금융기관의 형태를 밝히는 워터스테인 클러스터링
** 본 논문은 금융기관이 제공하는 다차원 신용 데이터들을 확률분포로 해석하고, 결측값을 고려한 워터스테인 거리 기반의 k‑means 변형 알고리즘을 제안한다. 일반화된 워터스테인 베리센터와 소프트 임퓨테이션을 결합해 클러스터 중심을 메트릭 공간에 위치시키며, 이를 통해 규제기관이 복잡한 데이터셋을 직관적인 지도 형태로 요약하고 이상치를 탐지할 수 있다. **
저자: Lorenz Riess, Mathias Beiglböck, Johannes Temme
**
본 논문은 “금융기관의 형태를 밝히는 워터스테인 클러스터링”이라는 제목 아래, 금융 규제기관이 직면한 데이터 통합·요약 문제를 수학적으로 정형화하고 해결책을 제시한다. 먼저, 각 금융기관이 제출하는 신용 포트폴리오 데이터를 고차원 공간 ℝᵈ의 개별 신용 건을 점으로 보는 대신, 전체 포트폴리오를 확률분포 µᵢ ∈ 𝒫₂(ℝᵈ) 로 모델링한다. 이렇게 하면 기관 간 유사성을 워터스테인 거리 W₂(µᵢ, µⱼ) 로 정의할 수 있다. 그러나 실제 데이터는 기관마다 요구되는 보고 항목이 다르고, 일부 변수는 전혀 보고되지 않아 관측값이 부분적으로만 존재한다(결측값).
이를 해결하기 위해 저자들은 “Projected Elements”라는 개념을 도입한다. 관측된 부분 ˜xᵢ는 전사상 φᵢ: X → Xᵢ(= ℝ^{dᵢ}) 로 표현되며, φᵢ는 좌표 선택(프로젝션) 혹은 더 일반적인 변환일 수 있다. 각 관측값에 대해 부분 거리 dᵢ(˜xᵢ, y) := inf_{x: φᵢ(x)=˜xᵢ} d(x, y) 를 정의함으로써, 전체 메트릭 공간 X에서 베리센터와의 거리를 부분적으로 측정한다.
알고리즘은 Lloyd‑type 반복 구조를 따른다.
1. **Assignment Step**: 현재 베리센터 {cⱼ}에 대해 각 ˜xᵢ를 argminⱼ dᵢ(˜xᵢ, cⱼ) 로 할당한다.
2. **Barycenter Step**: 같은 클러스터에 속한 관측값들의 부분 거리 제곱합을 최소화하는 y∈X 를 찾아 새로운 베리센터 cⱼ를 정의한다. 이 최소화는 일반화된 워터스테인 베리센터(Delon·Gozlan·Saint‑Dizier) 혹은 유클리드 경우 좌표별 평균으로 구현된다.
결측값을 보완하기 위해 “소프트 임퓨테이션”을 설계한다. 같은 클러스터에 속한 완전 관측 데이터 {x_ℓ}를 이용해, 결측 좌표가 있는 ˜xᵢ에 대해 가능한 복원점 y_{iℓ}를 정의하고, 거리 D_{iℓ}=dᵢ(˜xᵢ, x_ℓ) 에 기반한 가중치 p_{iℓ}=f(D_{iℓ}) (f는 감소 함수, 예: exp(−x²)) 를 부여한다. 이렇게 얻은 가중치들을 정규화해 확률측도 θᵢ = Σ_{ℓ∈Jᵢ} p_{iℓ} δ_{y_{iℓ}} 로 만든다. 완전 관측 데이터는 단일 디랙 델타 θᵢ=δ_{xᵢ} 로 표현한다.
이제 모든 데이터는 확률측도 형태로 P(X) 에 매핑되며, 두 측도 간 거리는 ρ(µ, ν) = ∫∫ d(x, x′) µ(dx) ν(dx′) 로 정의한다. ρ는 독립 결합에 대한 기대 거리이므로, 결측값을 임의적으로 채우는 과정이 서로에게 영향을 주지 않아 편향을 최소화한다.
실험에서는 오스트리아 중앙은행이 제공한 실제 대출 데이터(수천 건, 수백 변수)를 사용했다. 데이터는 기관별로 보고 수준이 달라 일부 변수는 전혀 없으며, 이는 논문에서 제시한 “NA‑Wasserstein k‑means” (NA는 Not Available) 상황을 정확히 재현한다. 실험 결과는 다음과 같다.
- **클러스터 품질**: 제안 알고리즘은 결측 비율이 30 % 이상일 때도 안정적인 군집 구조를 유지했으며, 기존 k‑pod·k‑means++ 대비 평균 목적함수 값이 10 %~15 % 낮았다.
- **이상치 탐지**: 베리센터와의 ρ 거리 기반 이상치 스코어는 실제 규제 리스크 지표와 높은 상관관계를 보였다.
