역학 연구를 위한 머신러닝 활용 가이드
디지털 역학 시대에 방대한 데이터 분석을 위해 머신러닝 기법을 도입하는 방법을 제시한다. 감독학습·비감독학습 기본 원리와 의사결정나무, 배깅·부스팅·랜덤포레스트 등 주요 알고리즘을 설명하고, 모델 평가·하이퍼파라미터 최적화, 해석 가능성 기법을 R‑mlr3 코드와 함께 실습한다.
저자: ** *저자 정보가 본문에 명시되지 않았습니다.* (가능한 경우 원문 혹은 출판사 웹사이트에서 확인 필요) **
본 장은 디지털 역학 시대에 급증하는 고차원·대규모 데이터에 대응하기 위해 머신러닝 기법을 체계적으로 도입하는 방법을 제시한다. 서두에서는 전자건강기록, 웨어러블, 소셜미디어, 유전체 데이터 등 다양한 출처의 데이터가 역학 연구에 미치는 영향을 설명하고, 머신러닝이 모델 명시적 가정 없이 복잡한 상호작용을 자동으로 탐색할 수 있는 장점을 강조한다. 동시에 계산 비용, 해석 가능성 저하, 과적합 위험 등 한계도 명시한다.
연구 예시로 사용된 심장질환 데이터는 OpenML에서 제공되는 270명 환자의 13개 특성(연령, 흉통 유형, 혈청 콜레스테롤 등)과 이진 목표 변수(심장질환 유무)로 구성된다. 데이터 전처리, 결측치 처리, 범주형 변수 인코딩 등 기본적인 준비 과정을 부록과 GitHub 저장소에 상세히 제공한다.
2절에서는 감독학습의 기본 개념을 정의한다. 입력 공간 X ⊂ ℝ^p와 목표 공간 Y ⊂ ℝ 혹은 {1,…,C} 사이의 함수 f̂ 를 학습하는 과정으로, 손실함수 L(·) 를 최소화하는 것이 목표임을 수식적으로 제시한다. 회귀와 분류의 차이, 확률적 예측(π̂)와 결정적 예측(ŷ)의 구분, 그리고 모델 성능을 정량화하는 다양한 손실·평가지표를 간략히 소개한다.
2.1절에서는 의사결정나무(CART)를 중심으로 트리 기반 학습 방법을 상세히 설명한다. 연속형·범주형 변수에 대한 최적 분할 기준을 정의하고, Gini 불순도, 엔트로피, 평균제곱오차(MSE) 등 손실 함수와 불순도 감소 사이의 등가성을 논한다. 트리 성장 과정은 루트에서 시작해 손실 감소가 사전 정의된 임계값 이하가 될 때까지 재귀적으로 분할하는 그리디 알고리즘이며, 과적합을 방지하기 위해 최소 샘플 수, 최대 깊이, 최소 불순도 감소와 같은 정지 기준을 적용한다. 비용복잡도 프루닝(cost‑complexity pruning)에서는 트리 복잡도 |T|와 손실 L(T) 의 가중합 C_α(T)=L(T)+α|T| 을 최소화하는 서브트리를 찾는 절차를 제시하고, α 값을 교차검증으로 선택하는 실용적인 방법을 제안한다.
2.1.2절에서는 배깅과 부스팅, 그리고 랜덤포레스트를 포함한 앙상블 기법을 다룬다. 배깅은 부트스트랩 샘플링을 통해 B개의 독립적인 나무를 학습하고, 회귀에서는 평균, 분류에서는 다수결 투표로 예측을 집계한다. 이때 OOB(Out‑Of‑Bag) 샘플을 이용해 별도 검증 없이 일반화 오류를 추정할 수 있다. 부스팅은 이전 모델의 오류에 가중치를 부여해 순차적으로 약학습기를 추가함으로써 편향을 감소시키며, 학습률 η와 최대 트리 수 M 의 조합이 과적합을 제어한다. 랜덤포레스트는 배깅에 각 분할 단계에서 무작위로 q개의 특성만 고려하도록 제한함으로써 트리 간 상관관계 ρ를 감소시켜 분산을 더욱 효과적으로 억제한다. q와 B는 데이터 차원과 노이즈 수준에 따라 교차검증이나 베이지안 최적화로 튜닝한다.
3절에서는 모델 평가와 하이퍼파라미터 최적화 전략을 제시한다. k‑fold 교차검증, 반복 교차검증, OOB 오류 등 다양한 검증 프레임워크를 비교하고, ROC‑AUC, 정확도, 정밀도·재현율·F1‑score, 로그 손실 등 목적에 맞는 평가지표 선택 방법을 논한다. 하이퍼파라미터 탐색은 그리드 서치, 랜덤 서치, 베이지안 최적화(예: mlr3tuning) 등을 활용하며, 계산 비용을 절감하기 위한 멀티‑페이즈 최적화와 조기 중단(Early Stopping) 전략을 설명한다.
4절에서는 해석 가능성에 초점을 맞춘다. 변수 중요도(Mean Decrease Impurity, Permutation Importance), 부분 의존 플롯(PDP), 누적 이득(Accumulated Local Effects), SHAP(Shapley Additive Explanations) 값을 이용해 모델이 어떻게 결정을 내렸는지 시각화하고, 임상의와 정책 입안자가 결과를 신뢰할 수 있도록 하는 방법을 제시한다. 특히 트리 기반 모델은 내부 구조가 직관적이지만, 배깅·부스팅·랜덤포레스트와 같은 앙상블에서는 포스트‑hoc 해석이 필수임을 강조한다.
