ML 부하 흐름 대리 모델의 학습 데이터 크기 영향 분석
본 논문은 전력 시스템 운영의 핵심인 부하 흐름 계산을 머신러닝으로 근사화하는 연구에서, 학습 데이터셋의 크기가 모델 성능에 미치는 영향을 체계적으로 분석합니다. 고정된 IEEE 5-버스 시스템 토폴로지에서 다층 퍼셉트론(MLP)과 두 가지 변종 그래프 신경망(GNN)의 샘플 효율성을 비교한 결과, GNN이 가장 낮은 오차를 기록했으나, 아키텍처 선택보다 대규모 학습 데이터의 가용성이 성능에 더 지배적인 요인임을 확인했습니다.
저자: Timon Conrad, Changhun Kim, Johann Jäger
본 논문은 전력 시스템의 핵심 연산인 AC 부하 흐름 계산을 머신러닝을 통해 고속으로 근사화하는 대리 모델의 성능에 학습 데이터셋의 크기가 미치는 영향을 분석합니다. 전통적인 Newton-Raphson 알고리즘은 정확하지만 계산 부하가 커 대규모 시나리오 분석이나 실시간 최적화에 적용하기 어려운 단점이 있습니다. 머신러닝, 특히 그래프 신경망(GNN)은 이러한 계산 부담을 줄이면서 높은 정확도를 보일 수 있으나, 모델을 학습시키기 위해 필요한 데이터의 양(샘플 효율성)에 대한 연구는 부족한 상황입니다. 이 연구는 특히 시스템 토폴로지가 고정된 상황에서 이 문제를 체계적으로 탐구합니다.
연구는 수정된 IEEE 5-버스 시스템을 기반으로 생성된 789,000개의 부하 흐름 사례 데이터셋을 사용합니다. 데이터는 DIgSILENT PowerFactory를 이용해 생성되었으며, PV 버스의 유효 전력과 PQ 버스의 유효/무효 전력 수요를 물리적 한계 내에서 무작위로 변화시켜 만들었습니다.
분석에는 세 가지 신경망 아키텍처가 사용되었습니다. 첫째, **다층 퍼셉트론(MLP)** 은 기준 모델로, 모든 버스의 특징을 평탄화한 벡터를 입력받아 모든 버스의 출력을 한 번에 예측합니다. 둘째, **그래프 신경망(GNN)** 두 변종입니다. 두 GNN 모두 전력망을 그래프(버스=노드, 선로=에지)로 모델링하고, 버스 유형(Slack, PV, PQ)에 따라 다른 임베딩 함수를 적용한 후, 어드미턴스 행렬로 정의된 인접 행렬을 통해 메시지 패싱을 수행합니다. 두 GNN의 차이는 디코딩 방식에 있습니다: **GNN1**은 모든 버스의 최종 상태를 평균 풀링한 후 하나의 전역 디코더를 통해 출력을 예측하는 반면, **GNN2**는 각 버스의 상태를 버스 유형별 디코더를 통해 개별적으로 예측합니다.
