실시간 스테레오 보컬 제거를 위한 경량 딥러닝 모델
본 논문은 메모리와 연산량이 제한된 환경에서도 실시간으로 스테레오 음악에서 보컬을 제거하고 반주를 복원할 수 있는 경량 모델인 Vox‑TasNet을 제안한다. 기존의 단일채널 Conv‑TasNet을 스테레오 입력·출력 구조로 확장하고, 새로운 스테레오 비대칭성 지표(SSA‑SI‑SDR)를 도입해 좌·우 채널 간 감쇠 불일치를 정량화한다. 내부 데이터셋 A·B·C와 공개 MUSDB 데이터셋을 활용한 실험에서, 파라미터 수가 10 % 수준인 Vox…
저자: Clara Borrelli, James Rae, Dogac Basaran
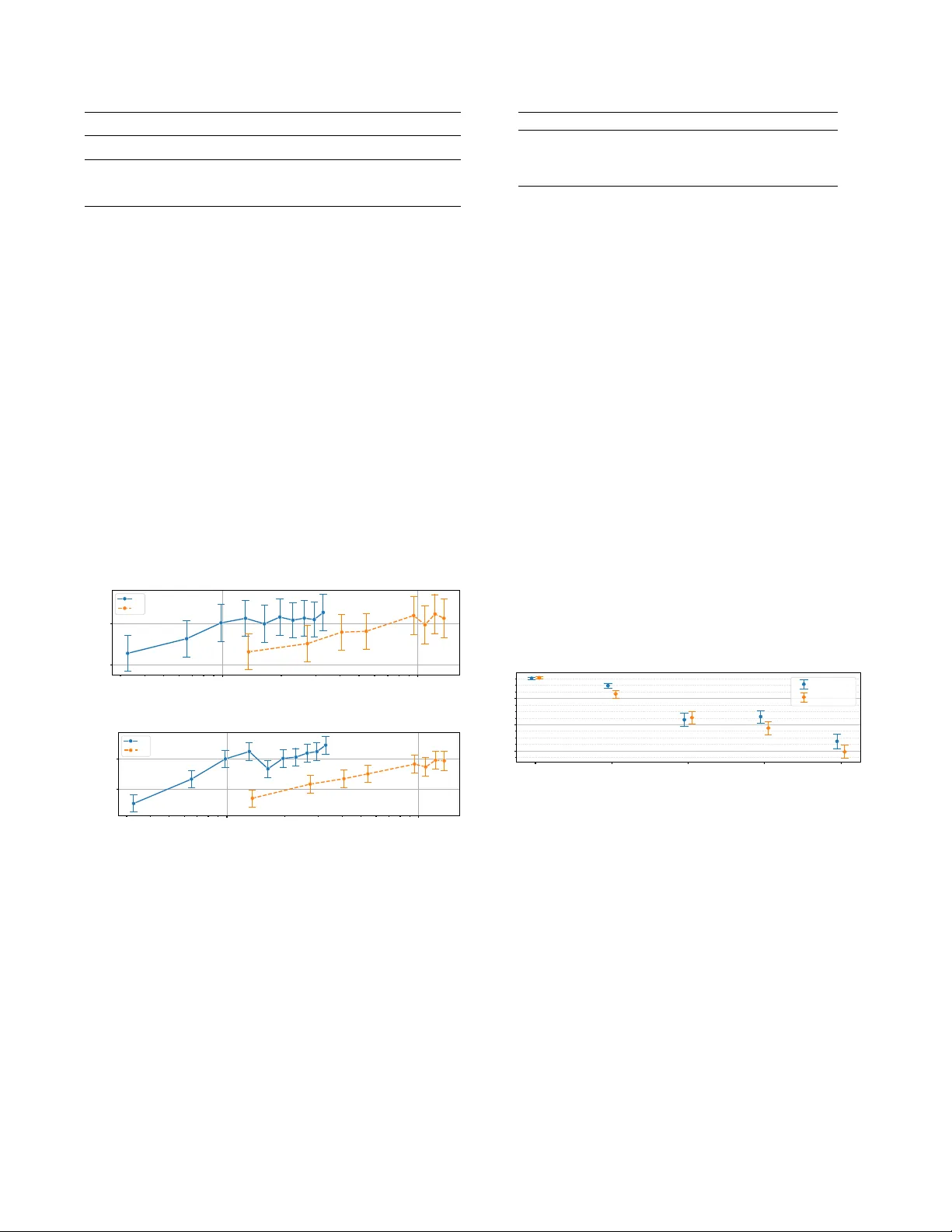
본 논문은 스테레오 보컬 캔슬레이션(SVC)을 실시간으로 수행할 수 있는 경량 딥러닝 모델을 제안한다. SVC는 음악 믹스에서 보컬을 제거하고 반주만을 복원하는 작업으로, 기존의 음악 소스 분리(MSS)와 달리 하나의 목표(반주)만을 추출한다. 최근의 대형 모델들은 높은 SI‑SDR과 주관적 청취 품질을 달성했지만, 메모리·연산 제한이 있는 엣지 디바이스에서는 비현실적이다. 따라서 저자는 Conv‑TasNet 기반의 마스크 기반 구조를 스테레오 입력·출력에 맞게 변형한 Vox‑TasNet을 설계하였다.
