작은 버퍼로도 특징은 유지하지만 분류 경계는 흐려지는 경험 재생의 비대칭
본 논문은 연속 학습에서 경험 재생(Experience Replay) 버퍼가 특징 공간(깊은)과 분류기(얕은) 수준의 망각에 미치는 영향을 분석한다. 작은 버퍼라도 특징의 선형 분리성을 유지해 깊은 망각을 방지하지만, 분류 경계가 실제 데이터 분포와 맞지 않아 얕은 망각이 크게 발생한다. 이를 설명하기 위해 Neural Collapse 이론을 연속 학습에 확장하고, 버퍼 크기에 따른 클래스 평균·공분산의 변화를 수학적으로 증명한다. 결과적으로 …
저자: Giulia Lanzillotta, Damiano Meier, Thomas Hofmann
본 논문은 연속 학습(Continual Learning, CL)에서 가장 널리 쓰이는 전략인 경험 재생(Experience Replay, ER)의 효율성을 새로운 관점에서 재조명한다. 기존 연구들은 ER이 전체 모델의 파라미터를 안정화시켜 catastrophic forgetting을 완화한다는 점에 주목했지만, 실제로는 특징 공간과 분류 헤드 사이에 비대칭적인 망각 현상이 존재한다는 점을 간과했다. 저자들은 이를 “깊은 망각”과 “얕은 망각”이라는 두 축으로 구분하고, 각각이 버퍼 크기에 따라 어떻게 달라지는지를 체계적으로 조사한다.
1. **문제 정의 및 측정 지표**
- 깊은 망각은 고정된 특징 추출기(φ) 위에 선형 프로브(linear probe)를 학습했을 때 얻는 정확도(A*ij)와, 같은 시점에 네트워크 자체가 내놓는 정확도(Aij)의 차이로 정의한다.
- 얕은 망각은 동일한 방식으로 네트워크 자체 출력 정확도와 이전 작업에 대한 정확도의 차이(Aij‑Ajj)로 정의한다.
- 두 지표를 통해 각각의 망각 정도를 정량화한다.
2. **경험적 관찰: Replay Efficiency Gap**
- 다양한 버퍼 비율(0%~100%)에 대해 ResNet, ViT, 사전학습 모델을 CIFAR‑100, Tiny‑ImageNet, CUB‑200에 적용하였다.
- 결과는 일관되게 “깊은 망각은 작은 버퍼(1~5%)만으로도 거의 사라지지만, 얕은 망각은 30% 이상 큰 버퍼가 필요”함을 보여준다.
- 특히, 단일 헤드(CIL, DIL) 설정에서는 이 격차가 크게 나타나며, 멀티‑헤드(TIL)에서는 상대적으로 완화된다.
- 사전학습 모델은 초기부터 특징이 강하게 구분돼 깊은 망각이 거의 없으며, 얕은 망각만이 버퍼 크기에 민감하게 반응한다.
3. **Neural Collapse 이론의 연속 학습 확장**
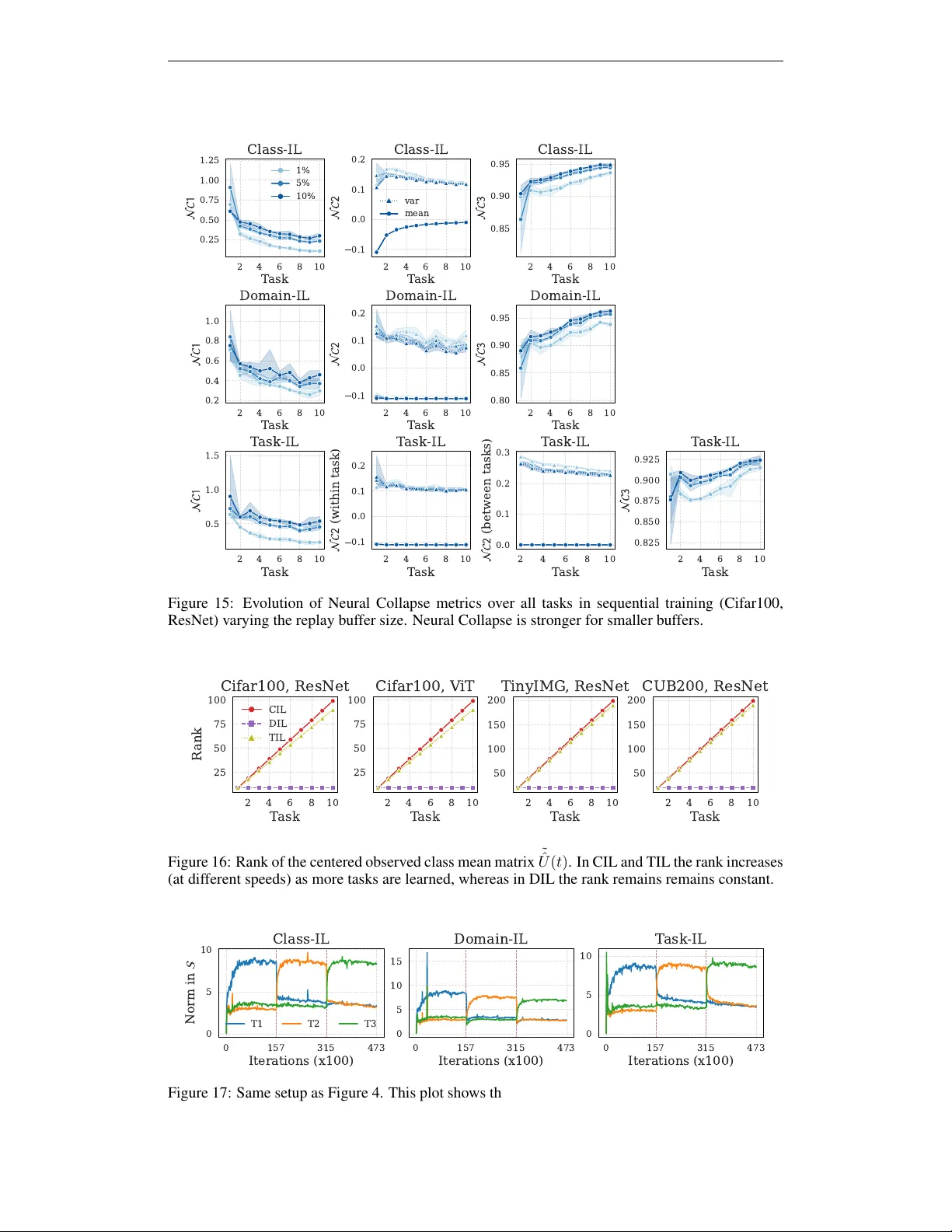
- 기존 Neural Collapse(NC) 이론은 고정된 데이터셋에서 훈련이 수렴하면 (i) 클래스 내 변동성 소멸(NC1), (ii) 클래스 평균이 ETF 형태로 정렬(NC2), (iii) 분류기 가중치가 평균에 정렬(NC3)된다고 설명한다.
