유전체 기초 모델을 정착시키는 JEPA DNA
JEPA‑DNA는 기존의 마스크드 언어 모델(MLM)·다음 토큰 예측(NTP) 방식이 놓치기 쉬운 전역적인 기능적 의미를 학습하도록 설계된 새로운 사전학습 프레임워크이다. 토큰 수준 복원 손실에 더해, 마스크된 구간의 고차원 임베딩을 예측하도록 CLS 토큰을 지도함으로써 “잠재적 정착(latent grounding)”을 제공한다. 이중 마스킹·EMA 기반 타깃 인코더·VICReg 정규화 등을 결합한 다목적 손실을 통해, JEPA‑DNA는 기존 …
저자: Ariel Larey, Elay Dahan, Amit Bleiweiss
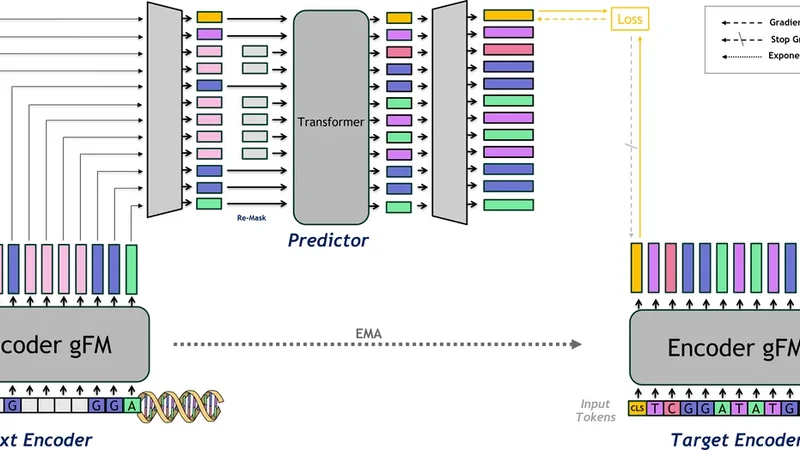
본 논문은 현재 유전체 기초 모델(GFM)이 마스크드 언어 모델(MLM)이나 다음 토큰 예측(NTP)과 같은 토큰‑레벨 복원 목표에 의존함으로써, 로컬 시퀀스 문법은 잘 학습하지만 장거리 조절 메커니즘이나 전사·번역 등 고차원 기능을 포착하지 못한다는 한계를 지적한다. 이를 “granularity trap”이라고 명명하고, 모델이 “노이즈”에 과도하게 집중해 전역적인 생물학적 의미를 놓치는 현상을 설명한다. 이러한 문제를 해결하기 위해, 저자들은 Joint‑Embedding Predictive Architecture(JEPA)를 DNA 시퀀스에 직접 적용한 새로운 사전학습 프레임워크인 JEPA‑DNA를 제안한다.
JEPA‑DNA는 두 개의 인코더를 사용한다. 첫 번째는 컨텍스트 인코더(Eθ)로, 입력 시퀀스에 마스크 토큰(
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기