슬랙 양자화 트랜스포머 기반 실시간 스케줄러 TempoNet
TempoNet은 작업의 남은 시간(슬랙)을 정량화하여 학습 가능한 임베딩으로 변환하고, 경량화된 순열 불변 트랜스포머와 깊은 Q‑네트워크를 결합한 강화학습 스케줄러이다. 블록‑단위 Top‑k와 지역적 청킹을 이용한 희소 어텐션으로 전역 상호작용을 거의 선형 시간에 처리하며, 다코어 매핑 레이어를 통해 Q‑값을 실제 코어 할당으로 변환한다. 실험 결과, 산업용 혼합 중요도 워크로드와 100~600개의 작업을 가진 대규모 멀티코어 환경에서 기존 …
저자: Rong Fu, Yibo Meng, Guangzhen Yao
**1. 서론**
실시간 시스템에서는 마감 기한을 놓치지 않으면서도 제한된 연산 자원을 효율적으로 배분해야 한다. 전통적인 Rate Monotonic(RM)이나 Earliest Deadline First(EDF)와 같은 정책은 이론적 최적성을 제공하지만, 부하가 급증하거나 실행 시간 불확실성이 존재할 때 성능이 급격히 저하된다. 최근 강화학습(RL) 기반 접근법이 클라우드 오케스트레이션, 작업장 스케줄링 등에서 성공을 거두었지만, 대부분이 순차적 입력 혹은 고정 크기 벡터에 의존해 순열 불변성을 보장하지 못한다. 또한, 실시간 시스템이 요구하는 서브‑밀리초 수준의 추론 지연을 만족시키기 위한 경량화된 모델 설계가 부족했다.
**2. 관련 연구**
클래식 스케줄러(RM, EDF, Pfair, LLREF)와 학습 기반 스케줄러(Deep Q‑Network, PPO, GNN, 트랜스포머 기반)들을 비교한다. 기존 트랜스포머 기반 RL은 Decision Transformer와 같이 순차 히스토리를 필요로 하거나, 대규모 모델을 사용해 추론 지연이 크게 발생한다. 희소 어텐션, 블록‑스파스 라우팅, 하드웨어 가속 등 효율성을 위한 연구가 존재하지만, 실시간 가치 기반 스케줄링에 직접 적용하기엔 설계가 복잡하고, 마감 기한에 대한 민감도가 충분히 반영되지 않는다.
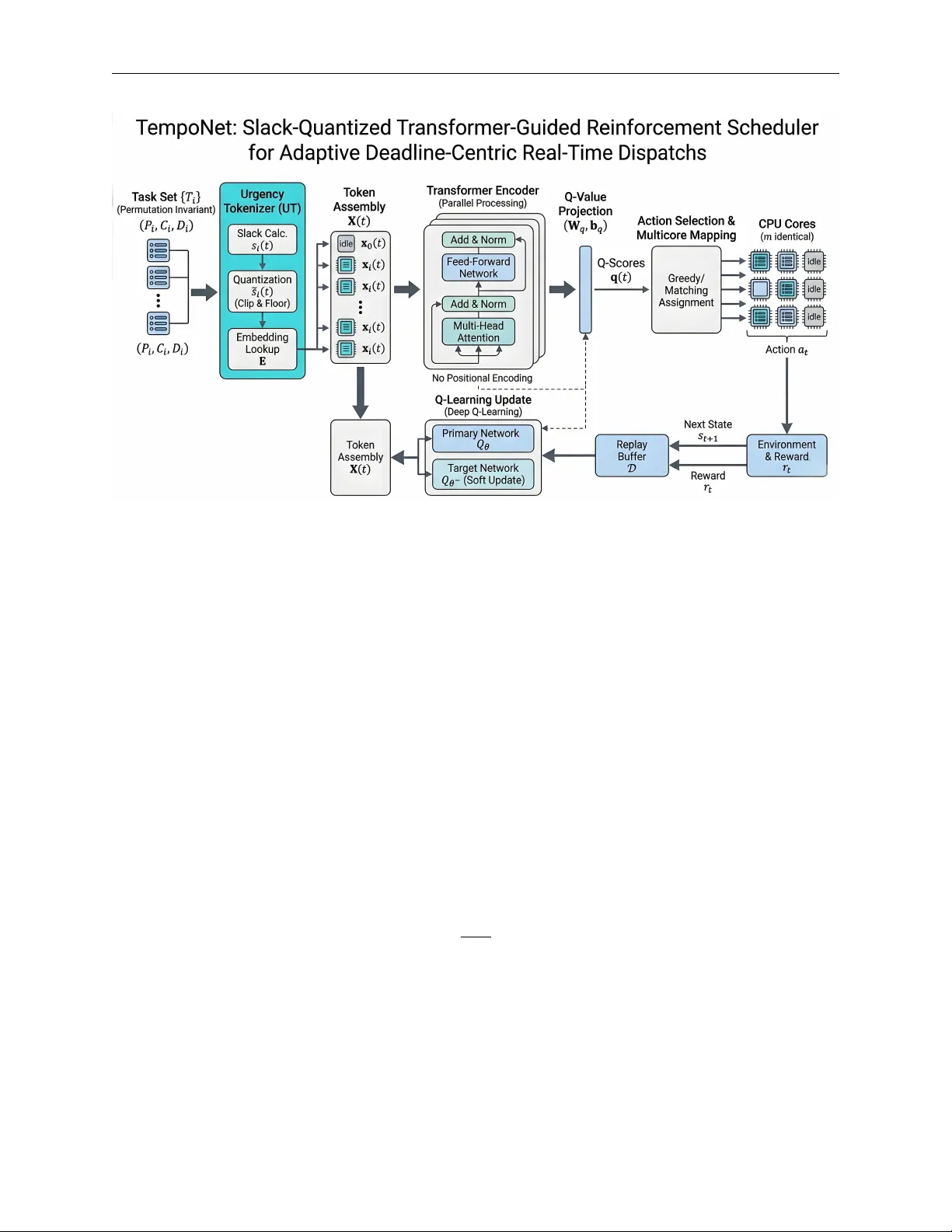
**3. TempoNet 설계**
TempoNet은 세 가지 핵심 모듈로 구성된다.
