딥러닝으로 최적 상태피드백 학습하기
본 논문은 최적 궤적으로부터 생성된 상태‑제어 쌍을 이용해 심층 신경망을 학습시켜, 2차원 쿼드콥터의 최적 상태피드백을 근사하는 방법을 제시한다. 소프트플러스 활성화 함수를 도입해 제어 신호의 부드러움을 확보하고, 평균 절대 오차와 실제 정책 성능 사이의 불일치를 다양한 지표로 분석한다.
저자: Dharmesh Tailor, Dario Izzo
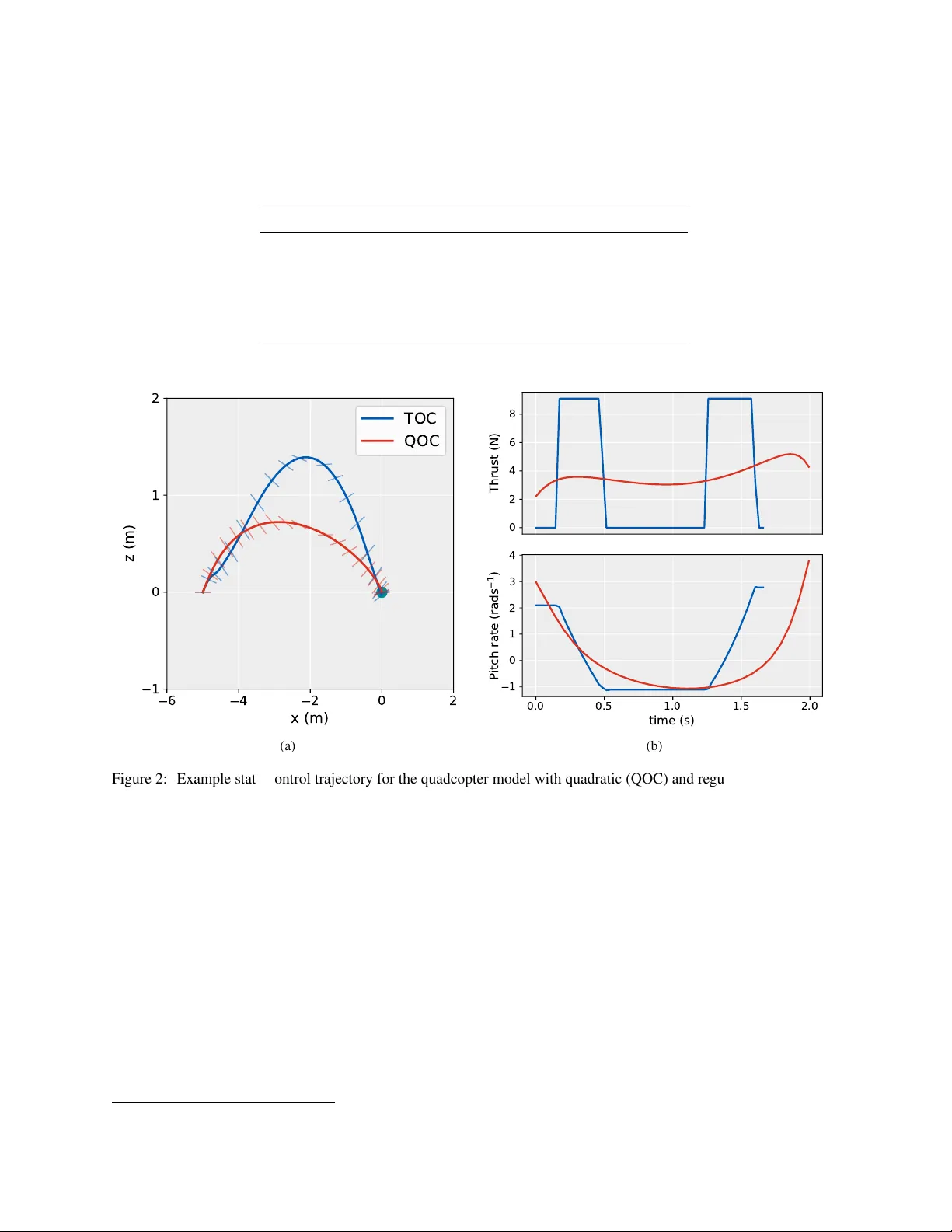
본 논문은 최적 제어 문제를 해결하기 위한 새로운 모방 학습 파이프라인을 제시한다. 먼저, 저자들은 2차원 쿼드콥터 모델(상태 변수 x, z, vₓ, v_z, θ와 제어 입력 F_T, ω)을 정의하고, 두 가지 비용 함수—제곱 제어 비용과 시간 최소화 비용—에 대해 직접 전사와 Hermite‑Simpson 콜로케이션을 이용해 최적 궤적을 생성한다. 시간 최소화 문제에서는 제어 진동(chattering)과 급격한 플립을 방지하기 위해 ω²에 대한 가중치를 추가하고, θ 제한을 도입해 궤적을 규제한다. 이렇게 얻어진 200 000개의 초기 상태에 대한 최적 궤적은 각 궤적을 균일한 시간 그리드(2K‑1=59점)로 샘플링해 총 약 1.2 억 개의 상태‑제어 쌍을 만든다. 데이터는 90 %를 학습, 10 %를 테스트용으로 분할하고, 평균·분산 정규화를 수행한다.
신경망 설계에서는 완전 연결 피드포워드 구조를 채택하고, 은닉층 활성화 함수로 소프트플러스(softplus)를 사용한다. 소프트플러스는 ReLU와 달리 미분 가능성이 높아 깊은 네트워크에서도 기울기 소실을 완화하고, 출력이 부드러운 연속 함수를 제공한다. 출력층은 tanh를 사용해 제어 입력을
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기