신용 위험 로지스틱 회귀에서 클래스 불균형이 미치는 영향
본 논문은 저발생(저디폴트) 포트폴리오에서 흔히 나타나는 클래스 불균형이 로지스틱 회귀 모델의 분류 정확도와 최적 임계값에 미치는 영향을 시뮬레이션을 통해 체계적으로 분석한다. 사건 비율이 낮아질수록 정확도는 급격히 감소하지만, Gini 계수는 충분히 큰 표본에서는 안정적임을 확인한다. 또한, 예측 변수들의 정보값(IV)과 이를 집계한 AIV 개념을 도입해 신호‑대‑노이즈 비율을 정량화하고, 실무 적용 시 사건 비율과 변수 연관 강도에 따른 기…
저자: Willem D. Schutte, Charl Pretorius, Neill Smit
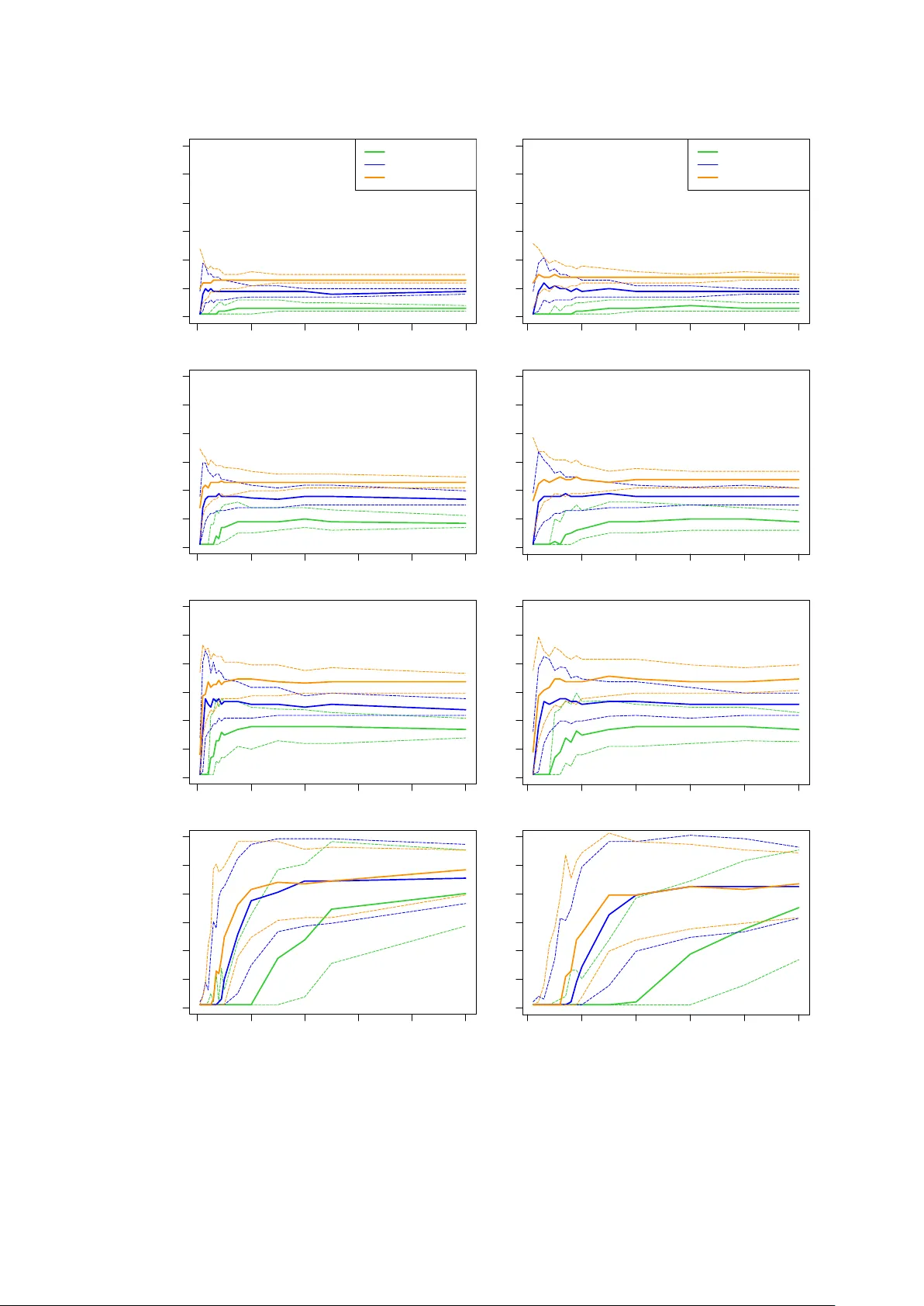
본 논문은 저디폴트 신용 포트폴리오, 즉 사건(디폴트) 발생 빈도가 극히 낮은 데이터셋에서 흔히 나타나는 클래스 불균형이 로지스틱 회귀 모델의 성능에 미치는 영향을 체계적으로 탐구한다. 서론에서는 저디폴트 포트폴리오의 특성을 설명하고, 기존 연구들이 실제 데이터에 의존한 경험적 분석에 머물러 있어 통제된 시뮬레이션 기반 연구가 부족함을 지적한다. 또한, 클래스 불균형이 정확도, 재현율, ROC‑AUC 등 다양한 성능 지표에 미치는 잠재적 편향을 문헌을 통해 정리한다.
