연합학습을 위한 확률적 사인 SGD: 통신 효율·프라이버시·비잔틴 저항을 한 번에
본 논문은 연합학습에서 데이터 이질성, 통신 제한, 개인정보 보호, 비잔틴 공격을 동시에 만족하는 새로운 SGD 변형인 Stochastic‑Sign SGD를 제안한다. 1‑비트 확률적 부호 압축기(sto‑sign)와 차등 프라이버시를 보장하는 dp‑sign을 도입하고, 오류 피드백 메커니즘을 결합해 수렴성을 이론적으로 증명한다. MNIST와 CIFAR‑10 실험을 통해 제안 방법의 효율성과 견고함을 확인한다.
저자: Richeng Jin, Yufan Huang, Xiaofan He
연합학습(Federated Learning, FL)은 데이터가 디바이스에 분산돼 있어 중앙 서버로 직접 전송하기 어려운 상황에서 모델을 공동 학습하는 패러다임이다. 그러나 FL은 (1) 통신 비용, (2) 데이터 이질성, (3) 개인정보 보호, (4) 악의적(비잔틴) 참여자에 대한 내성을 동시에 만족해야 하는 복합적인 제약을 가진다. 기존 연구는 각각의 요구사항을 개별적으로 해결했지만, 모든 요구를 동시에 만족하는 방법은 없었다.
본 논문은 이러한 공백을 메우기 위해 SIGN‑SGD 기반의 새로운 알고리즘인 Stochastic‑Sign SGD를 제안한다. 핵심 아이디어는 1‑비트 부호 압축기를 확률적으로 변형해, 부호가 뒤바뀔 확률을 제어하고, 동시에 차등 프라이버시와 비잔틴 저항성을 확보하는 것이다. 구체적으로 두 종류의 압축기를 설계한다.
1. **sto‑sign**: 원본 그라디언트를 먼저 스케일링하고, 각 좌표에 대해 사전 정의된 확률분포(예: 라플라스, 유니폼)로 잡음을 더한 뒤 부호를 취한다. 이 과정은 부호가 원래 그라디언트와 일치할 확률 1‑p̄을 보장하며, p̄<½이면 다수결 투표에서 잘못된 집계가 발생할 확률이 정리 1에 의해 O(p̄(1‑p̄)/M²) 이하가 된다. 따라서 워커 수가 충분히 크면 거의 확실히 올바른 부호가 선택된다.
2. **dp‑sign**: sto‑sign에 차등 프라이버시를 위한 추가 잡음(스케일 bᵢ)을 삽입한다. 이때 bᵢ는 각 좌표의 최대 그라디언트 크기와 잡음 분포의 민감도에 따라 결정되며, (ε,δ)‑지역 차등 프라이버시를 만족한다. 비록 잡음이 부호 오류를 증가시킬 수 있지만, 앞서 언급한 p̄<½ 조건을 유지하도록 설계한다.
알고리즘 흐름은 다음과 같다. 각 라운드에서 워커 m은 로컬 배치를 사용해 스토캐스틱 그라디언트 gᵐ(t)를 계산하고, 선택된 압축기 q(·) (sto‑sign 또는 dp‑sign)를 적용해 1‑비트 부호 벡터를 서버에 전송한다. 서버는 모든 워커의 부호를 좌표별 다수결로 집계해 𝑔̃(t)=sign(∑ₘ q(gᵐ(t)))를 얻고, 이를 모든 워커에 브로드캐스트한다. 워커는 𝑔̃(t)를 사용해 동일한 학습률 η로 로컬 모델을 업데이트한다.
**비잔틴 저항성**은 위의 다수결 구조에서 자연스럽게 발생한다. 비잔틴 워커는 임의의 부호를 전송할 수 있지만, 정상 워커가 다수이면 전체 집계가 정상 워커의 부호에 의해 압도된다. 논문에서는 비잔틴 저항성을 정량적으로 분석해, 각 좌표 i에 대해 허용 가능한 비잔틴 워커 수가 |∑ₘ g_i^{(t)}(m)|/b_i 로 표현된다는 결과를 제시한다. 특히 모든 정상 워커가 동일한 데이터셋을 갖는 경우(b_i = maxₘ g_i^{(t)}(m)) M‑1개의 비잔틴 워커까지도 견딜 수 있음을 보인다. 가중 투표와 Top‑k 스파스화 기법을 추가해 실험적으로 저항성을 더욱 강화하였다.
**오류 피드백(Error‑Feedback)** 버전은 서버가 다수결 과정에서 발생한 부호 오류를 누적하고, 다음 라운드에 보정하도록 설계되었다. 구체적으로 서버는 오류 e(t)=∑ₘ q(gᵐ(t))−sign(∑ₘ q(gᵐ(t)))를 저장하고, 다음 라운드의 집계에 e(t)·α (α는 보정 비율) 를 더한다. 이는 편향 압축기의 누적 오차를 상쇄해 수렴 속도를 크게 개선한다. 기존 EF‑SIGN 연구와 달리, 본 방법은 다중 워커 환경에서도 압축 오차가 원벡터보다 커도 수렴을 보장한다.
**이론적 수렴**은 다음 가정 하에 증명된다. (1) 목표 함수 F(w)는 하한이 존재하고, (2) L‑스무스성, (3) 각 워커의 스토캐스틱 그라디언트가 좌표별 유한 분산 σ_i²를 갖는다, (4) 워커 수 M은 홀수(다수결을 위한 최소 조건). 이러한 가정 아래, 정리 2는 Sto‑Sign SGD가 비동질 데이터 분포에서도 기대 손실이 O(1/√T) 로 감소함을, 그리고 워커 수 M이 커질수록 최적점 근처의 오차가 O(1/M) 로 감소함을 보인다.