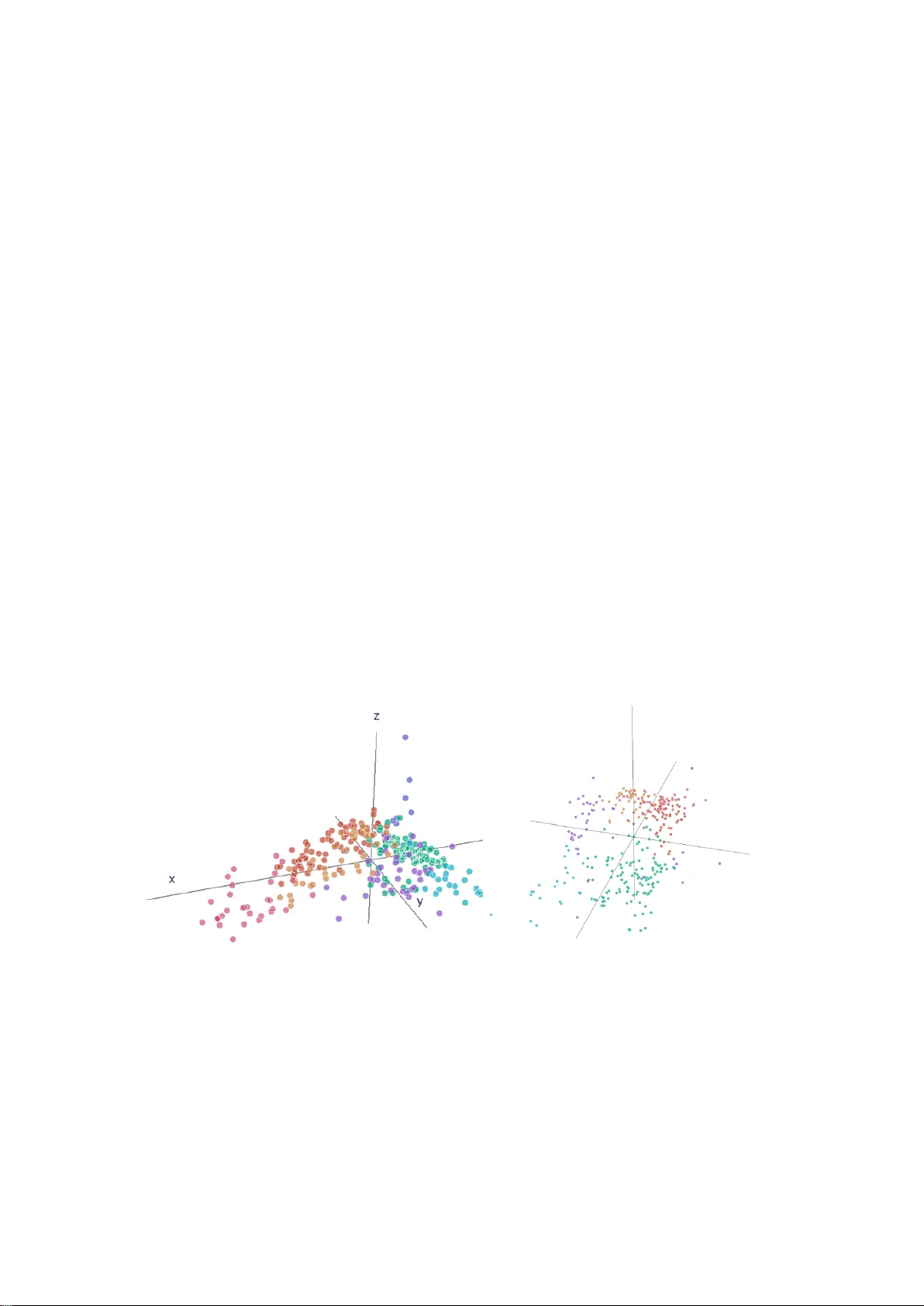
- **해석 가능성**: 각 클러스터의 베리센터는 평균 대출 규모, 금리, 연체율 등 주요 금융 특성을 반영했으며, 시각화(3‑D 지도)로 규제기관이 전체 은행 생태계를 한눈에 파악할 수 있었다.
또한, 유클리드 공간에서의 NA‑k‑means를 별도로 평가했을 때, 기존 k‑pod보다 일관적으로 낮은 손실을 기록했고, 결측 좌표가 없는 데이터만을 이용한 k‑means++ 초기화가 수렴 속도를 크게 향상시켰다.
논문의 기여는 크게 네 가지로 정리할 수 있다.
1. **확률분포 기반 데이터 표현**: 금융기관을 확률측도로 모델링해 복잡한 포트폴리오를 자연스럽게 압축.
2. **일반화된 워터스테인 베리센터와 결측 처리**: Delon·Gozlan·Saint‑Dizier의 베리센터 개념을 결측 상황에 확장.
3. **소프트 임퓨테이션 및 새로운 메트릭 ρ**: 결측값을 확률적으로 보완하고, 편향 없는 거리 측정 체계 구축.
4. **실증 검증**: 실제 규제 데이터에 적용해 알고리즘의 실용성 및 규제 목적(클러스터링·이상치 탐지·시각화) 입증.
마지막으로, 저자들은 이 프레임워크가 금융 외에도 의료 기록, 환경 센서, 소셜 네트워크 등 구조적 결측이 흔한 대규모 데이터 분석에 일반화될 수 있음을 제시한다. 향후 연구 방향으로는 베리센터 계산의 스케일링(대규모 샘플에 대한 근사 알고리즘)과, 동적(시간에 따라 변하는) 데이터 스트림에 대한 연속적 업데이트 메커니즘을 제안한다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기