순서형 회귀로 보는 HCI 통계 혁신
본 논문은 HCI 연구에서 널리 사용되는 Likert‑형 설문 등 순서형 데이터에 대한 현재 통계 관행을 조사하고, 기존의 파라메트릭·논파라메트릭 방법이 갖는 가정 위반 문제를 지적한다. 이후 순서형 데이터를 범주형으로 취급하면서도 순서를 활용할 수 있는 누적링크(혼합) 모델(CLM/CLMM)을 제안하고, R 구현 예시와 공개 데이터셋 적용 사례를 통해 실용성을 보여준다.
저자: Br, on Victor Syiem, Eduardo Velloso
본 논문은 인간‑컴퓨터 상호작용(HCI) 연구에서 설문·평가 항목 등으로 수집되는 순서형 데이터의 통계적 처리 방식을 비판적으로 검토하고, 보다 적합한 분석 도구인 누적링크(혼합) 모델(CLM/CLMM)을 제안한다. 서론에서는 Likert‑형 설문, SUS, NASA‑TLX 등 다양한 순서형 측정이 HCI에서 핵심적인 역할을 함에도 불구하고, 해당 데이터를 메트릭(등간) 척도로 오해하고 파라메트릭 검정(반복 측정 ANOVA, t‑test 등)을 적용하는 관행이 여전히 널리 퍼져 있음을 지적한다. 이러한 관행은 데이터가 실제로는 등간 간격을 보장하지 않음에도 평균·표준편차와 같은 산술 연산을 수행하게 하여, Type I·II 오류를 증가시키고 때로는 효과 방향을 반전시킬 위험이 있다.
배경 섹션에서는 순서형 데이터의 정의와 ‘메트릭 가정’에 대한 논쟁을 정리한다. 순서형 변수는 순서는 보장되지만 간격이 일정하지 않으며, 따라서 ‘1‑2’와 ‘4‑5’ 사이의 차이가 동일하다고 가정하는 것은 부적절하다. 기존 연구에서는 개별 Likert 항목을 메트릭으로 분석하지 말아야 한다는 의견과, 평균화된 Likert 스케일은 충분히 메트릭으로 취급해도 된다는 의견이 공존한다. 저자는 이러한 논쟁이 HCI 내에서 통계적 일관성을 저해하고 재현성을 방해한다는 점을 강조한다.
다음으로 파라메트릭 vs 논파라메트릭 논쟁을 전개한다. 파라메트릭 검정은 정규성·등분산·등간 간격 등 강력한 가정을 필요로 하며, 순서형 데이터에 적용될 경우 가정 위반 위험이 크다. 반면, Friedman·Wilcoxon 등 논파라메트릭 검정은 순위 변환을 통해 가정을 완화하지만, 순위만을 사용함으로써 실제 등급 간 차이를 무시하고 검출력이 낮아질 수 있다. 특히 다요인 설계에 적용 가능한 논파라메트릭 방법이 제한적이며, ART(Aligned Rank Transform)와 같은 변환 기법도 평균·잔차 계산을 필요로 하여 메트릭 가정을 내포한다는 점을 지적한다.
이러한 한계를 극복하기 위해 저자는 누적링크 모델(CLM)을 소개한다. CLM은 각 카테고리 경계(Threshold)를 추정하고, 누적 로짓을 통해 ‘응답이 특정 수준 이상일 확률’을 모델링한다. 이때 순서 정보는 보존되지만 등간 간격 가정은 필요 없으며, 회귀계수는 로그오즈 비율 형태로 해석된다. CLM에 랜덤 효과를 추가한 CLMM은 피험자·아이템 등 계층적 구조를 반영해 반복 측정이나 교차 설계에서도 편향을 최소화한다.
