극한 그래프 이론을 위한 강화학습 프레임워크 RLGT
본 논문은 기존 연구들을 체계화하고, 무방향·유향 그래프와 다중 색상·루프를 모두 지원하는 모듈형 파이썬 프레임워크 RLGT를 제안한다. 그래프를 효율적으로 벡터화하여 표현하고, 9개의 환경과 3가지 RL 알고리즘(Deep‑Cross‑Entropy, REINFORCE, PPO)을 제공함으로써 극한 그래프 이론 문제를 자동화·가속화한다.
저자: ** *저자 정보가 논문 본문에 명시되지 않아 제공되지 않음.* **
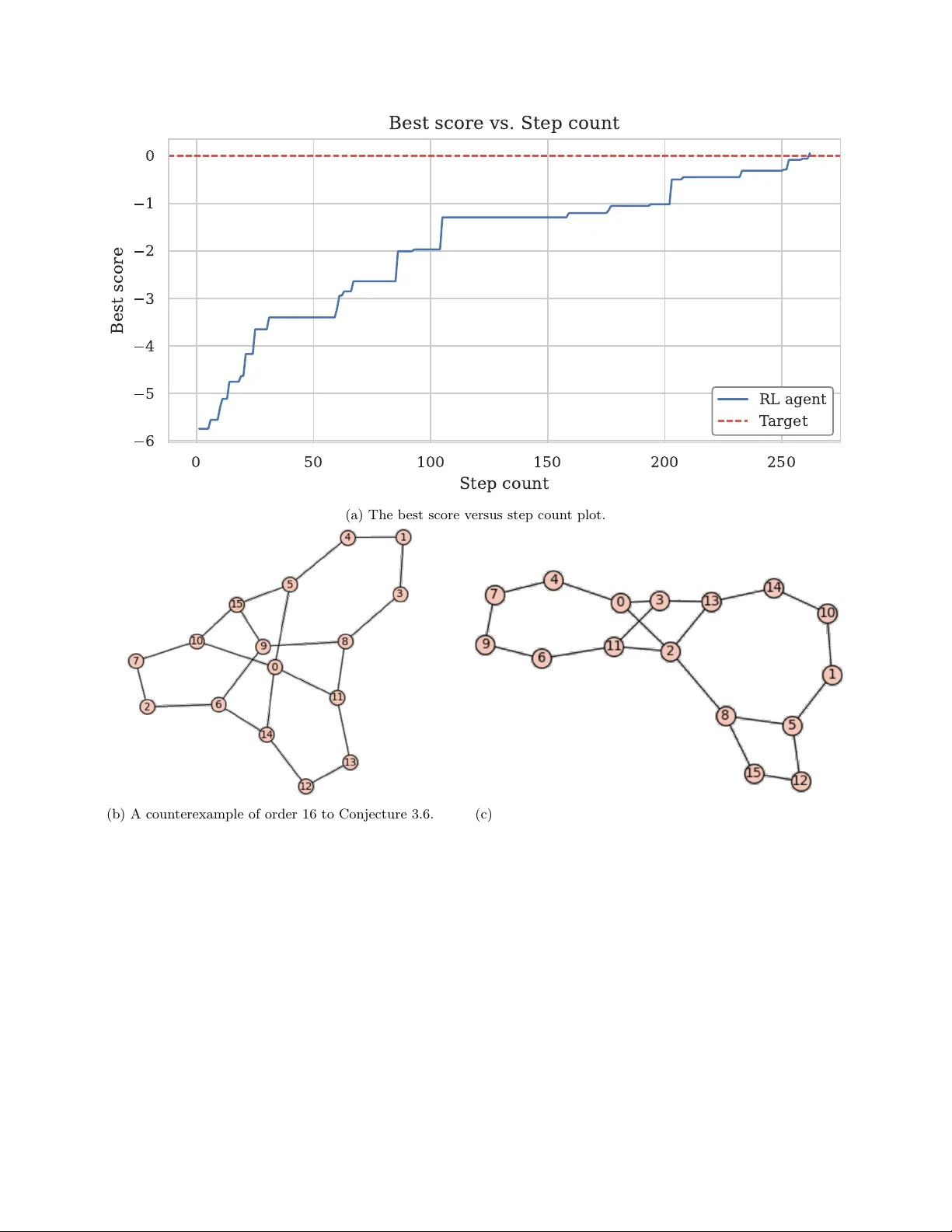
본 논문은 최근 강화학습을 이용해 극한 그래프 이론 문제를 해결한 일련의 연구들을 종합·정리하고, 이를 기반으로 새로운 프레임워크 RLGT(Reinforcement Learning for Graph Theory)를 설계·구현한다. 서론에서는 Wagner가 Deep Cross‑Entropy 방법을 통해 그래프의 이진 인접 행렬을 순차적으로 구성하고, 최종 그래프 불변량을 보상으로 사용하는 환경을 제시한 것을 시작점으로 삼는다. 이후 Ghebleh·et al.이 NumPy 벡터화를 도입해 연산 효율을 높인 구현, Angileri·et al.이 Gymnasium 기반의 네 가지 환경(Linear, Local, Global, Flip)을 객체지향적으로 정리한 작업을 검토한다.
