연속시간 비선형 시스템 최적 제어를 위한 수렴 보장 완화형 액터‑크리틱
** 본 논문은 연속시간 비선형 시스템의 무한 시간 최적 제어 문제를 해결하기 위해, 초기 정책의 허용성이나 입력‑선형성에 의존하지 않는 새로운 강화학습 기반 알고리즘인 RCTAC(Relaxed Continuous‑Time Actor‑Critic)를 제안한다. 두 단계(워밍‑업 단계와 일반화 정책 반복 단계)로 구성되며, Lyapunov 이론을 통해 수렴 및 근접 최적성을 증명하고, 시뮬레이션 및 실제 차량 경로 추적 실험을 통해 실효성을 …
저자: Jingliang Duan, Jie Li, Qiang Ge
**
본 논문은 연속시간(non‑discrete) 비선형 시스템의 무한 시간 최적 제어 문제를 다루며, 기존 동적 프로그래밍(DP)이나 ADP/강화학습(RL) 접근법이 갖는 두 가지 주요 제한을 극복하는 새로운 알고리즘 RCTAC(Relaxed Continuous‑Time Actor‑Critic)를 제안한다.
1. **문제 정의 및 기존 한계**
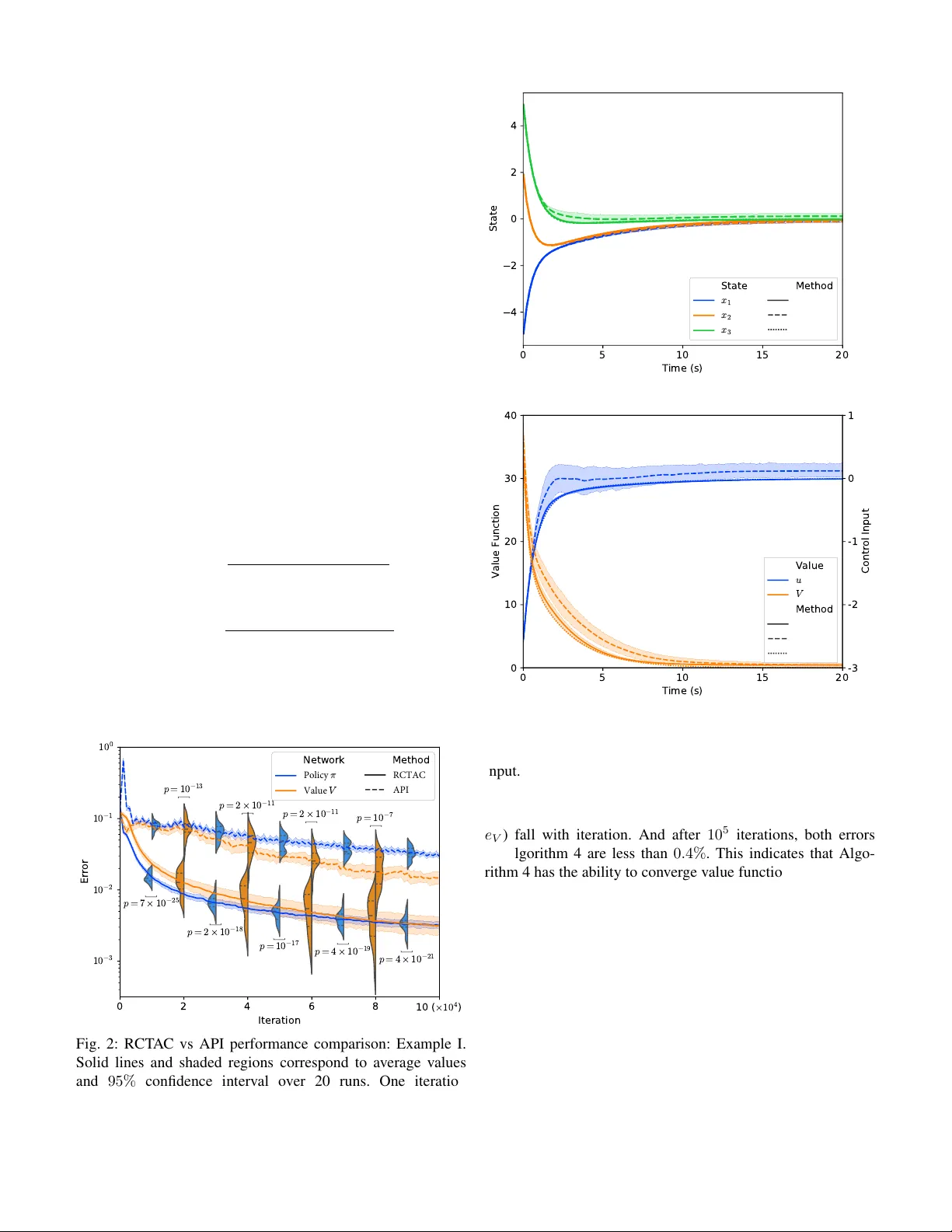
- 시스템은 \(\dot x = f(x,u)\) 형태이며, 상태 \(x\in\mathbb{R}^n\), 입력 \(u\in\mathbb{R}^m\)는 포화 제약을 포함할 수 있다.
- 목표는 비용 \(l(x,u)\)를 최소화하는 무한 시간 정책 \(\pi(x)\)를 찾는 것이며, 이는 HJB 방정식 \(\min_u H(x,u,\nabla V)=0\)을 풀어야 함을 의미한다.
- 기존 연속시간 ADP는 (A1) 초기 정책이 admissible(안정)해야 하고, (A2) 시스템이 입력‑선형이어야 한다는 전제에 크게 의존한다. 복잡한 비선형·비선형 입력 시스템에서는 초기 정책을 설계하기 어려우며, 최적 정책을 직접 구하기 힘들다.
2. **RCTAC 알고리즘 설계**
- **두 단계 구조**:
- **워밍‑업 단계**: 현재 정책 \(\pi_{\theta}\)가 안정화되지 않은 경우, Hamiltonian \(H(x,\omega,\theta)=l(x,\pi_{\theta}(x))+\nabla V_{\omega}(x)^\top f(x,\pi_{\theta}(x))\)의 제곱을 최소화하는 critic loss \(L_c = \mathbb{E}
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기