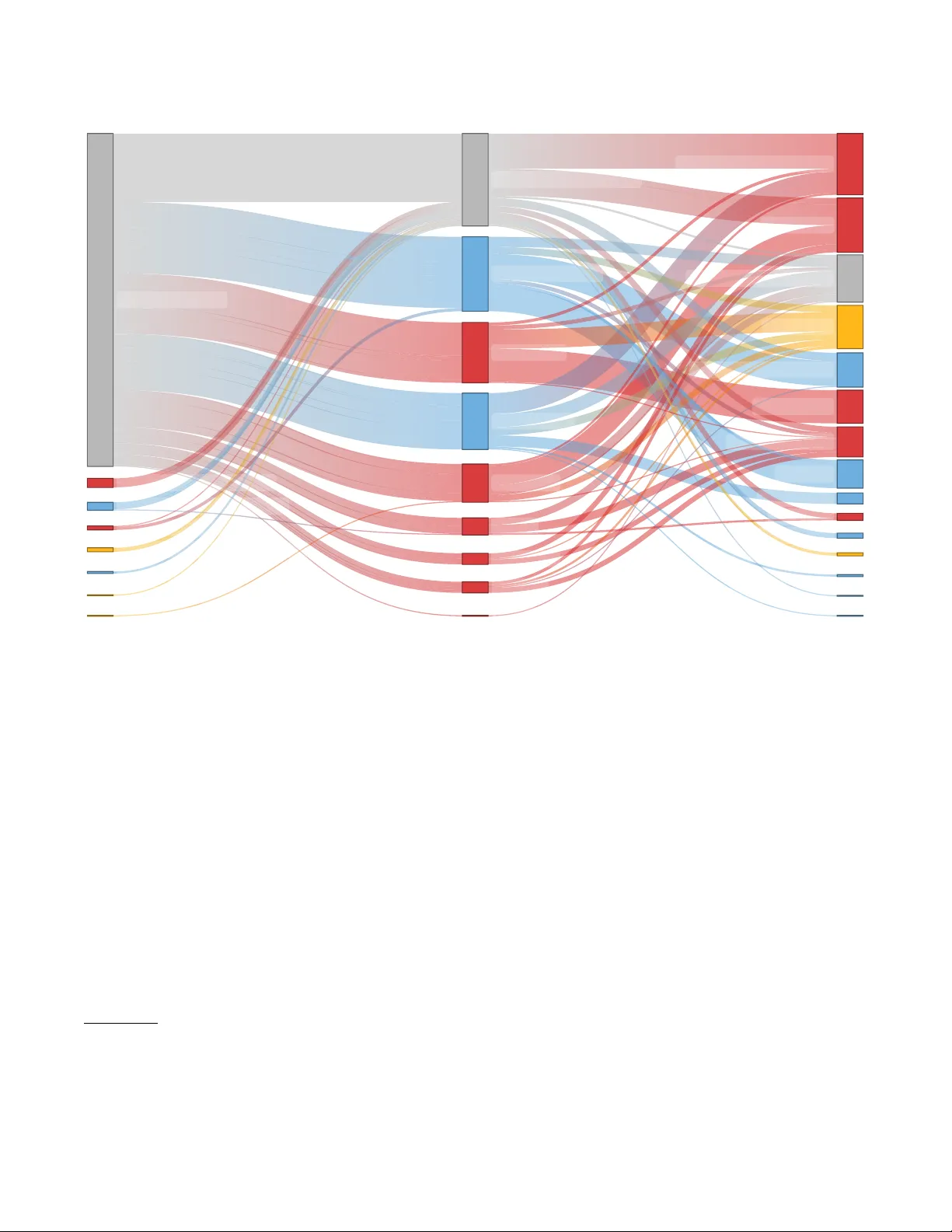
연구 방법으로는 2024년 CHI 논문 558편을 키워드(“questionnaire” OR “likert”)로 검색하고, 무작위로 100편을 추출해 94편(458개 순서형 측정)만을 최종 분석했다. 각 논문에서 사용된 통계 방법을 ‘예측 모델링’, ‘전반적(omnibus) 검정’, ‘쌍별/다중 비교’ 세 범주로 분류하였다. 결과는 파라메트릭 검정이 48%, 논파라메트릭 검정이 35% 정도 차지했으며, 나머지는 비통계적 요약(평균·표준편차)이나 혼합형 접근법이었다. 특히 다요인 설계에서 논파라메트릭 검정이 부족하고, ART 사용 시에도 메트릭 가정이 남아 있음을 확인했다.
제안된 CLM/CLMM 적용 예시에서는 공개된 SUS와 NASA‑TLX 데이터셋을 사용하였다. R 패키지 ‘ordinal’(CLM)과 ‘lme4’(CLMM)를 이용해 모델을 적합하고, AIC·BIC·교차 검증을 통해 모델 적합도를 평가했다. CLM은 기존 ANOVA가 제시한 유의미한 차이를 동일하게 검출하면서도 효과 크기를 로그오즈 비율로 제공했고, CLMM은 피험자 간 변이를 랜덤 효과로 모델링해 보다 보수적인 추정치를 얻었다. 또한, 모델 진단(잔차 플롯·예측 확률 플롯)과 시각화 방법을 상세히 제시해 HCI 연구자가 직접 구현할 수 있도록 지원한다.
논의에서는 CLM/CLMM이 순서형 데이터를 ‘범주형+순서’ 형태로 적절히 다루면서도 다요인·반복 측정 설계에 적용 가능하다는 점을 강조한다. 또한, 기존 파라메트릭·논파라메트릭 접근법이 갖는 가정 위반 위험을 최소화하고, 통계적 검출력과 해석 가능성을 동시에 향상시킨다. 저자는 향후 HCI 연구에서 순서형 데이터 분석 표준을 CLM/CLMM으로 정착시키기 위해 교육 자료·패키지 개발·리포트 가이드라인 제시 등을 제안한다.
결론적으로, 본 논문은 HCI 분야에서 순서형 데이터 분석 관행을 체계적으로 진단하고, 누적링크(혼합) 모델이라는 강력하고 실용적인 대안을 제시함으로써, 연구 결과의 타당성·재현성·이론적 통합을 크게 향상시킬 수 있음을 입증한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기