라벨 없는 데이터 활용한 역인과 도메인 일반화
본 논문은 결과(Y)가 관측 변수(X)를 생성하는 역인과(anti‑causal) 구조를 전제로, 라벨이 없는 다수 환경의 데이터를 이용해 환경 변동 방향을 추정하고, 이를 기반으로 평균·공분산 변동에 대한 민감도를 억제하는 두 가지 정규화(MIR, VIR)를 제안한다. 이 정규화는 라벨이 없는 데이터만으로도 최악의 위험을 최소화하는 최적성을 보장하며, 물리 시스템 및 생리 신호 데이터에서 실험적으로 효과를 입증한다.
저자: Sorawit Saengkyongam, Juan L. Gamella, Andrew C. Miller
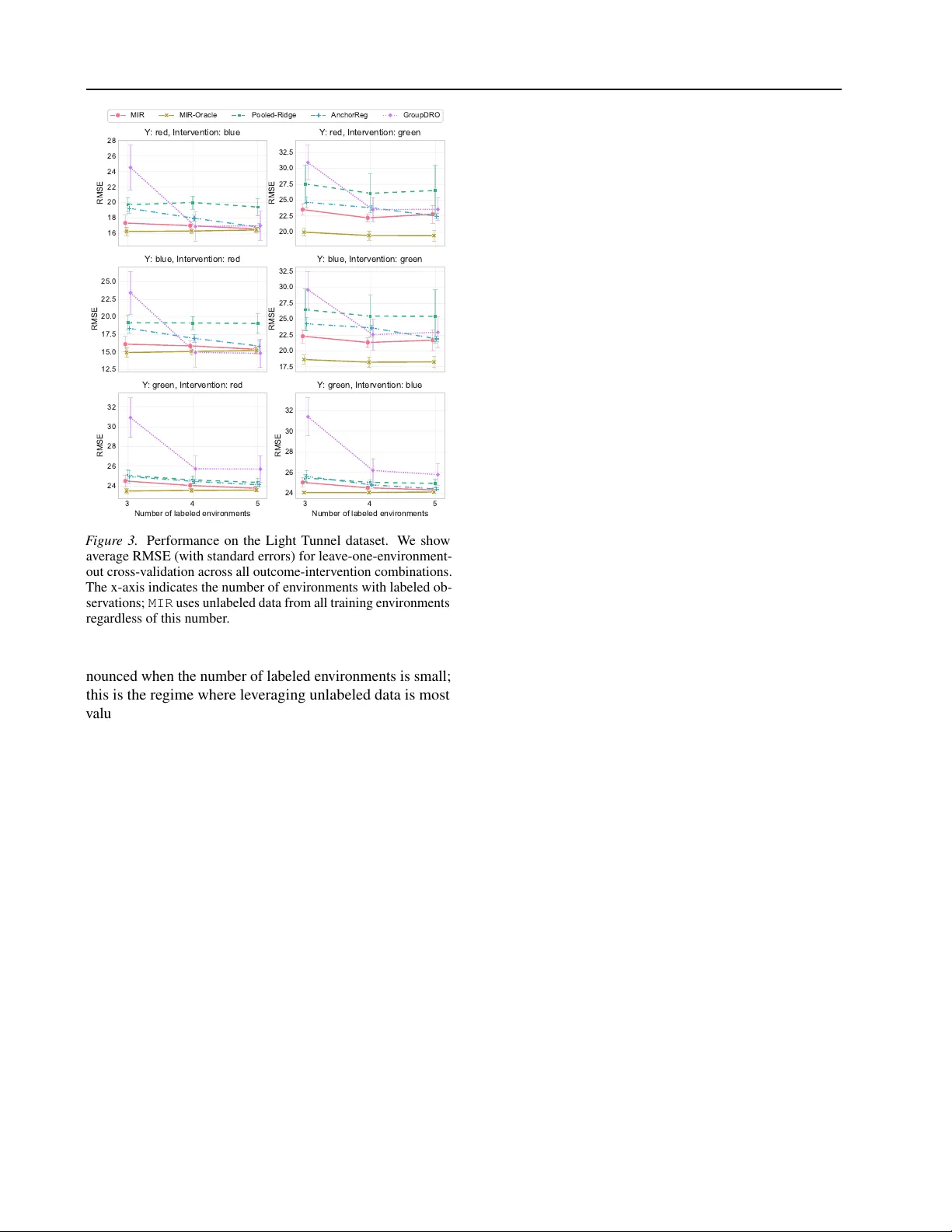
본 논문은 도메인 일반화(Domain Generalization) 문제를 역인과(anti‑causal) 설정 하에 새롭게 접근한다. 전통적인 도메인 일반화 방법은 여러 환경에서 라벨이 있는 데이터를 필요로 하지만, 실제 현장에서는 라벨이 제한적이고 라벨 없는 데이터가 풍부한 경우가 많다. 저자들은 결과 변수 Y가 관측 변수 X를 생성한다는 구조적 가정( Y → X )을 도입함으로써, 환경 교란 εₑ가 X에만 영향을 미치고 Y와는 독립적이라는 특성을 활용한다. 이때 εₑ는 직접 관측되지 않지만, X의 평균과 공분산이 εₑ와 동일한 변동을 반영한다는 점을 이용해 라벨 없는 데이터만으로도 교란 방향을 추정할 수 있다.
**문제 정의 및 설정**
- 다수 환경 E가 존재하고, 각 환경 e는 구조적 인과 모델 S(e)로 정의된다.
- 라벨이 있는 데이터는 소수 환경 L ⊂ E에서만 확보되고, 라벨 없는 데이터는 모든 훈련 환경 E_tr에서 수집된다.
- 목표는 새로운 테스트 환경 e_tst ∈ E 에 대해 최악 위험 sup_{e∈E} E_e
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기