강화학습 기반 해밀턴 자코비 도달가능성 인증 프레임워크
본 논문은 강화학습(RL)으로 학습된 가치함수를 해밀턴‑자코비(HJ) 도달가능성 해석에 직접 연결시키는 새로운 인증 체계를 제시한다. 할인된 초기 시간 ‘여행 비용’ 모델을 이용해 작은 단계의 RL 가치 반복이 감쇠가 포함된 전방 HJ 방정식과 동등함을 보이고, 학습 오차를 일정한 오프셋으로 변환하는 ‘가산 오프셋 정리’를 도입한다. 이를 통해 균일 가치 오차가 HJB 방정식의 상수 오프셋과 정확히 일치함을 증명하고, 두 가지 경로(A) 벨먼 …
저자: Prashant Solanki, Isabelle El-Hajj, Jasper J. van Beers
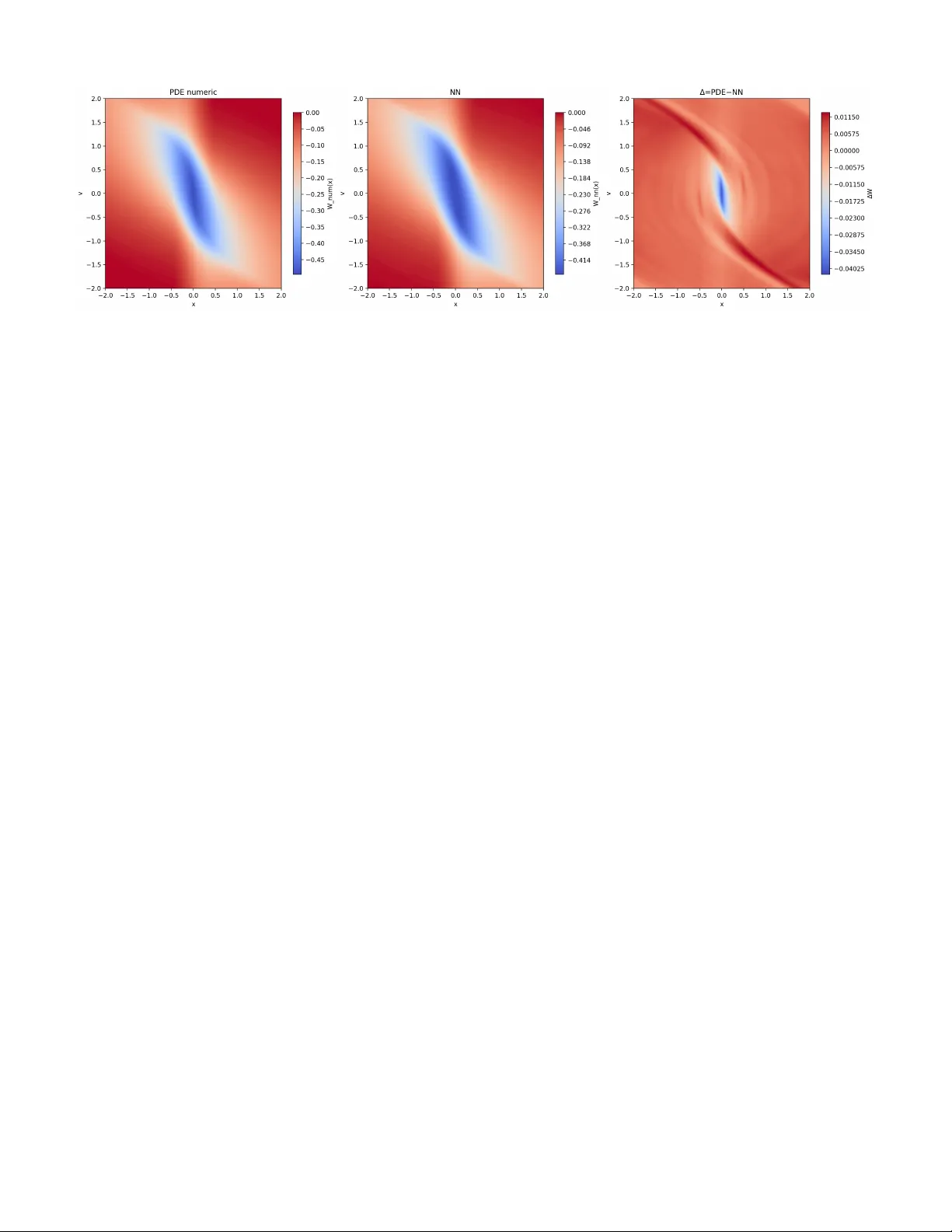
본 논문은 강화학습(RL) 기반 가치 함수 학습과 해밀턴‑자코비(HJ) 도달가능성 분석을 통합하는 새로운 인증 프레임워크를 제안한다. 전통적인 HJ 도달가능성은 최적 제어 관점에서 Hamilton‑Jacobi‑Bellman(HJB) 편미분 방정식을 풀어야 하는데, 이는 고차원 시스템에서 계산 비용이 급격히 증가한다는 한계가 있다. 반면, 최근 RL 기술은 복잡한 동적 시스템에 대해 데이터‑드리븐 방식으로 근사 가치 함수를 효율적으로 학습한다. 그러나 RL 기반 가치 함수가 실제 HJ 도달가능성 해석에 그대로 적용될 수 있는지, 그리고 안전성을 어떻게 보장할 수 있는지는 미해결 문제였다.
저자들은 이러한 격차를 메우기 위해 ‘할인된 초기 시간 여행‑비용(discounted travel‑cost)’ 모델을 도입한다. 이 모델은 초기 시간에 도달하기 위한 최소 비용을 정의하면서, 할인율 \(\lambda\) 를 포함한다. 수학적으로는 다음과 같은 HJB 방정식을 만족한다.
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기