알려진 것을 피하라: GFlowNet을 위한 발산 경로 균형
본 논문은 GFlowNet 학습 시 탐색 효율성을 높이기 위해 ‘Adaptive Complementary Exploration(ACE)’이라는 새로운 알고리즘을 제안한다. ACE는 기존의 목표 분포를 학습하는 정규 GFlowNet과는 별도로, 과소 탐색된 고보상 영역을 찾아내는 탐색 전용 GFlowNet을 학습한다. 이를 위해 ‘Divergent Trajectory Balance(DTB)’라는 새로운 균형 조건을 도입해, 과다 할당된 상태에는 …
저자: Pedro Dall'Antonia, Tiago da Silva, Daniel Csillag
1. 서론 및 배경
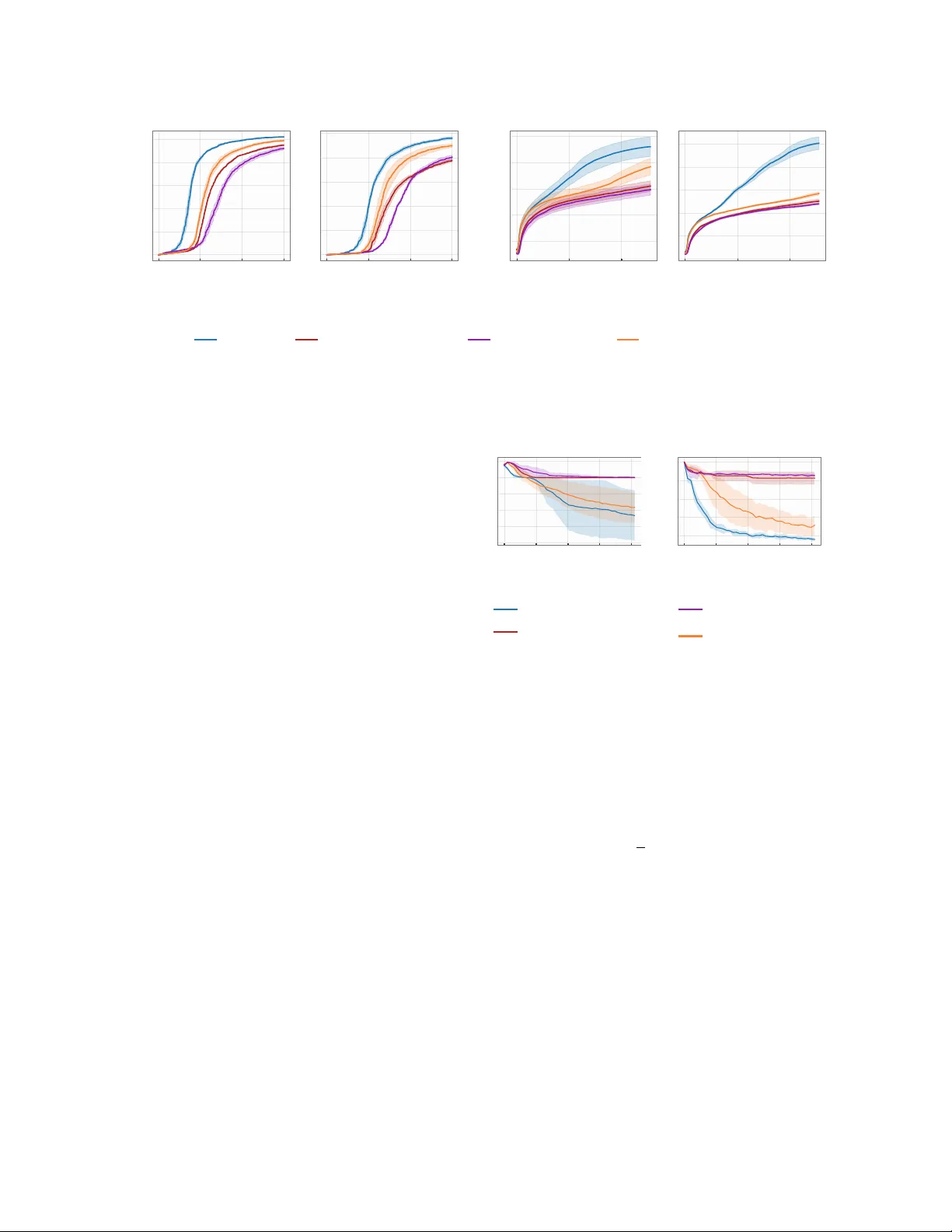
Generative Flow Networks(GFlowNets)는 보상 함수 R(x)에 비례하는 확률 분포를 샘플링하기 위해 설계된 amortized sampler이다. 기존 학습 방법은 포워드 정책 p_F와 백워드 정책 p_B를 동시에 최적화해 Trajectory Balance(TB) 조건 Z·p_F(τ)=p_B(τ|x)·R(x)를 만족하도록 한다. 그러나 상태 그래프가 거대하고 보상이 희소한 경우, ε‑greedy 탐색(포워드 정책과 균일 정책의 혼합)만으로는 모든 고보상 모드를 충분히 방문하기 어렵다. 이는 ‘모드 붕괴’ 현상으로 이어져 학습 효율이 급격히 저하된다.
2. 기존 탐색 강화 방법의 한계
최근 연구들은 호기심 기반 보상(예: Random Network Distillation, RND)이나 Adaptive Teachers(AT)와 같은 외부 손실을 탐색 정책 p_E에 결합해 탐색을 강화한다. 하지만 이러한 방법은 고보상 영역을 과도하게 강조하거나, 이미 잘 학습된 영역에도 샘플을 할당해 자원을 낭비한다. 또한, 보상 R와 탐색 보조 보상 사이의 스케일 차이로 인해 학습이 불안정해지는 경우가 있다.
3. ACE(Adaptive Complementary Exploration)와 DTB(Divergent Trajectory Balance)
본 논문은 두 개의 GFlowNet을 동시에 학습한다.
- Canonical GFlowNet g = (Z, p_F, p_B): 목표 보상 R에 맞는 분포 p⊤를 학습한다.
- Exploratory GFlowNet g∇ = (Z∇, p∇_F, p∇_B): 현재 canonical 네트워크가 과소 탐색한 영역을 목표로 한다.
핵심 정의는 Over‑Allocated(OA)와 Under‑Allocated(UA) 영역이다. OA(α,g)={x|ĤR_g(x)≥α·R(x)}이며, UA는 그 여집합이다. 여기서 ĤR_g(x)=Z·p⊤(x)는 canonical 네트워크가 유도한 보상이다.
DTB 조건은 다음과 같다.
- τ∈UA인 경우: Z∇·p∇_F(τ)=R(x)^β·p∇_B(τ|x)
- τ∈OA인 경우: p∇_F(τ)=0
즉, 탐색 정책은 OA 영역에 전혀 확률을 할당하지 않으며, UA 영역에만 보상에 비례해 샘플을 생성한다.
DTB 손실 L∇은 식 (9)의 로그 제곱 잔차로 정의된다.
L∇(g∇;τ,α)=log²
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기