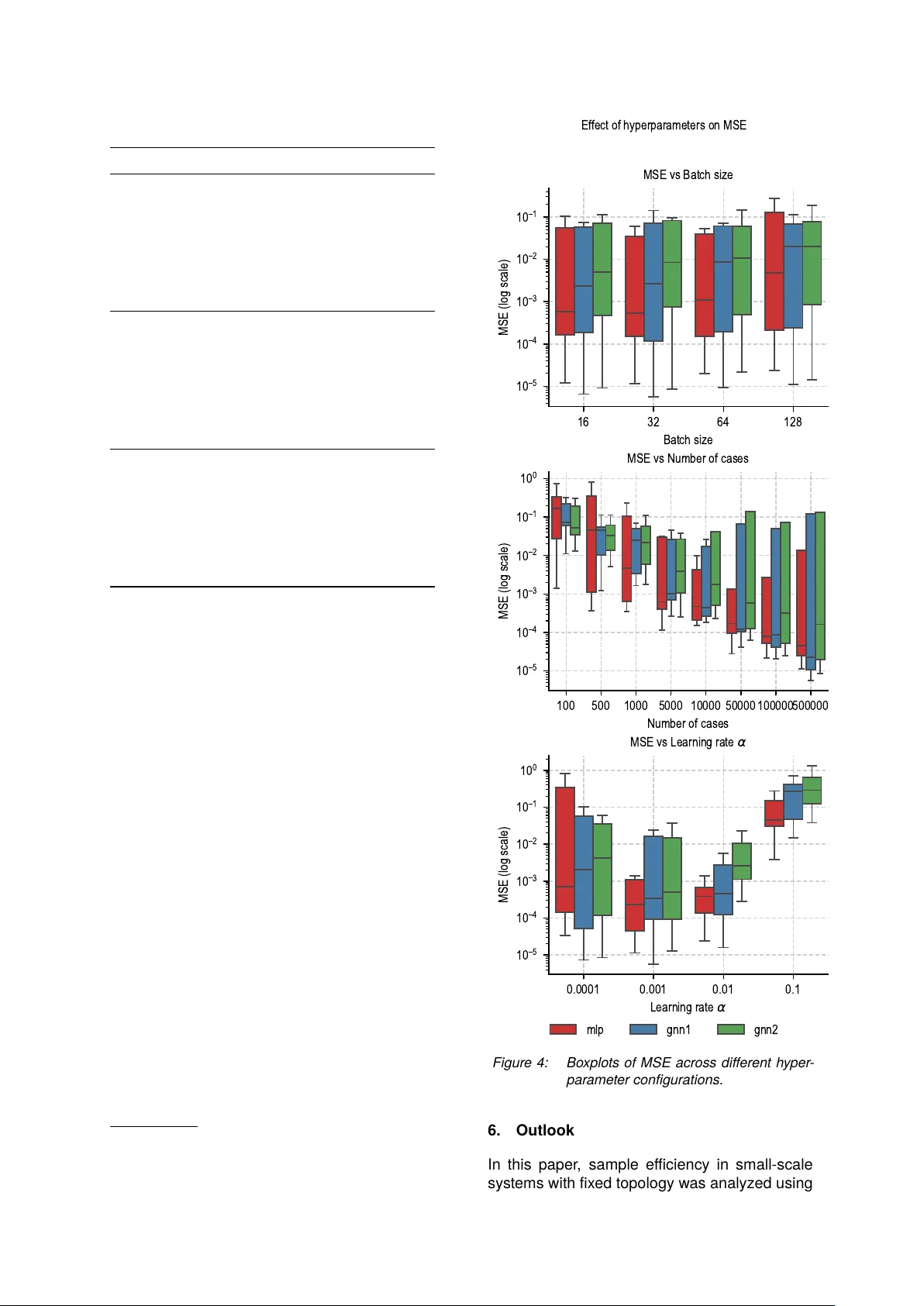
실험은 학습 데이터 크기(500 ~ 500,000 샘플), 배치 크기(16, 32, 64, 128), 학습률(0.0001 ~ 0.1)을 변수로 하여 진행되었습니다. 모든 모델은 평균 제곱 오차(MSE)를 손실 함수로 사용해 50 에포크 동안 학습되었습니다.
주요 결과는 다음과 같습니다.
1. **성능 순위**: 최종 테스트 오차(MSE)는 GNN1(5.65e-6)이 가장 낮았고, 그 다음으로 GNN2(8.51e-6), MLP(1.14e-5) 순이었습니다. 따라서 그래프 구조를 명시적으로 활용한 GNN1이 가장 정확한 모델임을 확인했습니다.
2. **가장 영향력 큰 요소**: 그림 4의 박스플롯이 명확히 보여주듯, 모델 아키텍처보다 **학습 데이터셋의 크기**가 성능에 훨씬 더 지배적인 영향을 미쳤습니다. 데이터가 증가할수록 모든 모델의 오차가 크게 감소하고 결과의 분산도 줄어들었습니다.
3. **하이퍼파라미터 영향**: 배치 크기는 성능에 미미한 영향을 미쳤습니다. 학습률은 GNN2의 성능 안정성에만 상관관계를 보였으며, MLP와 GNN1에서는 명확한 경향이 관찰되지 않았습니다.
4. **추론 속도**: 그림 5에 따르면, 추론 시간은 MLP가 압도적으로 빠르며(10,000 샘플 처리 시 0.35초 미만), GNN1(34.6초), GNN2(38.3초) 순입니다. 전통적인 Newton-Raphson 솔버(142.5초)와 비교하면 MLP는 수백 배, GNN은 약 4배 빠른 속도를 보입니다.
논문은 결론적으로, 소규모 고정 토폴로지 시스템에서도 GNN이 MLP보다 더 나은 정확도를 달성할 수 있음을 보였지만, 궁극적인 성능을 좌우하는 요소는 아키텍처 자체보다는 충분히 큰 규모의 학습 데이터셋의 가용성임을 강조합니다. 또한 MLP가 매우 빠른 추론 속도를 제공한다는 점에서 실시간 응용 프로그램에 유리할 수 있음을 지적합니다. 마지막으로, 데이터 의존성을 완화하기 위해 물리 법칙을 손실 함수에 통합하는 물리 정보 기반 학습(Physics-Informed Learning)을 향후 연구 방향으로 제안하며, 이는 더 큰 규모의 전력망으로 연구를 확장할 때 GNN의 구조적 장점이 더욱 중요해질 것이라고 전망합니다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기