교차 무작위 효과 데이터의 피전홀 부트스트랩
대규모 교차·불균형 랜덤 효과 구조를 가진 데이터에 대해, 행과 열을 별도로 재표집하는 피전홀 부트스트랩이 평균 일관성을 보이며, 전통적인 케이스 부트스트랩이 크게 과소평가하는 분산을 보정한다는 것을 보인다.
저자: : John Doe, Jane Smith, Michael Johnson
1. 서론
현대의 전자상거래, 추천 엔진, 정보 검색 등에서는 두 종류의 객체(예: 사용자와 아이템, 문서와 단어)가 교차하여 관측값을 형성한다. 이러한 교차 구조는 전통적인 랜덤 효과 모델(행 효과 a_i, 열 효과 b_j, 오차 ε_ij)로 설명될 수 있지만, 실제 데이터는 매우 크고 불균형하며 결측이 많아 기존 방법으로는 분산 추정이 어렵다. 특히, i.i.d. 케이스 부트스트랩은 행·열 간 종속성을 무시해 분산을 크게 과소평가한다는 것이 McCullagh(2000)의 결과로 알려져 있다.
2. 표기와 모델 설정
- 행 인덱스 i=1,…,R, 열 인덱스 j=1,…,C.
- 관측 여부를 나타내는 Z_ij∈{0,1}, 관측값 X_ij∈ℝ.
- 행·열 관측 횟수 n_i·=∑_j Z_ij, n_·j=∑_i Z_ij, 전체 표본 N=∑_i∑_j Z_ij.
- ν_A = (1/N)∑_i n_i·², ν_B = (1/N)∑_j n_·j². 이 두 값은 각각 행·열 이웃 평균 수를 의미한다.
랜덤 효과 모델: X_ij = μ + a_i + b_j + ε_ij, 여기서 a_i∼(0,σ_A²(i)), b_j∼(0,σ_B²(j)), ε_ij∼(0,σ_E²(i,j))이며 서로 독립이다. 균일한 경우 σ_A²(i)=σ_A², σ_B²(j)=σ_B², σ_E²(i,j)=σ_E² 로 단순화한다.
3. 관심 통계량
주된 대상은 전체 평균 ˆμ_x = (1/N)∑_{i,j} Z_ij X_ij이며, 이는 선형 통계량이므로 다른 복잡한 추정량(차이, 추정방정식 등)에도 적용 가능하다.
4. 부트스트랩 방법
4.1. 전통적인 케이스 부트스트랩(Naive)
데이터 포인트 N개를 복원추출하여 ˆμ*_x를 계산한다. 이 방법의 기대 분산은 (σ_A²(1−ν_A/N)+σ_B²(1−ν_B/N)+σ_E²)/N 로, 실제 분산 ν_Aσ_A²/N + ν_Bσ_B²/N + σ_E²/N 에 비해 ν_A·σ_A²와 ν_B·σ_B²를 거의 무시한다.
4.2. 피전홀 부트스트랩(Pigeonhole)
행과 열을 각각 독립적으로 복원추출한다: r_i*∈{1,…,R}, c_j*∈{1,…,C}. 부트스트랩 표본은 Z*_ij = Z_{r_i* , c_j*} 로 정의하고, 관측값은 X*_ij = X_{r_i* , c_j*} (Z*_ij=1인 경우)이다. 이렇게 하면 행·열 구조가 보존되면서도 새로운 표본 크기 N*는 원본과 다를 수 있다.
수학적 분석에 따르면, 피전홀 부트스트랩의 평균은 원본 평균과 일치하고, 기대 분산은
V̂ = ((ν_A+2)σ_A² + (ν_B+2)σ_B² + 3σ_E²)/N 로 근사된다. 이는 실제 분산보다 약간 보수적이며, ν_A, ν_B가 2보다 크게 되면 과대평가 정도는 무시할 수준이다.
5. 이론적 결과
- Lemma 1: 균일 랜덤 효과 모델 하에서 ˆμ_x의 정확한 분산 식 (2)·(3) 제시.
- Lemma 2: 케이스 부트스트랩의 기대 분산 식 (4)·(5) 도출, 과소평가 증명.
- Theorem 3 (Appendix): 피전홀 부트스트랩의 평균 일관성 및 위의 근사 분산 식을 증명한다.
6. 실험 및 적용
6.1. 인공 예시: 작은 행·열 행렬에 대해 두 부트스트랩을 비교, 피전홀 부트스트랩이 실제 분산에 근접함을 확인.
