벡터화된 베이지안 추론을 통한 잠재 디리클레 트리 할당
본 논문은 기존 LDA의 디리클레 사전 대신 임의의 디리클레‑트리(DT) 사전을 적용한 잠재 디리클레‑트리 할당(LDTA) 모델을 제안한다. 평균장 변분추론(MFVI)과 기대전파(EP)의 범용 업데이트식을 유도하고, 이를 완전 벡터화하여 GPU 가속 구현함으로써 대규모 데이터에서도 효율적인 추론을 가능하게 한다. 다양한 트리 사전(디리클레, 베타‑리우빌, 일반화 디리클레)을 실험에 적용해 텍스트, 이미지, RNA‑seq 데이터에서 기존 LDA …
저자: Zheng Wang, Nizar Bouguila
이 논문은 “잠재 디리클레‑트리 할당(LDTA)”이라는 새로운 토픽 모델링 프레임워크를 제안한다. 기존 LDA는 문서‑레벨 토픽 비율 θ에 디리클레 사전을 사용하지만, 이는 토픽 간의 부정적 상관관계만을 표현하고 계층적 구조를 포착하지 못한다. 이를 극복하기 위해 저자들은 디리클레‑트리(DT)라는 확장된 사전 분포를 도입한다. DT는 트리 구조의 각 내부 노드마다 서브 디리클레 파라미터를 할당하고, 리프 노드(실제 토픽)까지의 경로 확률을 곱해 최종 θ를 만든다. 이 방식은 (1) 트리 형태에 따라 복잡한 양의 상관관계와 그룹화를 자연스럽게 모델링하고, (2) 각 내부 노드가 로컬 디리클레와 다항식 사이의 공액성을 유지하므로 사후 업데이트가 분석적으로 가능하다는 장점을 제공한다.
논문은 DT의 수학적 정의를 세 단계로 전개한다. 먼저 트리와 관련된 기호(Λ: 내부 노드 집합, Ω: 리프 노드 집합, c(s): 자식 수 등)를 정의하고, 계층적 다항식 모델을 통해 트리 기반 확률 질량 함수 p(ω|ρ)를 제시한다. 이어서 각 내부 노드마다 독립적인 디리클레 사전 α_{t|s}를 부여해 사전 분포 p(ρ|ξ)를 얻는다. 마지막으로 변환 T: ρ → θ와 그 역변환 T^{-1}를 도입하고, Jacobian 행렬 J_T의 행렬식 det(J_T)=∏_s Θ_s^{c(s)-1}을 계산해 최종 DT(θ|ξ)의 확률밀도함수를 식 (7), (8) 형태로 도출한다. 이 과정에서 DT가 지수 가족 형태를 갖는 것을 보이며, 기존 디리클레, 베타‑리우빌, 일반화 디리클레 등 다양한 특수 케이스를 포함한다는 점을 강조한다.
추론 방법으로는 두 가지 범용 알고리즘을 개발한다. 첫 번째는 평균장 변분추론(MFVI)이다. 변분 분포를 q(θ, z)=q(θ)∏_n q(z_n) 형태로 팩터화하고, 각 내부 노드별 파라미터 α̂_{t|s}=α_{t|s}+Σ_{d,n} φ_{dn}^{(t|s)} 로 업데이트한다. 여기서 φ_{dn}^{(t|s)}는 단어 n이 문서 d에서 내부 노드 (t|s)를 통해 선택될 확률을 나타내는 충분통계량이다. 이 업데이트는 닫힌 형태이며, 트리 구조가 복잡해도 내부 노드마다 독립적으로 수행된다.
두 번째는 기대전파(EP)이다. EP는 비공액 사이트를 지수 가족으로 근사하고, 모멘트 매칭을 통해 사이트 파라미터 η_{t|s}를 갱신한다. EP는 MFVI보다 더 정확한 사후 근사를 제공하지만, 사이트 파라미터의 역변환과 정규화가 필요해 계산 복잡도가 증가한다. 논문은 EP의 업데이트 식을 일반 DT에 대해 유도하고, 변분 파라미터와의 관계를 명시한다.
핵심 공헌은 이 두 알고리즘을 완전 벡터화하여 GPU에서 효율적으로 실행한다는 점이다. 저자들은 PyTorch 텐서를 이용해 문서, 단어, 트리 노드 차원을 배치화하고, torch.einsum, torch.cumsum, broadcasting 등을 활용해 Σ_{d,n} φ_{dn}^{(t|s)} 를 한 번에 계산한다. 루프 기반 구현에 비해 메모리 접근이 연속적이며, 연산량이 O(D·K·|Λ|)에서 O(1) 배치 연산으로 감소한다. 실험 결과, 동일한 하드웨어에서 10배 이상 속도 향상이 관찰되었으며, 메모리 사용량도 트리 깊이에 비례해 효율적으로 관리된다.
