다단계 샘플링에서 M추정과 예측 기반 편향 보정
두 단계 다파동 샘플링에서 저비용 예측값을 활용하고, 고비용 정밀 측정을 적응적으로 수집하는 M‑추정 방법을 제안한다. 제안된 Predict‑Then‑Debias 추정량은 전체 데이터를 이용해 효율성을 높이고, 가중치와 편향 보정을 통해 일관성과 점근적 정규성을 확보한다. 또한 근사 탐욕적 샘플링 전략을 도입해 균등 샘플링 대비 분산을 감소시킨다. 이론적 증명과 시뮬레이션을 통해 신뢰구간의 유효성을 확인한다.
저자: Dan M. Kluger, Stephen Bates
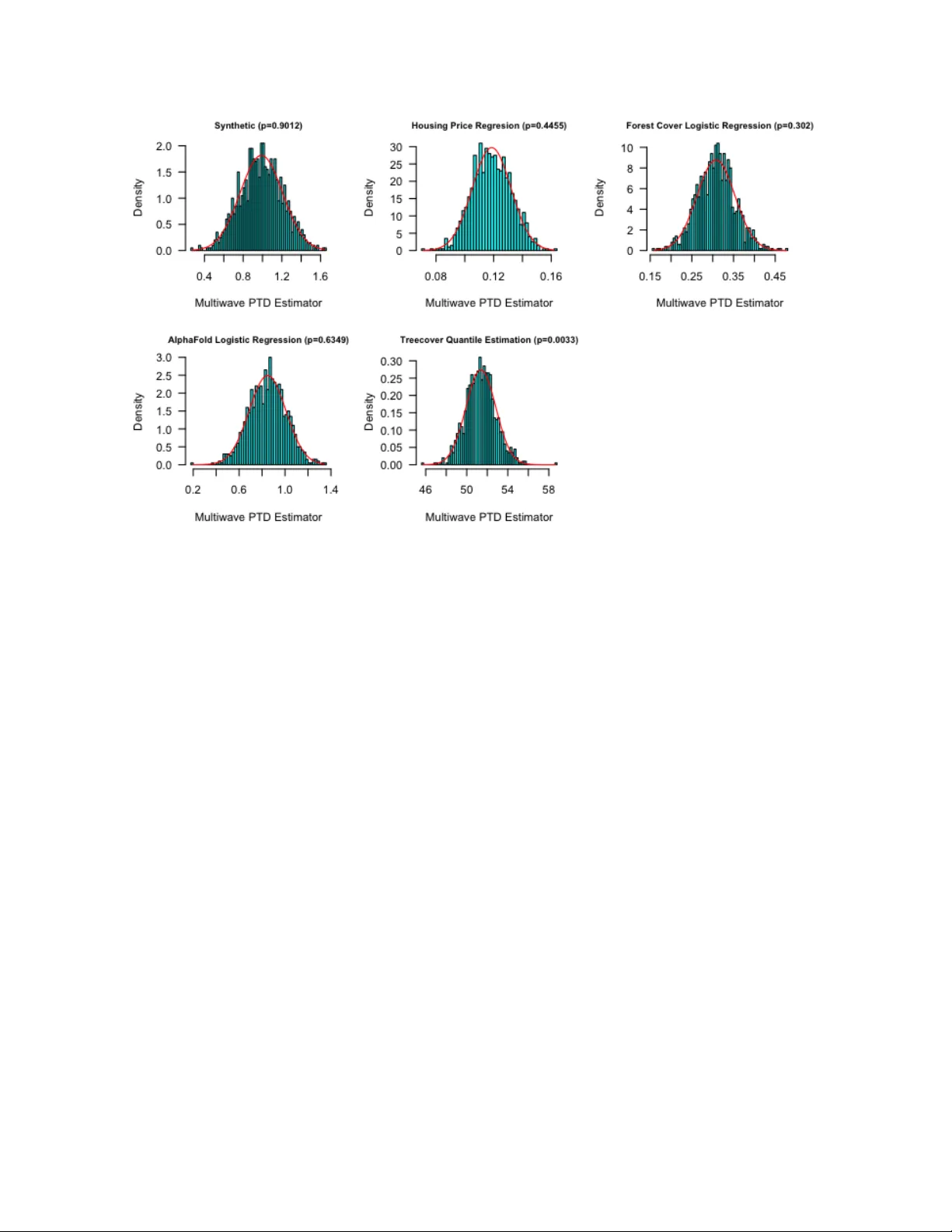
본 논문은 두 단계 다파동(멀티웨이브) 샘플링이라는 새로운 실험 설계 모델을 제시하고, 이 모델 하에서 M‑추정 문제를 해결하기 위한 통계적 방법론을 체계적으로 개발한다.
1. **문제 설정 및 배경**
- 대규모 데이터 수집이 가능하지만, 일부 핵심 변수는 측정 비용이 높아 제한된 표본에만 적용할 수 있는 상황을 다룬다. 예를 들어, 사전 학습된 머신러닝 모델이 제공하는 예측값(저비용)과 실제 실험을 통해 얻는 정밀 측정값(고비용) 사이의 차이를 보정한다.
- 기존 연구는 두 단계 샘플링을 다루지만, 대부분 사전 정의된 층화(stratified) 설계에 의존하거나, 적응적 설계에 대한 점근적 정규성 증명을 제공하지 못한다.
2. **두 단계 다파동 샘플링 프로토콜**
- **Phase I**: N개의 표본을 i.i.d.로 추출하고, 저비용 변수 ˜X_i = (X_c,i, ˜X_e,i)를 관측한다. 고비용 변수 X_e,i는 아직 측정되지 않는다.
- **Phase II**: K개의 파동을 순차적으로 진행한다. 각 파동 k에서는 이전 파동까지 축적된 데이터 D_{k−1}를 이용해 라벨링 규칙 π^{(k)} ∈ P를 학습한다. 이후 각 표본 i에 대해 Bernoulli 확률 π^{(k)}(˜X_i)로 고비용 변수 X_e,i를 측정한다. 이미 측정된 표본은 재측정하지 않는다.
3. **역확률 가중치 설계**
- 파동별 가중치 W_i^{(k)}를 정의하고, 파동 가중치 계수 c_k (∑c_k=1)를 이용해 다파동 가중치 W_i = Σ_{k} c_k W_i^{(k)}를 만든다. 이 가중치는 각 파동에서 선택된 표본에 대한 역확률 보정 역할을 하며, 토워 성질을 이용해 조건부 기대값을 단계별로 계산할 수 있게 해준다.
4. **Predict‑Then‑Debias 추정량**
- 손실 함수 l_θ(·)를 정의하고, 목표 파라미터 θ₀ = arg min_θ E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기