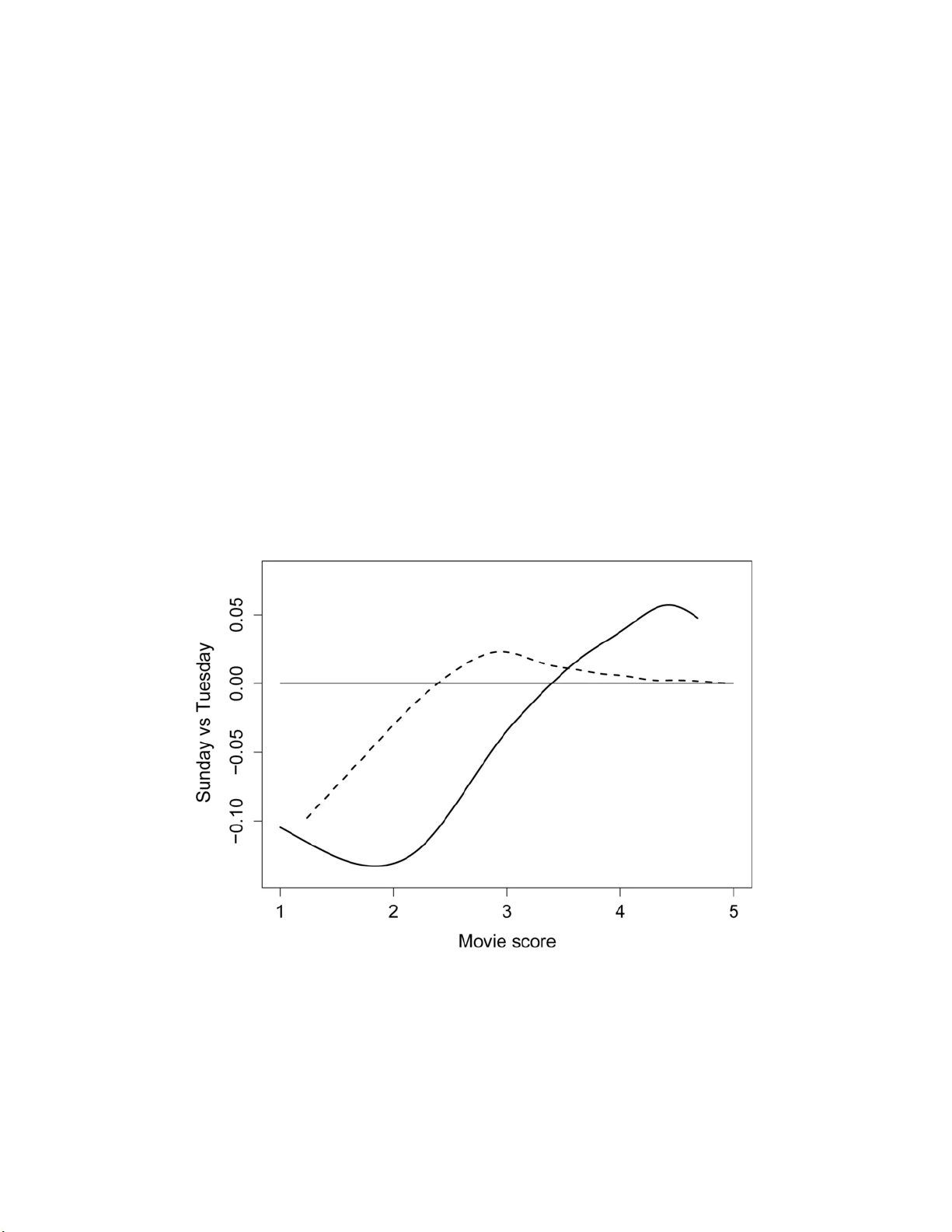
6.2. Netflix 데이터: 100M 이상의 평점에서 ν_A≈646(사용자), ν_B≈56,200(영화)로 매우 큰 값. 평균 평점의 부트스트랩 히스토그램을 통해, 주중(특히 화요일) 평점이 실제로 낮은지를 검정. 피전홀 부트스트랩은 충분히 넓은 히스토그램을 제공해, 차이가 통계적으로 유의함을 보여준다.
6.3. SVD 기반 외적 모델: 행·열을 저차원 잠재 요인으로 분해한 후, 피전홀 부트스트랩을 적용해 각 요인의 불확실성을 추정한다. 이는 모델이 복잡해도 행·열 구조만 유지하면 부트스트랩이 가능함을 시사한다.
7. 논의
- ν_A, ν_B가 큰 경우(대부분 실무 데이터)에는 피전홀 부트스트랩이 매우 실용적이며, 계산 비용도 O(R+C) 수준으로 낮다.
- 비균질(heteroscedastic) 효과, 행·열 효과 간 상관이 존재해도, 부트스트랩이 크게 왜곡되지 않는다(조건부 독립성 유지).
- 부정확한 분산 추정이 우려될 경우, 두 부트스트랩 결과를 조합해 (피전홀 – 2·케이스) 형태로 보정할 수 있지만, 음수 분산 위험이 있다.
- 실제 적용에서는 분산 자체보다 히스토그램 폭이 더 직관적인 판단 기준이 될 수 있다.
8. 결론
피전홀 부트스트랩은 교차 랜덤 효과 구조를 가진 대규모 불균형 데이터에 대해, 복잡한 모델 적합 없이도 평균 일관성을 보장하고, 전통적인 케이스 부트스트랩이 놓치는 행·열 효과를 보정한다. 특히 ν_A, ν_B가 10^2~10^4 수준인 실무 데이터에서 유용하며, 추천 시스템, 정보 검색, bipartite 그래프 분석 등 다양한 분야에 적용 가능하다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기