다국어와 멀티모달을 아우르는 음악 검색 시스템 CLaMP 2
CLaMP 2는 101개 언어를 지원하고 ABC 표기와 MIDI를 동시에 처리하는 대규모 멀티모달 음악 정보 검색 모델이다. 150만 개의 ABC‑MIDI‑텍스트 삼중항을 사전학습하고, GPT‑4로 정제한 다국어 설명을 활용해 텍스트 노이즈를 크게 감소시켰다. 다국어 텍스트 인코더(XLM‑R)와 확장된 M3 기반 음악 인코더를 대비학습(contrastive learning)으로 정렬함으로써, 다언어 의미 검색 및 음악 분류에서 최첨단 성능을 달…
저자: Shangda Wu, Yashan Wang, Ruibin Yuan
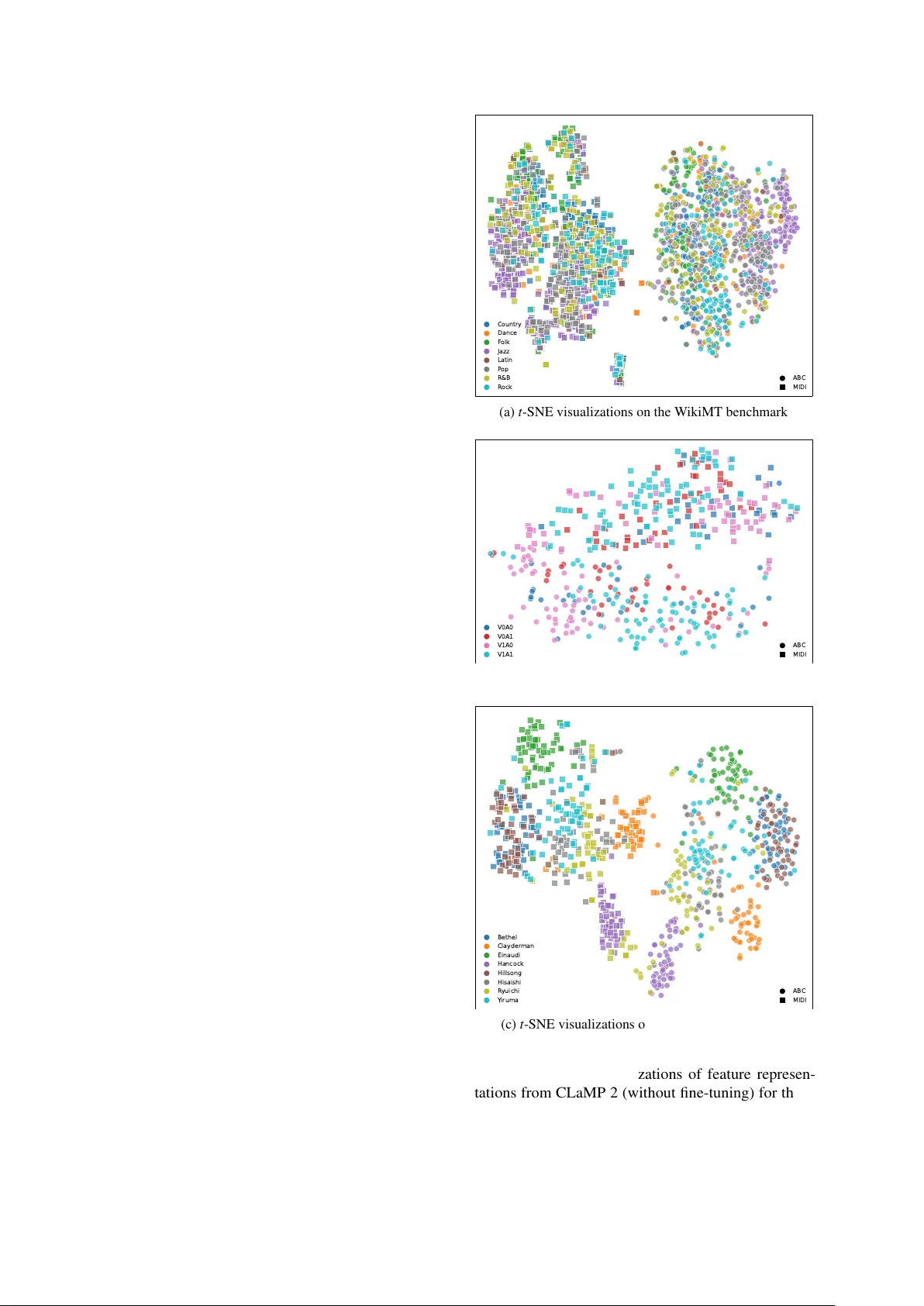
본 논문은 전 세계 사용자를 위한 포괄적인 음악 정보 검색(MIR) 시스템을 목표로, 언어 다양성과 음악 표기 다양성을 동시에 다루는 CLaMP 2 프레임워크를 제안한다. 먼저, 저자들은 기존 MIR 데이터셋이 영어 중심이며 비영어 텍스트가 극히 적어 다국어 검색 성능이 제한된다는 문제를 제시한다. 이를 해결하기 위해 GPT‑4를 활용해 원본 메타데이터를 정제하고, 100개 이상의 비영어 언어에 대해 고품질 설명을 자동 생성한다. 이 과정에서 텍스트 노이즈를 크게 감소시키고, 언어 분포를 균등화하여 다국어 텍스트 인코더가 학습할 수 있는 균형 잡힌 코퍼스를 확보한다.