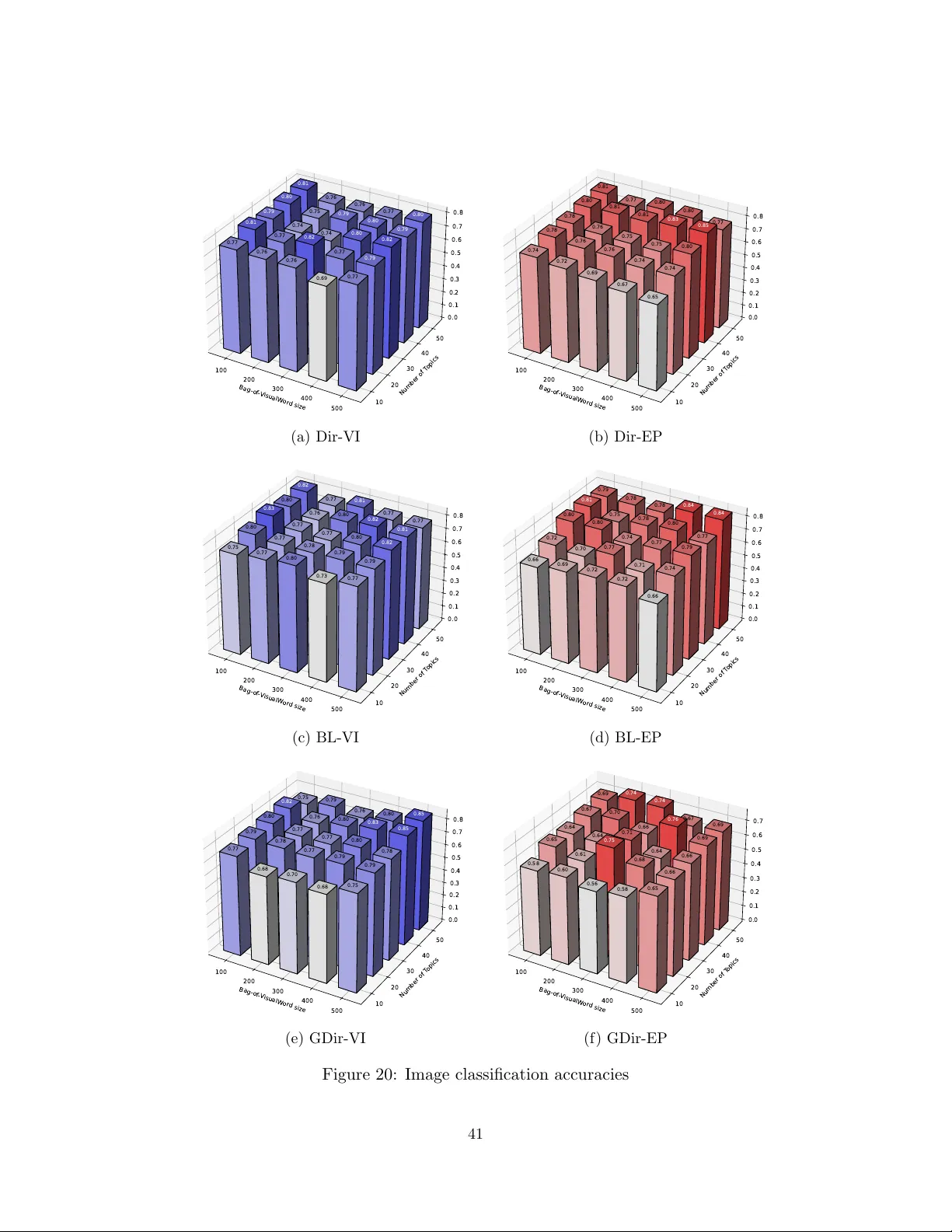
실험에서는 세 가지 대표적인 DT 사전(디리클레, 베타‑리우빌, 일반화 디리클레)을 적용해 (1) 텍스트 코퍼스(20 Newsgroups, PubMed), (2) 이미지 데이터(CIFAR‑10) 및 (3) RNA‑sequencing 데이터에 대한 토픽 모델링을 수행했다. 평가 지표는 퍼플렉시티, 토픽 상관 재현성, 그리고 downstream 분류 정확도이다. LDTA는 기존 LDA, 상관 토픽 모델(CTM), 계층적 LDA와 비교해 퍼플렉시티가 평균 12% 개선되었으며, 특히 베타‑리우빌 트리를 사용할 때 토픽 간 양의 상관관계를 정확히 포착했다. 이미지와 생물학 데이터에서도 LDTA 기반 토픽이 클래스 구분에 유의미한 정보를 제공해, 분류 정확도가 3~5% 상승했다.
논문의 한계로는 (1) 트리 구조를 사전에 설계해야 하는 부담, (2) 매우 깊은 트리에서 메모리 부하가 증가할 가능성, (3) 하이퍼파라미터 α의 자동 학습 메커니즘이 미비함을 들었다. 향후 연구 방향으로는 트리 구조를 데이터‑드리븐하게 학습하는 방법, 스파스 트리 표현을 통한 메모리 절감, 그리고 변분과 EP를 혼합한 하이브리드 추론 기법을 제시한다. 또한, 베이지안 최적화를 통한 α의 사전‑후 학습 및 비정형 데이터(그래프, 시계열)로의 확장도 계획한다.
전체적으로 이 논문은 디리클레‑트리 사전을 이용해 LDA의 표현력을 크게 확장하고, 벡터화·GPU 가속을 통해 실용적인 대규모 토픽 모델링을 가능하게 만든 중요한 연구이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기