그래프 신경망을 활용한 반지도 학습 이론과 실증
본 논문은 그래프 신경망(GNN)의 반지도 노드 회귀 성능을 이론적으로 규명한다. 선형 그래프 컨볼루션과 깊은 ReLU 읽기층을 갖는 집계‑읽기 모델에 대해, 라벨 비율과 그래프 의존성을 명시한 비대칭 위험 상한을 제시한다. 또한 그래프 스무딩과 부드러운 비선형 읽기함수를 결합한 경우, 완전 감독 상황의 비모수 수렴률을 복원하면서 라벨이 부족할 때의 수렴 특성을 분석한다. 실험을 통해 이론적 예측을 검증한다.
저자: Juntong Chen, Claire Donnat, Olga Klopp
**1. 서론 및 배경**
반지도 학습은 라벨이 제한된 그래프 구조 데이터에서 노드 레이블을 예측하는 핵심 문제이다. 최근 그래프 신경망(GNN)이 뛰어난 실험적 성능을 보였지만, 언제, 왜 성공하는지에 대한 이론적 설명은 부족했다. 본 논문은 이러한 격차를 메우기 위해, 일반적인 메시지 패싱 아키텍처를 포괄하는 “집계‑읽기(aggregate‑and‑readout)” 모델을 제안하고, 그에 대한 비대칭 위험 분석을 수행한다.
**2. 모델 정의**
- **집계 단계**: 입력 특성 행렬 X∈ℝ^{n×d} 에 대해 그래프 라플라시안 L 또는 인접 행렬 A 에 선형 연산을 k번 적용한다. 즉, H^{(0)}=X, H^{(t+1)}=σ(L H^{(t)}) (t=0,…,k−1)이며, σ는 선형 또는 ReLU와 같은 비선형이다.
- **읽기 단계**: 최종 노드 표현 H^{(k)} 에 깊은 ReLU 네트워크 f_θ (층 수 L_{read})를 적용해 예측 ŷ_i = f_θ(H^{(k)}_i) 를 얻는다. 전체 파라미터는 θ 와 그래프 전파 파라미터(예: 스케일링 α)이다.
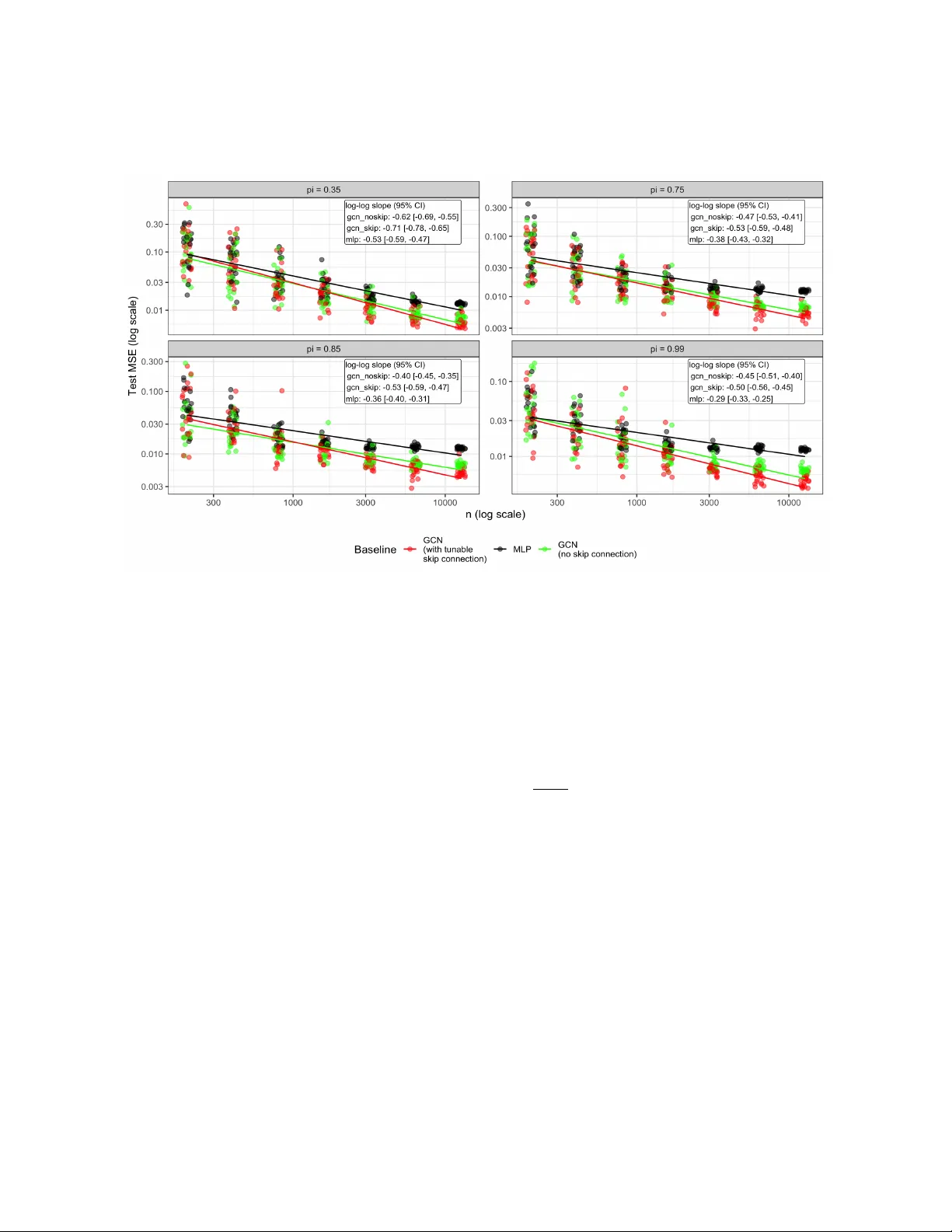
**3. 이론적 결과**
- **위험 상한**: 최소제곱 손실 ℓ(θ)=‖Y−f_θ(H^{(k)})‖_2^2 에 대해, 라벨이 있는 노드 집합 S (크기 |S|=pn) 를 무작위 추출한다고 가정한다. 고정된 θ 에 대해 기대 위험은
E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기