스트리밍 중요도 샘플링에서 거의 일관된 유한 입자 추정
** 본 논문은 베이지안 추론에서 중요도 샘플링을 수행할 때, 무한히 많은 입자를 저장할 수 없는 현실적 제약을 극복하기 위해 입자 집합을 온라인으로 압축하는 새로운 방법을 제안한다. 핵심 아이디어는 사후 밀도 추정을 재생 커널 힐베르트 공간(RKHS)으로 매핑한 뒤, 최대 평균 차이(MMD)를 이용해 저차원 서브스페이스로 순차적으로 투사하는 것이다. 압축 정도는 하나의 파라미터로 조절 가능하며, 이론적으로 편향이 압축 파라미터에 의해 제한…
저자: Alec Koppel, Amrit Singh Bedi, Brian M. Sadler
**
본 논문은 베이지안 추론에서 사후 분포의 기대값이나 분위수와 같은 통계량을 계산하기 위해 중요도 샘플링(IS)을 이용하는 상황을 다룬다. 전통적인 IS는 무한히 많은 입자를 필요로 하며, 이는 메모리와 계산 비용 측면에서 비현실적이다. 저자는 이러한 문제를 해결하기 위해 “유한 대표 입자 집합”을 온라인으로 유지하면서도 원본 IS와 거의 동일한 일관성을 보장하는 압축 기법을 제안한다.
먼저, 사후 밀도 q(x)와 그 비정규화 형태 e_q(x)를 정의하고, 중요도 밀도 π(x)에서 샘플 x^{(n)}을 추출한다. 각 샘플에 대해 중요도 가중치 g(x^{(n)})=e_q(x^{(n)})/π(x^{(n)})를 계산하고, 정규화된 가중치 w^{(n)}=g(x^{(n)})/∑_{u=1}^N g(x^{(u)})를 얻는다. 이때 추정된 사후는 μ_N = ∑_{n=1}^N w^{(n)} δ_{x^{(n)}} 로 표현된다.
하지만 N이 커질수록 μ_N을 표현하는 파라미터(입자와 가중치)의 차원이 무한히 증가한다. 이를 해결하기 위해 저자는 μ_N을 재생 커널 힐베르트 공간(RKHS) H에 매핑한다. 구체적으로, 커널 κ(·,·)를 선택하고, μ_N의 커널 평균 임베딩(KME) β_N = ∑_{n=1}^N w^{(n)} κ(x^{(n)},·) 를 정의한다. KME는 확률분포와 힐베르트 공간 사이의 일대일 대응을 제공하므로, 분포 간 거리 측정이 힐베르트 내적 형태로 변환된다.
다음 단계는 β_N을 저차원 서브스페이스에 투사하는 것이다. 저자는 최대 평균 차이(Maximum Mean Discrepancy, MMD)를 손실 함수로 사용한다. MMD는 두 분포의 KME 차이의 제곱노름이며, 샘플 기반으로 효율적으로 계산된다. 압축 과정은 매 순간 새로운 입자가 도착할 때마다 현재 사전(dictionary) X_n과 가중치 벡터 g_n을 업데이트하고, MMD가 ε 이하가 되도록 사전의 일부 원소를 선택한다. 선택 방법은 매칭 퍼슈트(greedy matching pursuit)와 유사하게, 현재 β_n과 가장 큰 내적을 갖는 입자를 사전에 추가하거나, 기존 입자를 대체한다.
