가중치 샘플링 기반 오디오 적대적 예제 공격
본 논문은 자동음성인식(ASR) 시스템을 목표로 하는 오디오 적대적 예제 생성의 효율성과 견고성을 동시에 향상시키는 두 가지 새로운 기법, 가중치 교란 기술(WPT)과 샘플링 교란 기술(SPT)을 제안한다. WPT는 변형이 필요한 핵심 구간에 높은 가중치를 부여해 학습 속도를 가속화하고, SPT는 전체 샘플 중 일부만 교란함으로써 외부 잡음에 대한 내성을 높인다. 또한 손실 함수에 디노이징 항을 추가해 인간이 인지하기 어려운 저노이즈 공격을 구…
저자: Xiaolei Liu, Xiaosong Zhang, Kun Wan
본 논문은 자동음성인식(ASR) 시스템을 대상으로 하는 오디오 적대적 예제 생성의 효율성과 견고성을 동시에 개선하고자 한다. 기존 연구들은 주로 이미지 분야에 초점을 맞추어 왔으며, 오디오 영역에서는 Carlini‑Wagner(2018)와 같은 방법이 높은 성공률을 보였지만, 생성에 1시간 이상이 소요되고, 외부 잡음에 취약해 실제 환경에서의 활용도가 낮았다. 이러한 문제점을 C1(시간 소모), C2(노이즈에 취약), C3(손실 함수 설계 부재)로 정리하고, 이를 해결하기 위한 두 가지 핵심 기술을 제안한다.
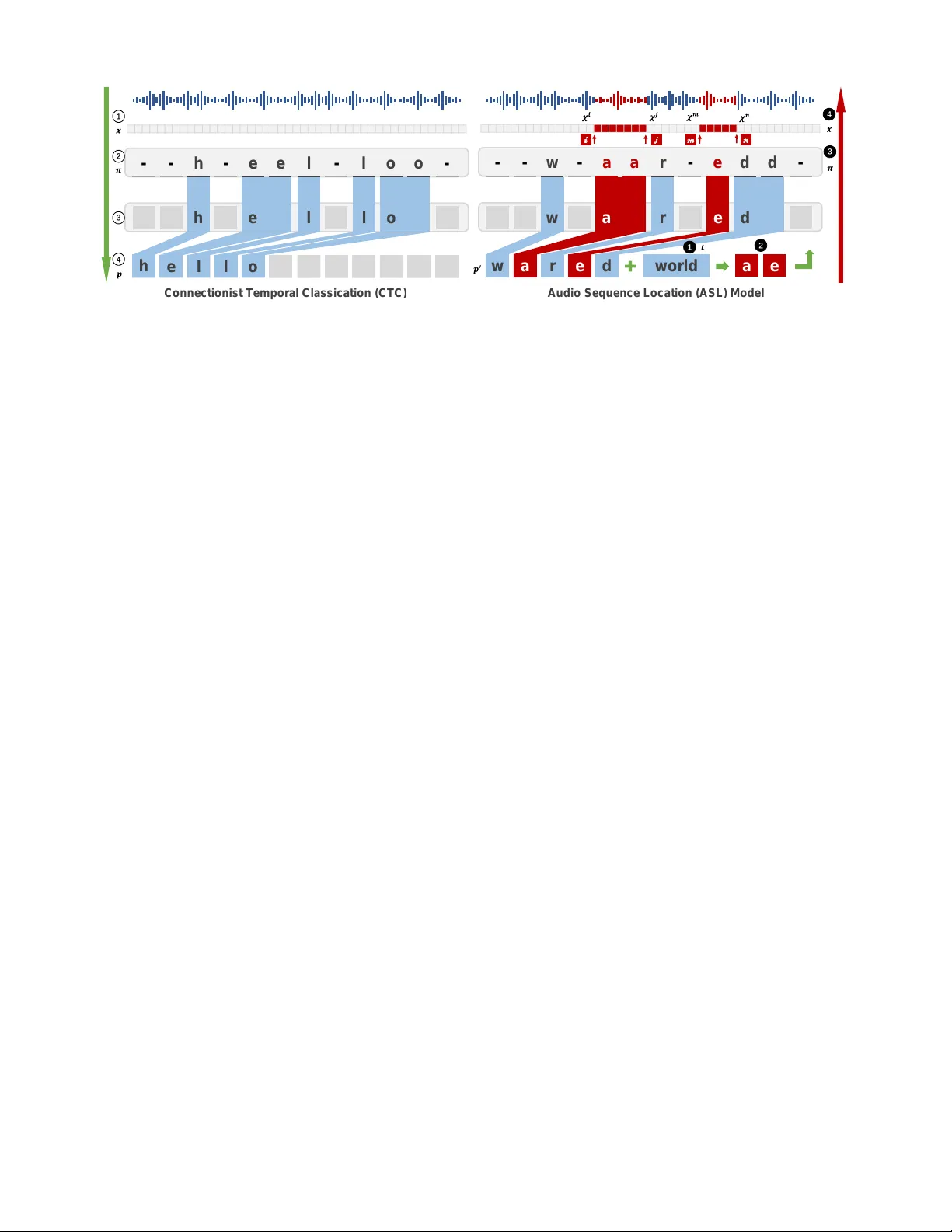
첫 번째 기술인 가중치 교란 기술(Weighted Perturbation Technology, WPT)은 CTC 기반 디코딩 과정에서 Levenshtein 거리가 1 이하로 감소할 때 발생하는 반복적인 미세 조정 비용을 줄이는 데 목적을 둔다. 이를 위해 Audio Sequence Location(ASL) 모듈을 설계하였다. ASL은 현재 디코딩된 문장 p₀와 목표 문장 t를 비교하여 차이가 나는 문자들을 식별하고, 해당 문자들이 매핑된 토큰 시퀀스 π에서의 위치를 찾아 오디오 벡터 x의 구간 χ_k를 추출한다. 추출된 구간에 가중치 ω(>1)를 부여함으로써 해당 구간의 교란 강도를 높이고, 전체 학습률을 β(0<β<1)로 점진적으로 감소시켜 과도한 교란을 방지한다. 이 과정은 greedy decoder와 beam‑search decoder 모두에 적용 가능하도록 설계되었으며, 기존 Carlini‑Wagner 방식이 필요로 하는 초기 feasible solution x₀를 요구하지 않는다. 따라서 전체 최적화 과정에서 55 % 이상을 차지하던 Levenshtein 거리 감소 단계의 시간을 크게 절감한다.