방법론 파트에서는 두 가지 핵심 개념을 도입한다. 첫째는 전통적인 가중 증거(weight of evidence, WoE)와 정보값(Information Value, IV)이며, 이를 통해 각 변수의 사건 구분 능력을 정량화한다. 둘째는 개별 IV를 합산한 Aggregate Information Value(AIV)로, 변수들의 독립성을 가정할 경우 전체 모델이 보유한 신호‑대‑노이즈 비율을 한눈에 보여준다. 수식 (2.1)–(2.5)에서 WoE와 IV, AIV의 정의와 계산 방법을 상세히 제시하고, AIV가 Kullback‑Leibler 발산의 대칭 형태임을 강조한다.
시뮬레이션 설계는 두 개의 독립적인 요인을 조절한다. (i) 사건 비율(event rate) – 0.5%, 1%, 2%, 5%, 10% 등 다양한 수준; (ii) 예측 변수와 사건 사이의 연관 강도 – 로짓 파라미터의 절대값을 변화시켜 강한, 중간, 약한 연관을 구현한다. 각 조합마다 표본 크기(N = 5 000, 10 000, 20 000)를 변동시켜 EPV와 AIV이 성능에 미치는 영향을 동시에 관찰한다. 모델은 표준 로지스틱 회귀이며, 가중치 추정 시 최대우도법을 사용한다.
성능 평가는 크게 두 축으로 나뉜다. 첫 번째는 정확도와 최적 임계값(cut‑off)으로, 혼동 행렬 기반 지표를 통해 다수 클래스에 대한 편향을 정량화한다. 두 번째는 Gini 계수(ROC‑AUC × 2 − 1)로, 모델의 구별 능력을 사건 비율에 무관하게 평가한다. 결과는 다음과 같다. 사건 비율이 낮아질수록 정확도는 급격히 감소하고, 최적 임계값은 점점 낮은 확률값으로 이동한다. 이는 모델이 다수 클래스에 과도히 편향되어 소수 클래스(디폴트)를 놓치는 현상을 반영한다. 반면, Gini 계수는 표본이 충분히 클 경우(특히 N ≥ 10 000) 사건 비율 변화에 거의 민감하지 않으며, 연관 강도가 동일하면 Gini 값은 거의 일정하게 유지된다.
AIV 분석에서는 사건 비율이 1% 이하이면서 AIV가 0.2 미만인 경우 Gini가 0.55 이하로 떨어지는 반면, AIV가 0.4 이상이면 Gini가 0.65 이상으로 안정적인 구별 능력을 보인다. 즉, 변수들의 정보량이 충분히 클 경우 클래스 불균형이 구별 능력에 미치는 부정적 영향을 상쇄할 수 있음을 시사한다. 또한, EPV가 10 이하인 경우 회귀 계수의 편향이 커지지만, 이는 정확도보다 Gini에 미치는 영향이 제한적이다.
실무 가이드라인에서는 (1) 사건 비율이 1% 미만인 경우 최소 5 000~10 000 건의 표본 확보, (2) AIV ≥ 0.3을 목표로 변수 선정, (3) 모델 적용 시 사건 비율에 따라 임계값을 재조정(예: 사건 비율 0.5%에서는 0.2~0.3 수준의 cut‑off)할 것을 권고한다. 또한, 보정 기법(오버샘플링, SMOTE, 비용 민감 학습 등)은 본 연구의 범위 밖이지만, 제시된 가이드라인을 기준으로 보정 전후 성능 변화를 객관적으로 평가할 수 있다고 제언한다.
결론에서는 클래스 불균형이 로지스틱 회귀의 정확도와 임계값에 큰 영향을 미치지만, 충분한 표본과 높은 AIV를 확보하면 구별 능력(Gini)은 안정적임을 강조한다. 향후 연구에서는 실제 신용 데이터에 AIV 기반 가이드라인을 적용하고, 보정 기법과의 상호작용을 정량화하는 방향을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기