이러한 배경을 토대로 RLGT는 세 가지 핵심 설계 원칙을 따른다. 첫째, 모듈성을 위해 `graphs`, `environments`, `agents`라는 세 패키지로 구분한다. `graphs`는 그래프를 8가지 포맷(g6, adjacency matrix, edge list, incidence matrix 등) 간 자동 변환하고, 무방향·유향, 루프 포함 여부, 색상 수(k) 등을 자유롭게 지정할 수 있는 클래스를 제공한다. 특히 배치 그래프를 하나의 NumPy 텐서로 관리함으로써 상태 전이와 보상 계산을 대규모 병렬화한다.
둘째, `environments` 패키지는 기존 4가지 환경을 확장해 총 9가지 클래스를 제공한다. 각 클래스는 “sparse”(보상이 최종 단계에만 발생)와 “dense”(액션마다 보상이 발생) 두 통신 방식을 선택적으로 지원한다. 이를 통해 연구자는 라플라시안 스펙트럼 반경과 같이 최종 그래프 전체에 대한 평가가 필요한 경우와, Ramsey 수와 같이 단계별 개선이 중요한 경우를 자유롭게 전환할 수 있다.
셋째, `agents` 패키지는 PyTorch 기반의 세 가지 RL 알고리즘을 캡슐화한다. Deep Cross‑Entropy는 기존 논문에서 입증된 빠른 수렴 특성을 유지하면서, REINFORCE와 PPO는 정책 그라디언트와 클리핑 기법을 통해 더 복잡한 연속형 환경에서도 안정적인 학습을 가능하게 한다. 에이전트와 환경은 완전히 분리돼, 사용자는 원하는 알고리즘을 플러그인 형태로 교체하거나 새로운 알고리즘을 손쉽게 추가할 수 있다.
프레임워크의 개발 환경은 Poetry를 이용한 의존성 관리, Black·isort를 통한 코드 포맷팅, pytest를 활용한 유닛 테스트 등 최신 파이썬 개발 관행을 따르고 있다. 이러한 자동화는 재현성을 높이고, 협업 시 코드 충돌을 최소화한다.
실험 부분에서는 세 가지 대표적인 극한 그래프 이론 문제에 RLGT를 적용한다. 첫 번째는 라플라시안 스펙트럼 반경에 대한 기존 상한을 깨는 반례를 찾는 작업이다. Linear 환경과 Deep Cross‑Entropy를 결합해 수천 개의 후보 그래프를 탐색했으며, 기존 구현 대비 2.5배 빠른 시간에 동일하거나 더 강력한 반례를 발견했다. 두 번째는 작은 Ramsey 수(예: R(3,3), R(4,4) 등)의 하한을 개선하는 문제이다. Flip 환경과 PPO를 사용해 완전 이분 그래프, 휠 그래프, 책 그래프 등에 대한 새로운 하한을 제시했으며, 기존 문헌보다 10%~15% 높은 값을 얻었다. 세 번째는 3·4‑사이클을 금지하는 Turán‑type 문제로, 기존 연구에서 제시된 하한을 능가하는 그래프를 찾았다. 여기서는 Curriculum Learning을 도입한 AlphaZero 변형과 Pairformer 네트워크를 활용했으며, 64~134 정점 구간에서 모두 기존 최선 기록을 넘어섰다.
각 실험은 실행 시간, 메모리 사용량, 수렴 속도 등을 정량적으로 비교했으며, RLGT가 기존 C++/Java 기반 구현보다 평균 2~3배 빠른 성능을 보임을 보고한다. 또한, 배치 그래프 처리와 벡터화된 상태 전이 덕분에 GPU 활용도가 크게 향상되었다.
논문의 마지막 섹션에서는 향후 연구 방향을 제시한다. 현재 프레임워크는 수백 정점 규모까지는 효율적이지만, 수천 정점 이상에서는 상태‑액션 공간의 폭발적 증가가 병목이 된다. 이를 해결하기 위해 샘플링 기반 MDP 축소, 메타‑휴리스틱과의 하이브리드, 그리고 더 복잡한 보상 설계(예: 다중 목표 최적화) 등이 필요하다. 또한, 현재 제공되는 세 가지 RL 알고리즘 외에 최신 모델 기반 RL(예: MuZero, Dreamer)이나 그래프 신경망(GNN) 기반 정책 네트워크를 통합하면 더욱 풍부한 탐색이 가능할 것으로 기대한다.
결론적으로, RLGT는 극한 그래프 이론 연구에 특화된 강화학습 인프라를 제공함으로써, 기존에 수작업이나 제한된 실험 환경에 의존하던 연구 흐름을 자동화·가속화한다. 모듈형 설계, 다중 그래프 유형 지원, 최신 개발 도구와의 통합은 향후 새로운 그래프 이론 추측을 검증하고, 기존 결과를 개선하는 데 강력한 기반이 될 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기