- **Urgency Tokenizer(UT)**: 작업 i의 현재 슬랙 s_i(t)=|d_i−t|−c_i(t)를 Δ 간격으로 양자화하고, Q개의 구간에 대해 학습 가능한 임베딩 E∈ℝ^{Q×d}를 조회한다. 이 과정은 연속적인 시간 정보를 이산화해 학습 안정성을 높이고, 마감이 임박한 작업에 대한 표현을 강조한다.
- **경량 순열 불변 트랜스포머 인코더**: UT 토큰들을 (N+1)×d 행렬 X(t)로 모아 L개의 트랜스포머 블록에 입력한다. 각 블록은 Multi‑Head Attention과 Feed‑Forward Network를 포함하며, 절대 위치 인코딩을 생략해 순열 불변성을 유지한다. 연산량을 줄이기 위해 블록‑단위 Top‑k 선택과 로컬 청킹을 적용, 전체 복잡도를 O(N·k) 수준으로 낮춘다.
- **멀티코어 매핑 레이어**: 인코더 출력 H^{(L)}를 선형 투사해 각 토큰에 Q‑값 q_a(t)를 부여한다. 단일 코어에서는 argmax로 작업을 선택하고, 다코어 환경에서는 마스크‑그리디 방식으로 가장 높은 Q‑값을 가진 토큰을 차례로 선택한다. 필요 시 차별화 가능한 bipartite matching을 사용해 최적 매칭을 구한다.
**4. 학습 및 최적화**
Deep Q‑Learning을 기반으로 경험 재플레이와 소프트 타깃 네트워크(Polyak averaging)를 사용한다. TD‑target y = r + γ·max_{a'} Q_{θ^-}(s',a') 로 정의하고, MSE 손실을 최소화한다. ε‑greedy 탐색 스케줄은 선형 감쇠 방식으로 설정한다. 행동 복제(Behavioral Cloning) 사전학습을 통해 초기 정책을 빠르게 수렴시켰으며, 동일한 인프라에서 Actor‑Critic 변형을 적용해도 추론 파이프라인을 변경할 필요가 없었다.
**5. 실험 설정**
세 가지 워크로드를 사용했다. (1) 단일 코어 주기 작업 집합(표준 RM·EDF 벤치마크), (2) 산업용 혼합 중요도 멀티코어 트레이스(실제 임베디드 시스템 로그), (3) 100~600 작업 규모의 대규모 멀티코어 시뮬레이션. 비교 대상은 RM, EDF, FF‑DQN, PPO, A3C, Rainbow DQN, GraSP‑RL, GNN‑기반, 최신 트랜스포머‑기반 스케줄러 등이다. 성능 지표는 마감 충족률(u), 평균 응답 시간, 표준편차, 그리고 추론 지연(마이크로초 수준)이다.
**6. 결과**
TempoNet은 전체 실험에서 평균 마감 충족률 u≈0.87을 기록, 가장 높은 평균값과 최소 변동성을 보였다. 특히 600 작업 규모에서도 0.84 이상의 충족률을 유지했으며, 추론 지연은 0.3~0.9 ms로 실시간 요구사항을 만족했다. 어텐션 집중도 분석은 마감이 임박한 토큰에 높은 어텐션 가중치가 할당되는 것을 확인했으며, 엔트로피 감소는 정책이 점차 확신을 갖고 있음을 의미한다. 슬랙 양자화 레벨(Q)와 bin width(Δ) 민감도 실험에서는 Q=32~64, Δ≈5~10ms가 최적 성능을 제공한다. 스트레스 테스트에서 과부하 상황에서도 간단한 런타임 완화(우선순위 재조정, 토큰 마스킹 강화)를 적용하면 급격한 성능 저하를 방지할 수 있었다.
**7. 논의 및 한계**
TempoNet은 경량화와 전역 상호작용을 동시에 달성했지만, 토큰 수가 수천 개를 초과하는 초대규모 시스템에서는 여전히 메모리 부담이 존재한다. 또한, 현재는 동일한 작업 특성을 가진 동일 코어 환경을 가정했으며, 이종 코어나 전력 제약을 포함한 다목적 최적화에는 추가 설계가 필요하다.
**8. 결론**
TempoNet은 슬랙 양자화 토큰, 희소 순열 불변 트랜스포머, 그리고 효율적인 다코어 매핑을 결합한 최초의 실시간 강화학습 스케줄러이다. 실험을 통해 전통적인 분석 스케줄러와 최신 딥 RL·GNN 기반 방법을 모두 능가하는 마감 충족률과 서브‑밀리초 추론 지연을 입증했으며, 어텐션 기반 해석 가능성까지 제공한다. 향후 연구에서는 이종 코어 지원, 전력·열 제약 통합, 그리고 초대규모 작업 집합에 대한 메모리 효율화 방안을 탐색할 예정이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기