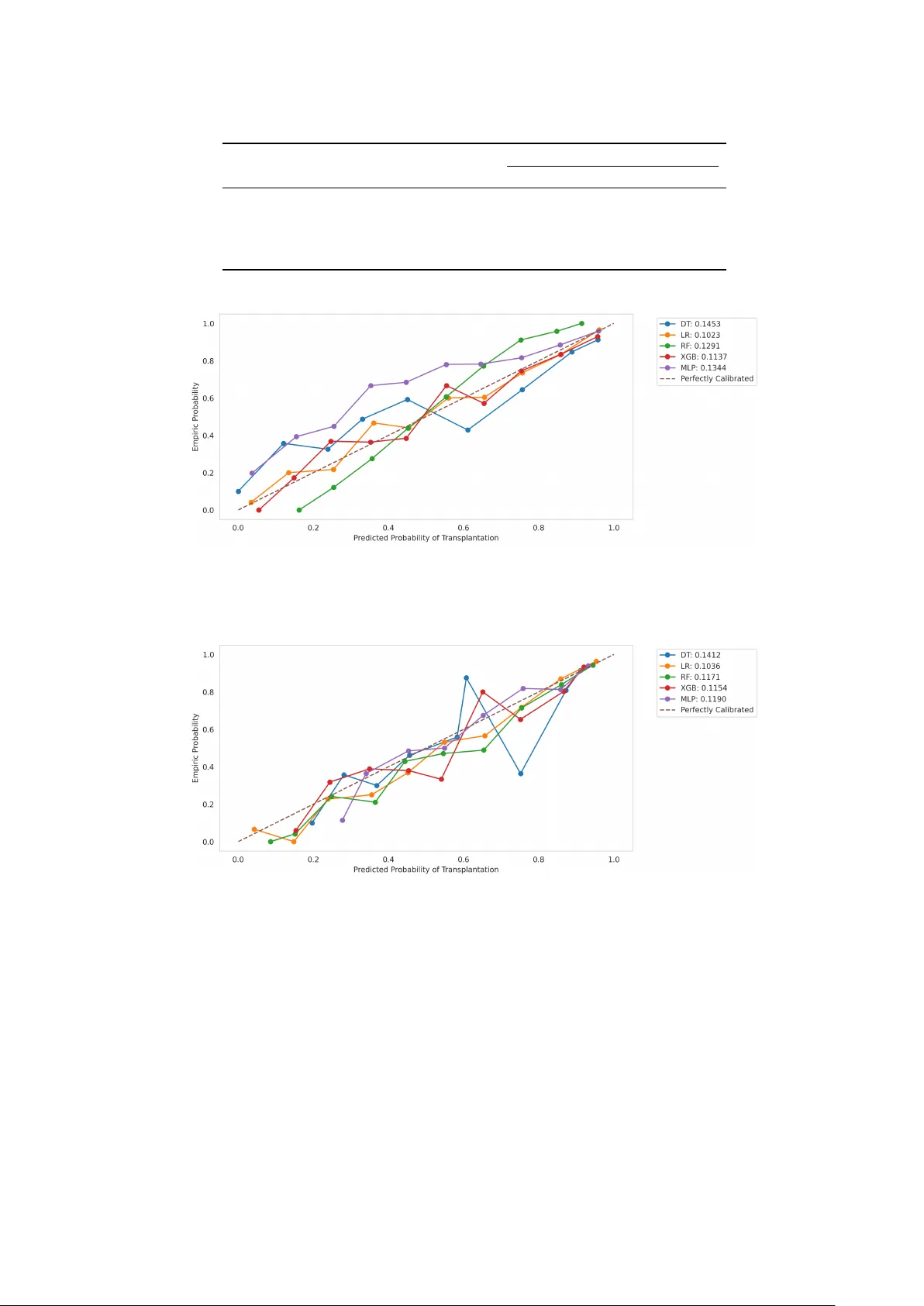
성능 평가는 세 축으로 이루어졌다. 판별력은 MCC(매튜스 상관계수), AUC(ROC 곡선 아래 면적), F1 점수로 측정했으며, 보정력은 Brier 점수(예측 확률과 실제 라벨 간 제곱 오차)로 평가했다. 설명력은 SHAP(Shapley Additive exPlanations) 값을 통해 각 변수의 기여도를 시각화했다.
주요 결과는 다음과 같다. 앙상블 모델이 MCC 0.76·AUC 0.87·F1 0.90으로 가장 높은 판별력을 보였으며, 개별 모델 중 LR( MCC 0.73·AUC 0.85·F1 0.88), RF( MCC 0.74·AUC 0.86·F1 0.89), DL( MCC 0.72·AUC 0.84·F1 0.87)도 경쟁력 있었다. 반면 DT는 MCC 0.58·AUC 0.73·F1 0.75로 상대적으로 낮았다. 보정 측면에서는 트리 기반 모델과 신경망 모델에 플랫 스케일링(Platt scaling)을 적용했을 때 Brier 점수가 평균 0.12에서 0.07로 감소해 확률 예측의 신뢰성이 크게 향상되었다. SHAP 분석에서는 기증자 연령, eGFR(MDRD), 혈청 크레아티닌, 요량, 혈압, 특정 약물(헤파린류 등) 투여 여부가 가장 큰 양의 혹은 음의 영향을 미쳤으며, 이는 기존 임상 연구에서 제시된 위험 요인과 일치했다.
논문은 또한 한계점과 향후 과제를 제시한다. 첫째, 데이터는 독일 단일 국가에 국한돼 있어 국제적 일반화 검증이 필요하다. 둘째, 수집된 변수 중 일부는 임상 현장에서 실시간으로 확보하기 어려운 경우가 있어, 실용적인 모델 구축을 위해 변수 선택을 더 압축할 여지가 있다. 셋째, 현재는 이진 폐기 여부만을 예측했지만, 폐기 원인(생물학적·운영적)별 세분화가 향후 연구에 도움이 될 것이다. 마지막으로, 모델을 실제 임상 의사결정 지원 시스템에 통합하려면, 실시간 데이터 파이프라인과 사용자 친화적인 인터페이스 설계가 필요하다.
결론적으로, 저자들은 “데이터 전처리·특징 엔지니어링·하이퍼파라미터 최적화·보정·설명 가능성”이라는 전 과정을 표준화함으로써, 알고리즘 자체보다 전체 파이프라인이 예측 성공에 더 큰 영향을 미친다는 중요한 교훈을 제시한다. 또한, 전체 코드와 파이프라인을 오픈소스로 제공해 재현성을 확보했으며, 이는 향후 다기관·다국가 연구와 실제 임상 적용을 위한 기반이 된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기