효율적인 신경 이미지 압축을 위한 계층형 사전과 적응형 공간 해상도
본 논문은 Swin Transformer 기반의 변환 코딩에 채널‑별 자동회귀 사전 모델을 결합한 ICT 구조와, 학습 가능한 스케일링 네트워크와 ConvNeXt 전·후처리를 포함한 AICT 모델을 제안한다. 전역·국부 컨텍스트를 동시에 활용해 양자화 잠재 변수의 분포를 정밀히 추정하고, 적응형 해상도 조절을 통해 압축 효율과 디코딩 지연을 크게 개선한다. 실험 결과 VTM‑18.0 및 기존 Transformer 기반 코덱 대비 BD‑Rate를…
저자: Ahmed Ghorbel, Wassim Hamidouche, Luce Morin
본 논문은 신경 이미지 압축(NIC) 분야에서 현재 ConvNet 기반 엔트로피 코딩이 지역적인 연결 구조 때문에 장거리 종속성을 충분히 모델링하지 못한다는 문제점을 지적한다. 이러한 한계를 극복하고자 저자들은 두 단계의 주요 기여를 제시한다. 첫 번째는 기존 Swin Transformer 기반 변환 코딩 프레임워크인 SwinT‑ChARM을 개선한 이미지 압축 Transformer(ICT)이다. ICT는 Swin Transformer 블록을 이용해 입력 이미지를 비선형 변환하고, 잠재 표현(latent)에서 전역적인 상관관계를 포착한다. 여기에 채널‑별 자동회귀 사전(ChARM)을 도입해 각 채널을 순차적으로 조건부 확률로 모델링함으로써 양자화된 잠재 변수의 분포를 정밀하게 추정한다. 이 과정은 전역‑국부 컨텍스트를 동시에 활용해 압축 효율을 크게 높인다.
두 번째 기여는 ICT 위에 적응형 이미지 압축 Transformer(AICT)를 구축한 것이다. AICT는 학습 가능한 스케일링 네트워크와 ConvNeXt 기반 전·후처리 모듈을 “샌드위치” 형태로 결합한다. 스케일링 네트워크는 입력 이미지의 복잡도와 내용에 따라 최적의 리사이징 비율 s(0~1)를 예측하고, 이 값을 미분 가능하게 적용한다. 전·후처리 ConvNeXt 모듈은 리사이징 전후의 특징을 강화하여 압축된 잠재 코드가 보다 풍부한 정보를 담도록 돕는다. 결과적으로 더 작은 비트스트림으로도 높은 재구성 품질을 달성한다.
