대칭 부분군 불변성을 갖는 효율적인 신경망 설계
본 논문은 임의의 유한 퍼뮤테이션 부분군 \(G\le S_n\)에 대해 \(G\)-불변 함수를 근사할 수 있는 경량 신경망 구조를 제안한다. 핵심은 \(G\)-불변 변환 모듈( \(G\)-equivariant 입력 네트워크 + 합-곱 레이어 \(\Sigma\Pi\) )이며, 이를 통해 얻은 불변 잠재 표현을 다층 퍼셉트론(MLP)으로 처리한다. 저자는 이 구조가 모든 연속 \(G\)-불변 함수를 근사할 수 있음을 증명하고, 기존의 Maron 등…
저자: Piotr Kicki, Mete Ozay, Piotr Skrzypczynski
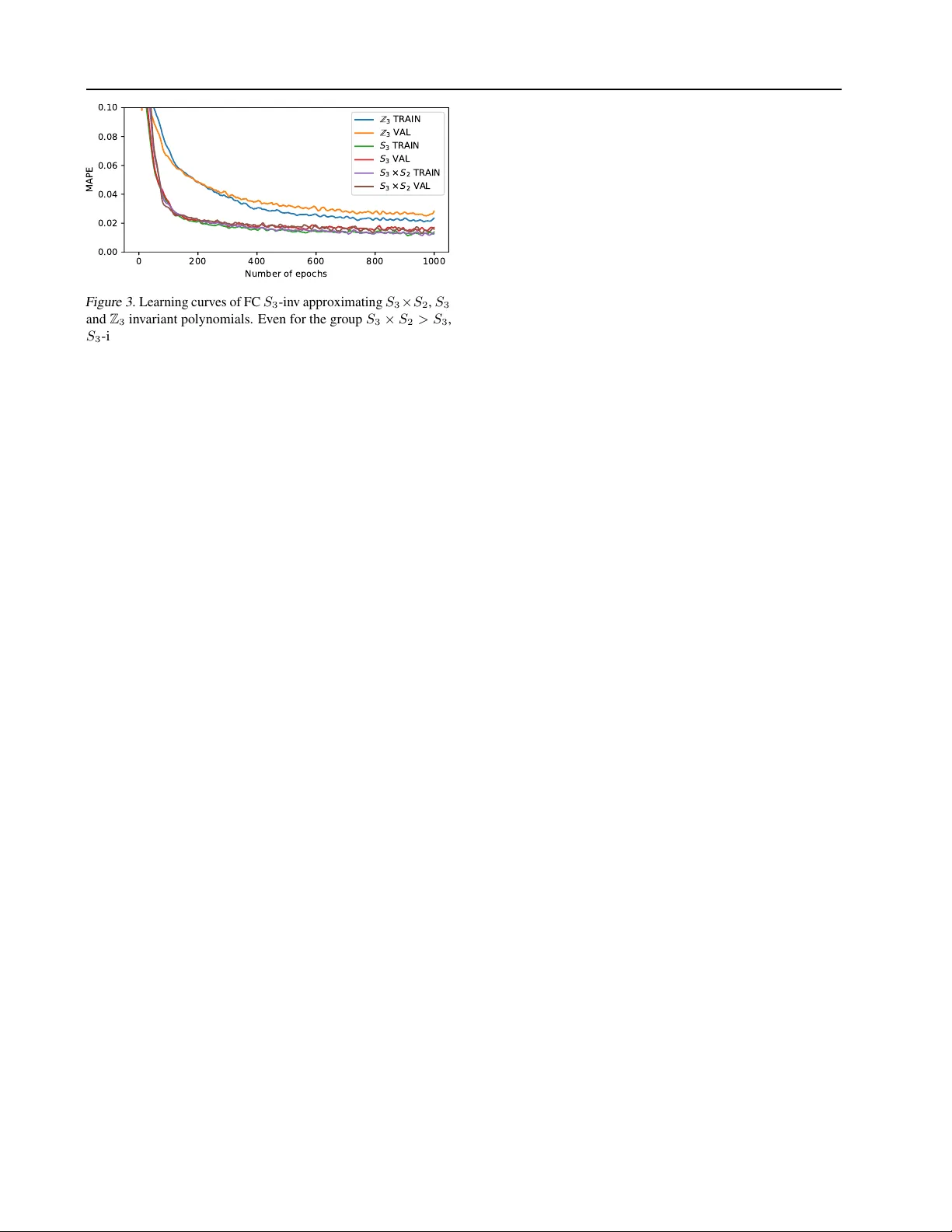
본 논문은 입력 데이터에 존재하는 퍼뮤테이션 대칭을 활용해 파라미터 효율적인 \(G\)-불변 신경망을 설계하는 방법을 제시한다. 여기서 \(G\)는 대칭군 \(S_n\)의 유한 부분군이며, \(G\)-불변 함수는 모든 \(g\in G\)에 대해 \(f(g(x))=f(x)\) 를 만족한다. 기존 연구들(예: Maron et al., 2019)은 \(G\)-불변성을 보장하기 위해 모든 그룹 원소에 대해 텐서를 복제하거나 고차원 텐서 연산을 수행했지만, 이는 \(|G|\)가 커질수록 메모리와 연산 비용이 급증하는 단점이 있었다.
### 1. 네트워크 구조
제안된 아키텍처는 크게 세 부분으로 구성된다.
1) **\(G\)-equivariant 입력 변환 \(f_{\text{in}}\)**: 각 입력 벡터 \(x_i\in\mathbb{R}^{n_{\text{in}}}\)에 동일한 신경망 \(\phi\)를 적용해 \(n_{\text{mid}}\)‑차원의 특징을 만든다. 이 과정은 모든 입력에 동일하게 적용되므로 행을 재배열하는 \(G\) 의 작용에 대해 \(G\)-equivariant 특성을 갖는다(수식 (5)–(6)).
2) **합‑곱 레이어 \(\Sigma\Pi\)**: \(f_{\text{in}}\) 의 출력을 받아 \(\Sigma\Pi(x)=\sum_{g\in G}\prod_{j=1}^{n}\phi_j\bigl(x_{\sigma_g(j)}\bigr)\) 와 같이 모든 그룹 원소에 대해 곱을 취하고 합산한다. 이는 전통적인 Reynolds 연산과 동일하게 \(G\)-불변성을 보장한다(수식 (7)–(9)).
3) **다층 퍼셉트론 \(f_{\text{out}}\)**: \(\Sigma\Pi\)의 출력 \(z\in\mathbb{R}^{n_{\text{mid}}}\)를 입력으로 받아 일반적인 완전 연결 MLP를 적용한다. 여기서 활성화 함수 \(\sigma\)는 비다항 연속 함수이면 충분하다(수식 (10)).
전체 모델은 \(\Gamma(x)=f_{\text{out}}\bigl(\Sigma\Pi\bigl(f_{\text{in}}(x)\bigr)\bigr)\) 로 정의되며, 입력 변환 \(f_{\text{in}}\) 과 합‑곱 레이어 \(\Sigma\Pi\)가 결합돼 \(G\)-불변 잠재 표현을 만든 뒤, MLP가 이를 자유롭게 매핑한다.
### 2. 계층적 부분군에 대한 확장
\(G\)보다 큰 부분군 \(H\) ( \(G
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기