**1. 관련 연구**
MSS 분야에서는 U‑Net 기반 스펙트럼 모델, Wave‑Net 기반 파형 모델, Demucs와 같은 하이브리드 구조가 주류를 이룬다. 그러나 이들 대부분은 비인과성(전체 신호 접근)과 대규모 파라미터를 전제로 한다. 반면, 음성 분리 분야에서는 Conv‑TasNet이 1‑D 인코더·디코더와 TCN 기반 Separator로 경량화에 성공했으며, 이를 음악 분야에 적용한 연구가 있다. 본 논문은 이러한 경량화 아이디어를 스테레오 SVC에 적용한다.
**2. 모델 설계**
- **Encoder**: 2‑D 컨볼루션(채널 × 시간)으로 좌·우 채널을 동시에 인코딩한다. 커널 크기(1, 64), 스트라이드(1, 32)로 시간 해상도를 1/32로 감소시킨다.
- **Separator**: 여러 그룹의 S‑Conv 블록을 쌓는다. 각 블록은 depth‑wise separable convolution과 dilation을 결합해 넓은 수용 영역을 확보한다. 첫 그룹만 비인과성을 허용해 look‑ahead를 0.37 s로 제한한다. 기존 Conv‑TasNet의 skip connection을 제거해 메모리 사용량을 절감하였다.
- **Decoder**: 2‑D 트랜스포즈 컨볼루션을 통해 인코더와 동일한 차원으로 복원하고, 마스크와 곱해 최종 스테레오 반주를 출력한다.
전체 파라미터는 7.5 M으로, HybridDemucs(80 M)의 10 % 수준이다.
**3. 스테레오 비대칭성 지표(SSA‑SI‑SDR)**
보컬 억제 정도가 좌·우 채널에서 다를 경우 청취자는 비자연스러운 스테레오 이미지를 경험한다. 이를 정량화하기 위해 프레임 단위 SI‑SDR을 좌·우 각각 계산하고, 절대 차이의 평균을 SSA‑SI‑SDR이라 정의한다. 값이 작을수록 채널 간 일관성이 높다.
**4. 데이터셋 및 학습**
내부 데이터셋 A(3 290곡), B(3 797곡), C(13 625곡)와 공개 MUSDB(150곡)를 사용한다. A와 B는 전문가가 선별한 고품질 트랙이며, C는 규모는 크지만 라벨 품질이 낮다. 학습은 44.1 kHz, 4 s 길이 샘플을 무작위 추출해 배치 사이즈 6, 500 epoch, Adam(lr = 1e‑4, decay = 0.99)로 진행한다. 손실은 시간‑도메인 L1(0.875)과 멀티‑해상도 스펙트럼 L1(0.125)의 가중합이다.
**5. 실험 결과**
- **객관적 평가**: SI‑SDR 기준으로 Vox‑TasNet(A) = 12.79 dB(MUSDB), 11.64 dB(B) 를 기록했으며, SSA‑SI‑SDR은 각각 1.10 dB, 1.08 dB 로 크게 낮았다. 이는 스테레오 일관성이 크게 향상된 결과다. 파라미터 대비 성능은 HybridDemucs와 근접한다.
- **데이터 규모·품질 영향**: 훈련 데이터 양이 늘어날수록 SI‑SDR이 상승했지만, 동일 규모라면 고품질 A가 C보다 우수했다. 이는 라벨 품질이 모델 성능에 결정적임을 보여준다.
- **모노 vs 스테레오**: Mono‑Vox‑TasNet과 비교했을 때 SI‑SDR 평균값은 차이가 없었으나 SSA‑SI‑SDR은 스테레오 모델이 약 70 % 낮았다. 즉, 전체 품질은 비슷하지만 스테레오 일관성에서 큰 차이를 만든다.
- **주관적 MUSHRA**: 99명의 청취자가 10 s 클립에 대해 0‑100 점수로 평가했다. HybridDemucs가 최고였으며, Vox‑TasNet과 Mono‑Vox‑TasNet이 Conv‑TasNet보다 현저히 높은 점수를 받았다. 특히 내부 데이터셋 I에서는 스테레오 모델이 모노 모델보다 통계적으로 유의미하게 높은 점수를 얻었다.
**6. 결론 및 시사점**
Vox‑TasNet은 파라미터 7.5 M, look‑ahead 0.37 s, 메모리 사용량 최소화라는 제한 하에서도 대형 비실시간 모델과 비슷한 SI‑SDR을 달성한다. 스테레오 인코더·디코더 설계와 SSA‑SI‑SDR 지표 도입을 통해 채널 간 일관성을 정량화하고 개선하였다. 데이터 품질이 양보다 중요하다는 실험 결과는 향후 데이터 수집·라벨링 전략에 중요한 가이드를 제공한다. 본 연구는 모바일·임베디드 환경에서 실시간 음악 프로세싱, 특히 보컬 제거 기반의 리믹싱, 카라오케, 라이브 스트리밍 등에 적용 가능한 실용적 솔루션을 제시한다. 향후 연구에서는 트랜스포머 기반 경량화, 다중 스테레오 방위(예: 5.1) 확장, 그리고 사용자 맞춤형 라우팅을 탐색할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기