프리트레인 모델을 활용한 약한 섀도우 변수와 결측 데이터 부분식별
본 논문은 사용자 피드백과 같은 관측치가 MNAR(무작위가 아닌 결측) 상황에서 평균 결과값을 추정하기 위한 새로운 부분식별(framework) 방법을 제시한다. 선행 학습된 모델, 특히 대형 언어 모델(LLM)의 예측값을 “약한 섀도우 변수”로 활용해 선형계획법(LP)으로 상·하한을 구하고, 이를 통해 기존 강한 가정에 의존하던 방법보다 더 넓은 적용 범위와 tighter한 구간을 제공한다. 또한 유한표본에서 식별구간의 유효성을 보장하는 집합…
저자: Hongyu Chen, David Simchi-Levi, Ruoxuan Xiong
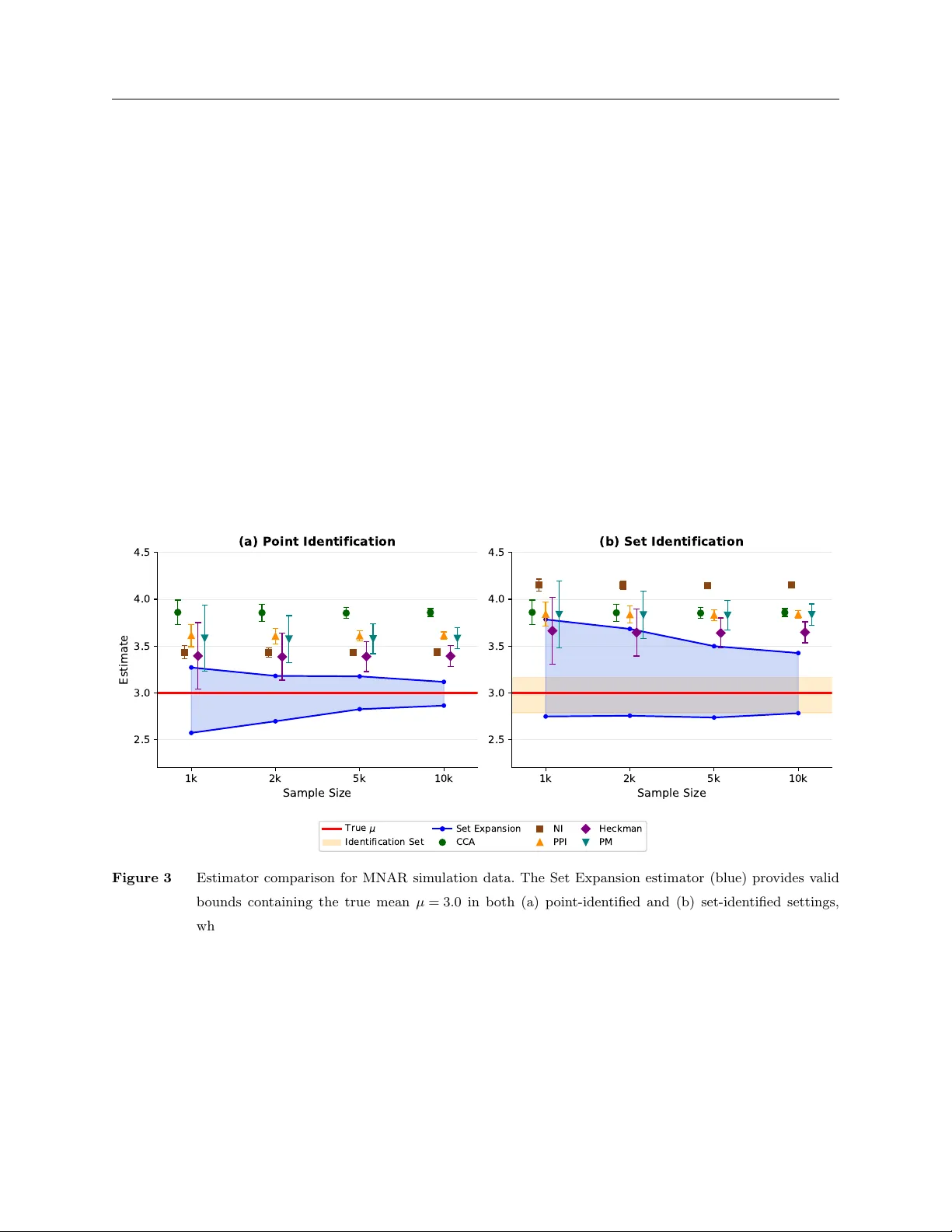
본 논문은 사용자 피드백과 같은 관측치가 무작위가 아닌 결측(MNAR) 상황에서 인구 평균과 같은 양을 추정하는 문제를 다룬다. 기존 연구는 강한 파라메트릭 가정이나 완전성을 만족하는 보조 변수를 전제로 하여 식별을 시도했지만, 실제 서비스 환경에서는 이러한 가정을 충족시키는 변수를 확보하기 어렵다. 특히, 최근 대규모 사전학습 모델, 특히 대형 언어 모델(LLM)이 제공하는 예측값은 풍부하지만, 전통적인 섀도우 변수의 완전성 조건을 만족하지 않는다.
이에 저자들은 “약한 섀도우 변수(weak shadow variable)”라는 새로운 개념을 도입한다. 약한 섀도우 변수는 결측 인디케이터와 조건부 독립성을 만족하지만, 완전성 요구는 하지 않는다. 즉, LLM이 생성한 예측값이 실제 결과와 완전한 선형 관계를 갖지 않더라도, 결측 여부와는 독립적인 정보를 제공한다는 전제이다. 이러한 약한 섀도우 변수를 활용하면, 기존 방법이 요구하는 강한 가정을 완화하면서도 식별 구간을 유의미하게 축소할 수 있다.
이론적 프레임워크는 다음과 같이 구성된다. 먼저, 관측된 데이터 $(Y_{\text{obs}}, R)$와 잠재적인 완전 데이터 분포 $P(Y,R)$를 정의한다. 여기서 $R$은 결측 인디케이터이며, $Y$는 실제 결과이다. 약한 섀도우 변수 $Z$는 사전학습 모델이 $X$(관측 가능한 공변량)로부터 예측한 값이며, $Z \perp R \mid X$라는 조건부 독립성을 만족한다. 이 조건을 선형 제약식으로 표현하면, $E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기