두 번째 기술인 샘플링 교란 기술(Sampling Perturbation Technology, SPT)은 전체 오디오 프레임 n 중 실제로 교란이 필요한 프레임 m만을 선택적으로 교란한다. CTC 손실을 수식적으로 전개하면 목표 문장의 확률 Pr(p|y)는 모든 토큰 시퀀스 π∈Q(p,y)의 확률 곱의 합으로 표현된다. 여기서 전체 프레임을 교란하지 않고도 특정 토큰 집합만 교란하면 동일한 Pr(p|y)를 얻을 수 있음을 보였다. 따라서 m≪n인 상황에서도 목표 텍스트를 정확히 유도할 수 있다. 이 접근법은 원본 오디오와 거의 동일한 청각적 특성을 유지하게 하며, 외부 잡음이 추가될 경우 교란된 프레임 비율이 낮아져 견고성이 크게 향상된다. SPT는 EO‑T(Expectation Over Transformation)와 달리 특정 잡음 분포에 대한 사전 지식 없이도 일반적인 환경 잡음에 대한 내성을 제공한다.
손실 함수는 기존 CTC‑loss 외에 `metric` 항을 추가하여 SNR, 주관적 청취 차이 등을 정량화한다. 특히 디노이징 항을 포함시켜 인간이 인지하기 어려운 저노이즈 교란을 구현한다. 전체 손실은 ` (x,δ,t)=`model(f(x+α·δ),t)+c·`metric(x,x+δ) 로 정의되며, α는 χ_k에 해당하는 위치에 ω를 곱한 가중치 벡터이다.
실험은 오픈소스 ASR 모델인 DeepSpeech를 위협 모델로 채택하고, 기존 Carlini‑Wagner, CommanderSong, Qin 등과 동일한 데이터셋과 설정에서 비교하였다. 평가 지표는 SNR, Word Error Rate(WER), Success Rate, Robustness Rate를 사용하였다. 결과는 다음과 같다. (1) 평균 생성 시간은 4~5분으로 기존 1시간 이상 소요되는 방법에 비해 90 % 이상 단축되었다. (2) SNR은 평균 30 dB 이상으로 기존 방법보다 5~8 dB 향상되었다. (3) Success Rate는 95 % 이상, Robustness Rate는 다양한 잡음 변환(T) 하에서 80 % 이상을 유지하였다. (4) WPT와 SPT는 서로 보완적으로 작용하여, WPT가 초기 수렴을 가속화하고 SPT가 최종 교란량을 최소화함으로써 전체 성능을 최적화한다.
또한, 제안된 두 기술은 기존 공격 파이프라인에 플러그인 형태로 쉽게 통합될 수 있다. WPT는 현재 디코딩 결과에 따라 동적으로 가중치를 조정하므로, 다양한 디코더와 손실 함수에 적용 가능하고, SPT는 교란 대상 프레임을 선택하는 모듈만 교체하면 된다. 따라서 향후 물리적 환경(스피커‑마이크 재생)이나 다른 RNN 기반 ASR 모델에도 확장 가능성이 높다.
결론적으로, 본 연구는 오디오 적대적 예제 생성에서 시간 효율성, 저노이즈, 견고성이라는 세 가지 핵심 요구사항을 동시에 만족시키는 새로운 프레임워크를 제시한다. 가중치 교란과 샘플링 교란이라는 두 축을 통해 기존 방법 대비 실질적인 성능 향상을 입증했으며, 향후 ASR 보안 연구 및 방어 메커니즘 설계에 중요한 참고 자료가 될 것으로 기대한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기