프로염증 펩타이드 예측을 위한 하이브리드 피처 퓨전 모델 KEMP‑PIP
KEMP‑PIP은 사전학습된 ESM2 단백질 언어 모델 임베딩과 다중 스케일 k‑mer, 물리화학 및 modlAMP 전역 특성을 결합한 하이브리드 로지스틱 회귀 기반 모델이다. 제로 분산 필터링과 계수 크기 기반 프루닝으로 차원을 축소하고, 클래스 가중치를 적용해 불균형을 보정한다. 두 개의 서브 모델을 확률 평균으로 앙상블하고 MCC 최적 임계값을 적용해 최종 라벨을 결정한다. 벤치마크 데이터에서 MCC 0.505, 정확도 0.752, AUC…
저자: Soumik Deb Niloy, Md. Fahmid-Ul-Alam Juboraj, Swakkhar Shatabda
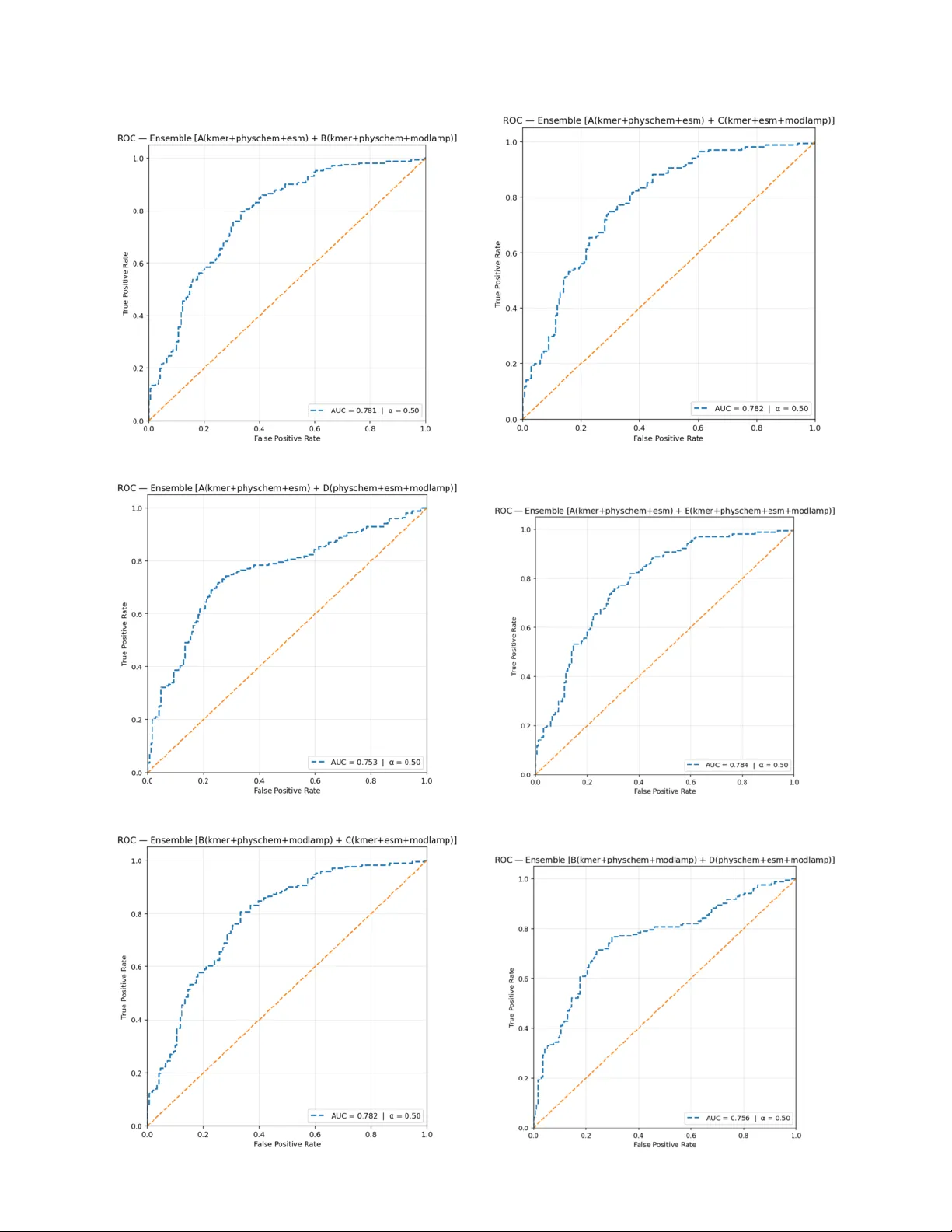
본 논문은 프로염증 펩타이드(PIP)의 실험적 검증이 비용·시간 면에서 비효율적인 문제를 해결하고자, 머신러닝 기반 예측 모델 KEMP‑PIP을 제안한다. 서론에서는 PIP가 면역 반응을 촉진하고 과다 활성 시 만성 염증·자가면역 질환을 유발한다는 생물학적 배경을 설명하고, 기존 예측 도구(ProIn‑fuse, MultiFeatVotPIP, StackPIP 등)의 한계—피처 중복, 클래스 불균형 처리 미흡, 일반화 검증 부족—를 지적한다. 이를 극복하기 위해 저자는 사전학습된 단백질 언어 모델(ESM2‑T6‑8M) 임베딩과 전통적인 핸드크래프트 피처를 결합한 하이브리드 구조를 설계하였다.
데이터 구축 단계에서는 MultiFeatVotPIP 벤치마크를 기반으로 중복 제거와 CD‑HIT(60 % 동일도) 필터링을 수행해 학습·테스트 셋을 각각 1,245/1,627, 171/171 비율로 구성하였다. 클래스 비율은 PIP가 약 43 %로 약간의 불균형을 보이며, 이는 모델 학습 시 클래스 가중치 적용으로 보정한다.
피처 추출은 네 가지 스트림으로 이루어진다. 첫째, k‑mer(2,3,4) 빈도는 각각 400, 8,000, 160,000 차원을 갖는 고차원 스파스 벡터이며, 제로 분산 필터링 후 35,358 차원으로 축소된다. 둘째, 물리화학 피처는 서열 길이, 평균 Kyte‑Doolittle 친수성, α‑헬릭스·β‑시트 친수성 모멘트, 양전하 및 전하 밀도, 2차 구조 선호도, 프로테아제 절단 사이트 밀도 등 11개 항목을 포함한다. 셋째, modlAMP 패키지를 이용해 전역 서열 특성(예: 이소전하, 수소 결합 가능성 등) 10개를 계산한다. 넷째, 사전학습된 ESM2‑T6‑8M 모델의
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기