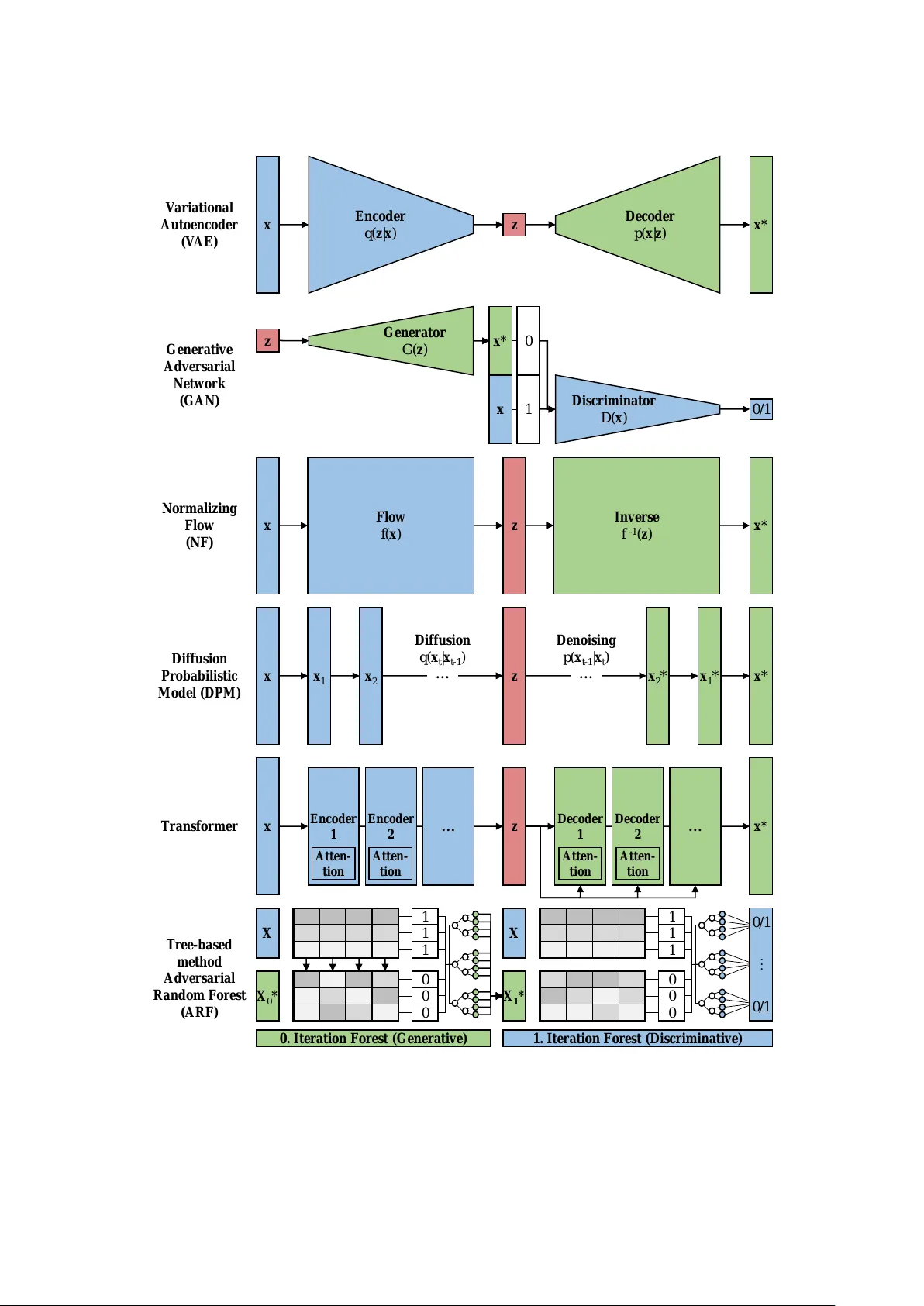
5절에서는 비감독학습과 생성 모델을 간략히 소개한다. 클러스터링(K‑means, 계층적 군집)과 차원 축소(PCA, t‑SNE, UMAP)를 통해 잠재적 위험군을 탐색하고, 변분 오토인코더(VAE)와 GAN을 활용해 합성 역학 데이터를 생성함으로써 데이터 부족 문제를 완화할 수 있음을 언급한다.
전체 흐름은 R 패키지 mlr3와 그 확장 패키지(mlr3learners, mlr3tuning, mlr3viz)를 이용해 구현한다. 각 절마다 실제 코드 스니펫을 제공하고, 심장질환 데이터에 대한 전처리 → 학습 → 튜닝 → 평가 → 해석 과정을 단계별로 재현 가능하게 만든다. 부록에는 전체 스크립트와 세션 정보, 재현성을 위한 랜덤 시드 설정이 포함되어 있다.
결론에서는 머신러닝이 역학 연구에 제공하는 기회와 한계를 요약하고, 데이터 품질 관리, 모델 검증, 해석 가능성 확보, 윤리적 고려사항을 포함한 실무 가이드라인을 제시한다. 향후 연구 방향으로는 시계열·공간 데이터에 특화된 딥러닝 모델, 연합 학습(Federated Learning) 등을 통한 개인정보 보호와 대규모 협업 분석을 제안한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기