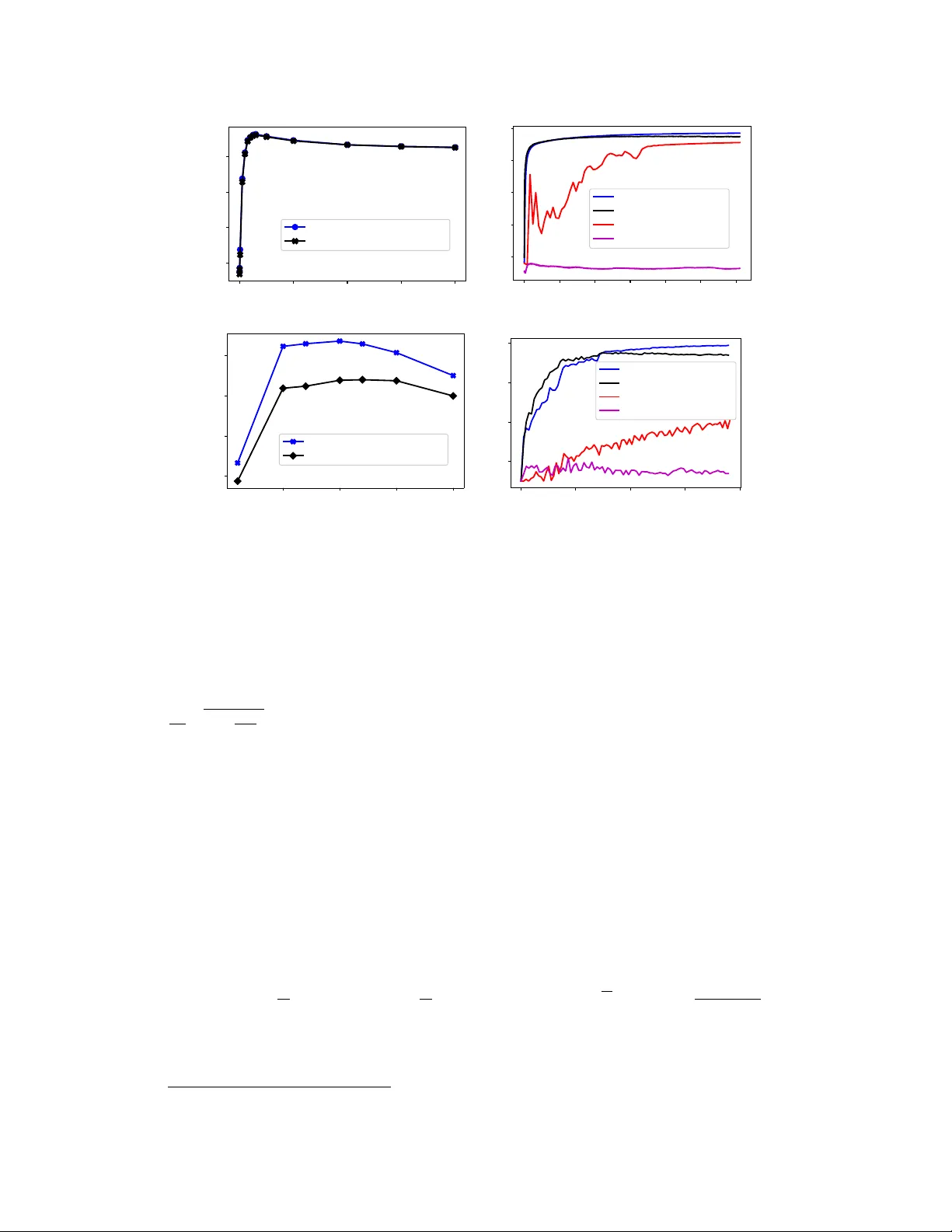
**실험**은 두 가지 벤치마크( MNIST – 2‑layer Fully Connected, CIFAR‑10 – VGG‑9)와 31개의 워커를 사용해 수행되었다. 데이터 이질성은 각 워커가 하나의 클래스만 보유하도록 설정해 극단적인 비동질성을 만든다. 실험 결과는 다음과 같다. (i) 통신량은 1‑비트 압축 덕분에 기존 전체 정밀도 SGD 대비 약 30배 감소, (ii) 정확도는 Sto‑Sign SGD가 SIGN‑SGD와 QSGD보다 동등하거나 약간 우수하며, 특히 dp‑sign을 적용했을 때 차등 프라이버시(ε≈1)와 동시에 정확도 저하가 거의 없었다, (iii) 비잔틴 워커 10개(≈1/3 전체)까지 삽입해도 가중 투표와 오류 피드백을 사용한 경우 성능 저하가 미미했다.
**결론**적으로, 본 논문은 1‑비트 부호 압축에 확률적 잡음, 차등 프라이버시, 오류 피드백을 결합해 연합학습의 핵심 요구사항을 하나의 통합 프레임워크로 제공한다. 이론적 수렴 보장, 비잔틴 저항성 한계, 프라이버시 보장 모두를 동시에 만족하면서 통신 효율성을 유지한다는 점에서 실제 FL 시스템에 적용 가능한 중요한 진전이라 할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기