텍스트 인코더는 XLM‑R‑base(270 M 파라미터)를 사용해 101개 언어를 동시에 처리한다. 입력 텍스트는 최대 128 토큰으로 제한하고, 앞·뒤·중간 세 가지 방식으로 무작위 트렁케이션하여 편향을 방지한다. 또한 원본 텍스트, LLM‑생성 영어 설명, LLM‑생성 비영어 설명을 각각 50 %·25 %·25 % 비율로 샘플링해 학습한다.
음악 인코더는 기존 M3 모델을 기반으로 확장하였다. M3는 바 패치를 이용한 셀프‑슈퍼바이즈드 구조로, 이번 연구에서는 패치 레벨 인코더를 12층, 디코더를 3층으로 깊이를 늘리고, 히든 사이즈를 768로 설정했다. ABC 표기는 음성‑인터리브 형태로 재구성해 다트랙 악보를 효율적으로 표현하고, MIDI는 손실 없는 텍스트 포맷(MTF)으로 변환해 동일한 패치 단위로 처리한다. 이렇게 함으로써 두 형식 간의 표현 차이를 최소화하고, 하나의 멀티모달 인코더가 두 데이터를 동시에 학습하도록 설계했다.
대조학습은 ABC‑MIDI‑텍스트 삼중항을 이용한다. 각 학습 스텝에서 음악 측면은 ABC 또는 MIDI 중 하나를 무작위 선택하고, 텍스트는 원본·LLM‑생성 영어·LLM‑생성 비영어 중 지정된 비율로 입력한다. 악기 정보는 90 % 확률로 제거해 악기‑특정 편향을 억제하고, 텍스트 드롭아웃을 적용해 과적합을 방지한다. 손실 함수는 텍스트‑음악 쌍의 유사성을 높이고, 비쌍의 유사성을 낮추는 대비 손실(InfoNCE)이다.
데이터는 Million MIDI Dataset(1.5 M MIDI)와 WebMusicText(1.4 M ABC‑텍스트)에서 추출했으며, 서로를 ABC와 MIDI로 변환해 3 M 삼중항을 구성했다. 변환 과정에서 일부 성능 정보가 손실될 수 있으나, 다양한 형식의 혼합은 모델의 일반화 능력을 크게 향상시켰다.
실험에서는 다국어 의미 검색(Mean Reciprocal Rank, Recall@K)과 음악 분류(Genre, Composer, Mood) 두 가지 주요 태스크에서 평가했다. CLaMP 2는 기존 최첨단 모델 대비 평균 5 % 이상의 성능 향상을 보였으며, 특히 저자원 언어에서 10 % 이상 개선되었다. 또한, 단일 모델이 ABC와 MIDI 모두에서 높은 정확도를 유지함을 확인했다.
결론적으로, CLaMP 2는 대규모 다국어 텍스트와 멀티모달 음악 데이터를 효과적으로 정렬함으로써, 전 세계 사용자가 자신의 모국어로 음악을 검색하고 분류할 수 있는 새로운 표준을 제시한다. 향후 연구에서는 음성 입력, 실제 사용자 인터랙션 로그 등을 추가해 더욱 풍부한 멀티모달 MIR 시스템을 구축할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기