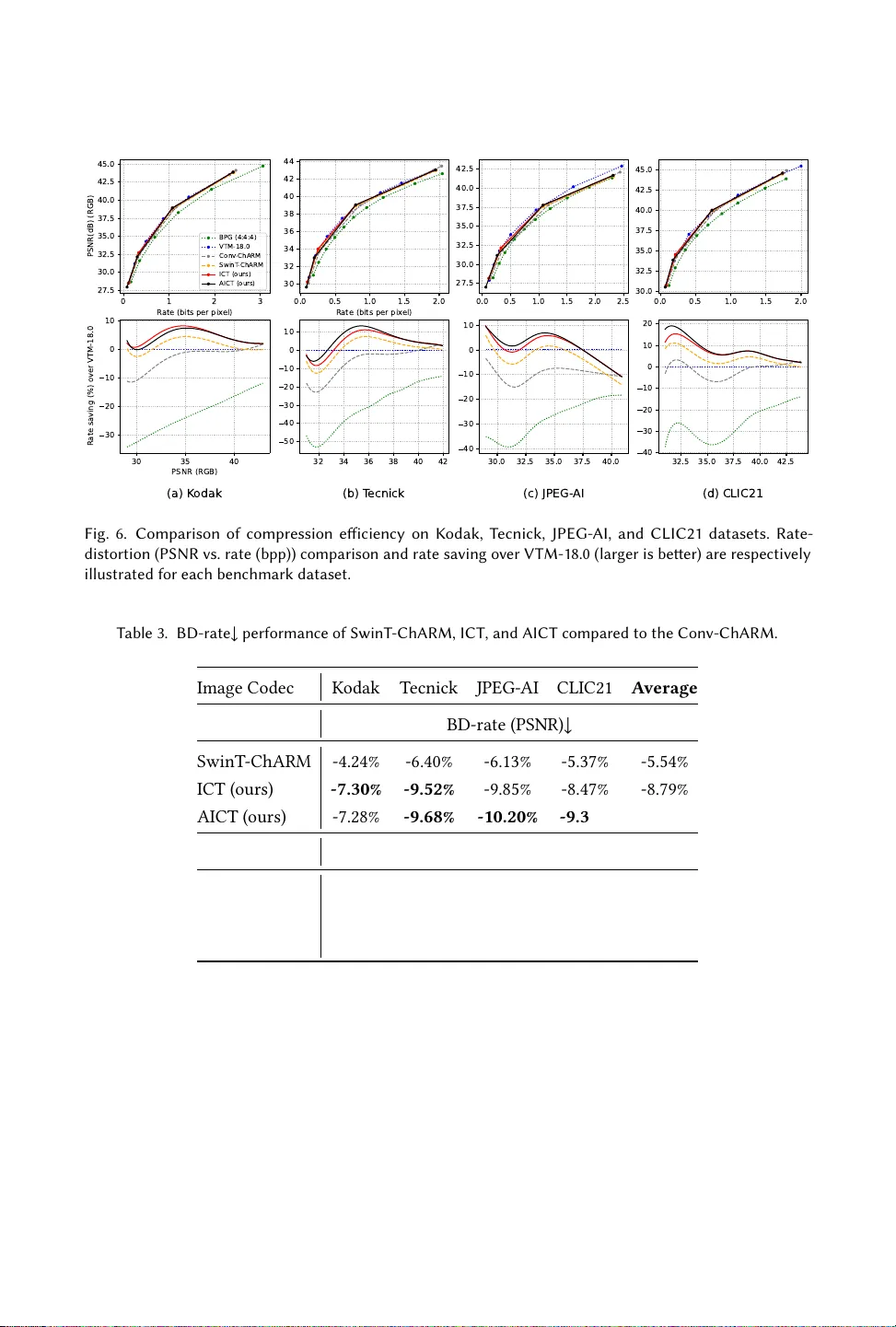
실험에서는 Kodak, Tecnick, CLIC, DIV2K 등 네 가지 공개 데이터셋을 대상으로 BD‑Rate(PSNR)와 BD‑Rate(MS‑SSIM) 지표를 측정하였다. ICT는 VTM‑18.0 대비 –4.65 %의 BD‑Rate 감소를, AICT는 –5.11 %의 감소를 기록했으며, 기존 SwinT‑ChARM 대비도 유의미한 개선을 보였다. 또한 디코더 복잡도와 실행 시간 측면에서 ConvNet 기반 및 기존 Transformer 기반 코덱보다 현저히 낮은 지연을 나타냈다.
모델 스케일링 연구에서는 파라미터 수를 0.5배, 1배, 2배로 변형했을 때도 압축 효율이 크게 손실되지 않으며, 연산량 대비 성능 비율이 우수함을 확인하였다. Ablation 실험에서는 (1) 채널‑별 자동회귀 사전을 제거하면 BD‑Rate가 약 2 % 악화되고, (2) 스케일링 모듈 없이 고정 해상도만 사용하면 재구성 품질이 저하되는 것을 보여, 두 구성요소가 각각 독립적으로도, 결합했을 때도 압축 성능에 중요한 역할을 함을 입증한다.
논문은 또한 학습 과정에서 사용된 손실 함수, 양자화 기법, 그리고 엔트로피 모델링에 대한 상세한 수식과 구현 세부사항을 제공한다. 특히, 양자화 오차를 최소화하기 위한 가우시안 혼합 모델(GMM)과 체크보드 형태의 병렬 가능한 컨텍스트 모델을 결합해 디코딩 속도를 크게 향상시켰다.
결론적으로, 전역‑국부 자기‑주의를 활용한 Transformer 기반 변환 코딩과 내용‑의존적 적응형 해상도 조절을 결합함으로써, 압축 효율, 재구성 품질, 디코딩 지연이라는 세 가지 핵심 목표를 동시에 달성하는 균형 잡힌 신경 이미지 압축 프레임워크를 제시한다. 향후 연구에서는 더 높은 해상도와 실시간 스트리밍 환경에 적용하기 위한 경량화와 하드웨어 최적화 방안을 탐색할 수 있을 것으로 기대한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기