- 저자들은 이를 연속 학습 상황에 적용하기 위해 “관측 통계(ˆµ)와 모집단 통계(µ)의 차이”를 도입한다. 버퍼에 저장된 샘플만으로 추정된 ˆµ는 실제 전체 분포 µ와 차이가 발생한다.
- 버퍼가 작을수록 ˆµ는 OOD(Out‑of‑Distribution) 샘플에 치우치게 되고, 이는 “강한 붕괴(strong collapse)”를 야기한다. 구체적으로, 클래스 평균의 norm이 과도하게 커지고, 공분산 행렬이 저랭크가 된다.
4. **수학적 분석**
- 선형 분리성을 SNR(신호대잡음비) = ‖µ1‑µ2‖² / Tr(Σ1+Σ2) 로 정의하고, 이를 Mahalanobis 거리의 하한으로 사용한다.
- 비제로 재생 비율 r>0이면, 장기적으로 클래스 평균 간 거리와 공분산이 일정 비율 유지돼 SNR이 양의 상수 이하로 떨어지지 않음을 정리 1에서 증명한다. 즉, “any non‑zero replay fraction asymptotically guarantees the retention of linear separability.”
- 반면, 버퍼가 작아 ˆµ와 µ 사이의 차이가 크게 되면, 공분산이 rank‑deficient가 되고 평균이 팽창한다. 이를 “strong collapse” 현상으로 명명하고, 얕은 망각을 SNR 감소와 직접 연결한다.
5. **멀티‑헤드와 글로벌 정렬**
- Task‑Incremental Learning(TIL)에서는 각 작업마다 별도 헤드가 존재한다. 실험 결과, 각 헤드 내부에서는 NC1‑NC3이 잘 유지되지만, 헤드 간 평균 벡터의 방향과 스케일이 일관되지 않아 전역적인 ETF 구조가 깨진다.
- 이는 “global misalignment”와 “rank reduction”을 초래해, 여러 헤드가 동시에 사용될 때 얕은 망각이 더욱 악화된다.
6. **실용적 해결책**
- **클래스‑균형 재생**: 버퍼 샘플을 각 클래스별로 균등하게 추출해 OOD 비율을 최소화한다. 이는 ˆµ와 µ의 차이를 줄여 강한 붕괴를 완화한다.
- **통계 보정 정규화**: 학습 중에 현재 버퍼 기반 평균과 공분산을 추정하고, 이를 이용해 클래스 평균을 스케일링하거나 공분산을 정규화한다. 실험에서는 이러한 보정이 얕은 망각을 크게 감소시키고, 전체 버퍼 크기를 5% 수준으로 유지하면서도 최종 정확도가 90% 이상 유지되는 결과를 보였다.
7. **결론 및 의의**
- 경험 재생이 특징 공간을 안정화시키는 “깊은” 측면은 매우 효율적이며, 작은 메모리로도 충분히 보장된다.
- 그러나 분류 헤드가 실제 데이터 경계와 일치하도록 만들기 위해서는 버퍼 크기와 재생 샘플의 통계적 특성을 동시에 고려해야 한다.
- 본 연구는 CL와 OOD 탐지 분야를 연결함으로써 “망각”을 단순 정확도 감소가 아닌, 특징·통계·분류기 사이의 구조적 변화를 포괄적으로 이해하는 새로운 프레임워크를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기