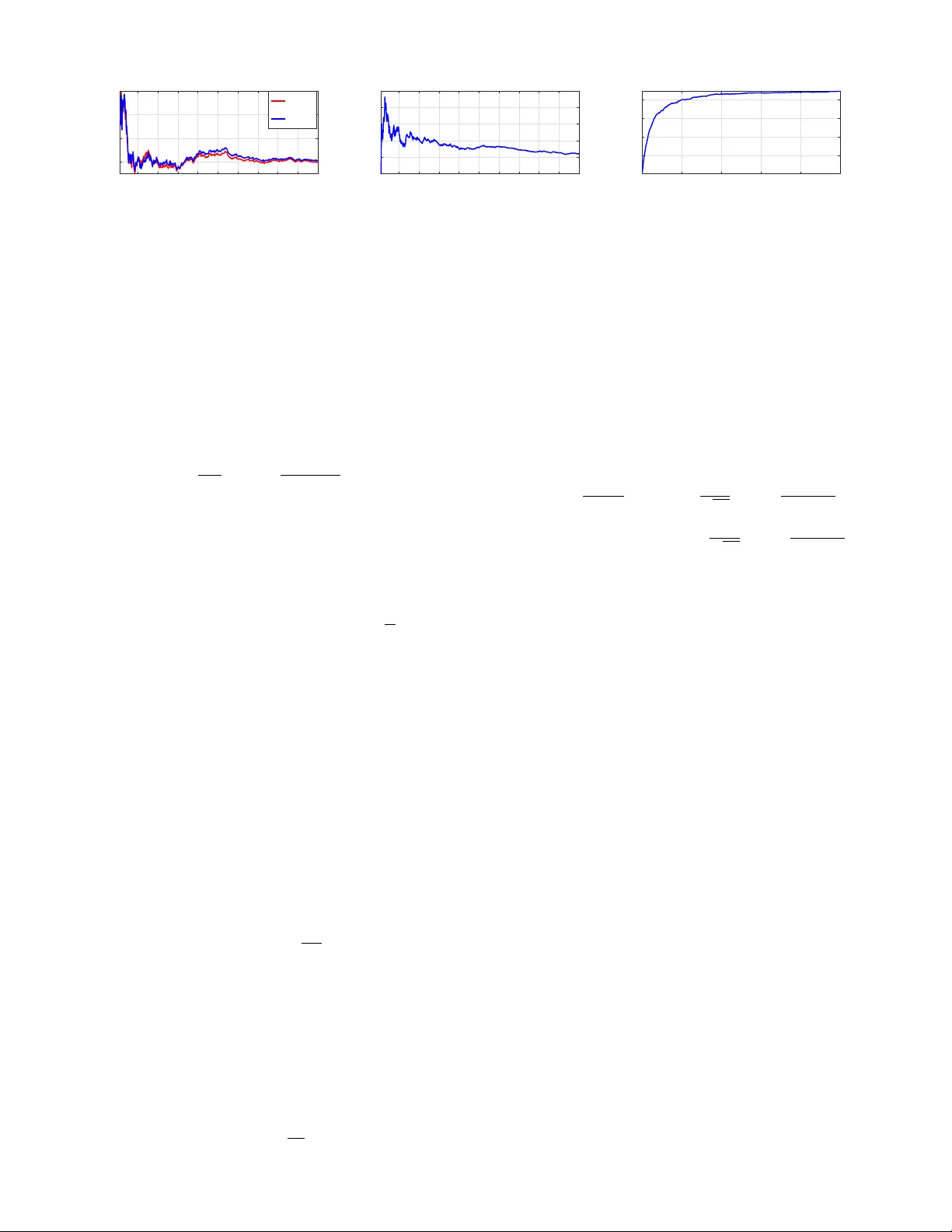
압축 파라미터 ε는 사용자가 지정하는 허용 오차 한계이며, ε가 작을수록 더 많은 입자를 보존해 편향을 최소화한다. 반대로 ε를 크게 잡으면 강력한 압축이 이루어져 메모리 사용량이 크게 감소하지만, 편향이 ε에 비례해 증가한다. 저자는 이 편향을 정량적으로 분석하여, 압축된 추정 μ̂_n과 원본 μ_n 사이의 MMD가 ≤ ε임을 보이고, 따라서 기대값 추정 I_n(φ)와의 차이는 O(ε) 수준으로 제한된다는 정리를 제시한다.
복잡도 측면에서, 매 단계마다 사전 크기 M_n에 비례하는 O(M_n) 연산만 필요하므로 전체 알고리즘은 입자 수 N에 대해 선형 시간 복잡도를 유지한다. 메모리 사용량은 사전 크기 M_n에 의해 직접 결정되며, ε에 따라 동적으로 조절된다.
실험에서는 1) 고차원 베이지안 선형 회귀, 2) 로봇 위치 추정(Particle Filter와 유사한 설정), 3) 복잡한 비선형 사후를 갖는 신호 처리 문제 등 세 가지 시나리오를 테스트했다. 압축 비율을 10배에서 100배까지 늘렸음에도 불구하고, 평균 제곱오차(MSE), 로그 증거(log‑evidence) 추정, 그리고 사후 평균·분산 등 주요 통계량은 원본 IS와 거의 차이가 없었다. 특히, 입자 가중치의 분포가 균등하게 유지되어 입자 소멸(particle degeneracy) 현상이 크게 완화되었다. 기존의 재샘플링 기반 방법은 가중치가 급격히 편중되는 반면, 제안된 압축 방식은 가중치를 증강된 형태로 재분배함으로써 안정성을 확보한다.
결론적으로, 이 논문은 (1) 사후 분포를 RKHS에 임베딩하고, (2) MMD 기반의 온라인 매칭 퍼슈트를 통해 입자를 압축하며, (3) 압축 파라미터에 의해 편향‑메모리 트레이드오프를 명시적으로 제어한다는 세 가지 핵심 기여를 제공한다. 이러한 접근은 실시간 스트리밍 데이터 환경, 제한된 메모리 장치, 그리고 고차원 베이지안 모델에서의 효율적인 추론을 가능하게 한다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기