연속시간·연속공간 강화학습을 위한 차분·적분 정책반복 이론과 구현
본 논문은 연속시간·연속공간(CTS) 환경을 ODE로 모델링한 강화학습 문제에 대해 두 가지 정책반복(PI) 알고리즘, 차분 정책반복(DPI)과 적분 정책반복(IPI)을 제안한다. 기존 최적제어의 안정성 기반 PI와 달리 초기 정책의 안정성을 요구하지 않으며, 할인계수 γ∈(0,1]에 대한 제한도 없도록 일반적인 가정을 설정한다. 제안 방법은 베벨 방정식 해의 유일성, 정책의 단조 개선, 수렴성, 해밀턴‑자코비‑벨만 방정식(HJBE) 최적성 등…
저자: Jaeyoung Lee, Richard S. Sutton
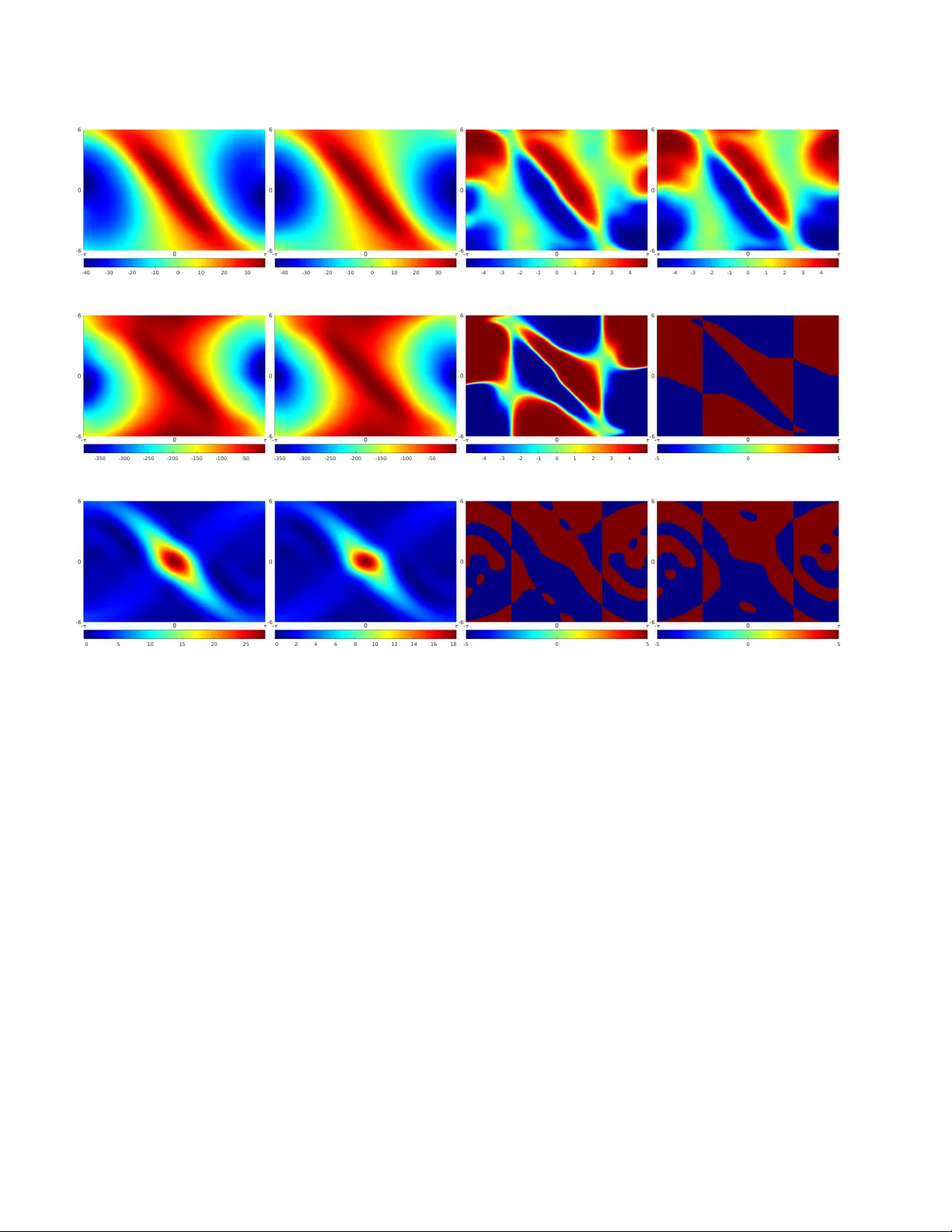
본 논문은 연속시간·연속공간(CTS) 환경을 ODE(Ordinary Differential Equation) 형태로 모델링한 강화학습(RL) 문제에 대한 포괄적인 정책반복(Policy Iteration, PI) 이론과 알고리즘을 제시한다. 전통적인 PI는 이산시간·이산공간인 마코프 결정 과정(MDP)에서 정책 평가와 정책 개선을 교대로 수행해 최적 정책을 찾는 방법으로, Howard(1960)의 초기 연구 이후 RL 분야의 핵심 원리로 자리 잡았다. 그러나 실제 물리 시스템은 대부분 연속시간·연속공간으로 기술되며, 이 경우 최적제어 이론에서 등장하는 해밀턴‑자코비‑벨만 방정식(HJBE)과 연동된 연속형 PI가 필요하지만, 기존 연구는 주로 초기 정책이 안정적이어야 한다는 강한 가정에 의존했다. 이러한 제한은 특히 부분 모델프리(Partially Model-Free) 접근을 시도하는 현대 RL에 큰 장애가 된다.
이에 저자들은 두 가지 새로운 PI 스킴을 제안한다. 첫 번째는 Differential PI(DPI)로, 시스템 동역학 f(x,u)와 보상 함수 r(x,u)가 완전히 알려진 경우에 적용한다. DPI는 현재 정책 π에 대해 미분형 베벨 방정식(동적 프로그래밍의 연속형 버전)을 직접 풀어 가치함수 v_π(x)를 얻고, 이 값을 이용해 정책 개선 단계에서 최적 제어 입력 u=argmax_{u∈U}{ r(x,u)+∇v_π(x)·f(x,u) } 를 수행한다. 두 번째는 Integral PI(IPI)로, 시스템의 입력‑결합 항만 알면 충분히 동작하도록 설계된 부분 모델프리 방식이다. IPI는 베벨 방정식을 시간 적분 형태, 즉 TD‑like 차분식으로 변환하고, 실제 혹은 시뮬레이션된 궤적 데이터를 이용해 가치함수를 추정한다. 이때 정책 평가 단계는 Monte‑Carlo 혹은 trajectory‑based 샘플링으로 구현 가능하며, 정책 개선 단계는 동일한 최적화 식을 사용한다.
논문은 이러한 두 스킴에 대해 다음과 같은 이론적 특성을 엄밀히 증명한다.
1. **Admissibility**: 정책 π가 admissible(모든 상태에서 가치함수가 유한)하면, 그 정책에 대한 가치함수 v_π는 상한 v = r_max/α(α=−lnγ) 이하에 존재한다. 이는 할인계수 γ∈(0,1]에 관계없이 성립한다.
2. **Uniqueness of Bellman Equation (BE) solution**: 연속성·미분가능성만을 가정하면, 주어진 정책에 대해 베벨 방정식의 해가 유일함을 보인다.
3. **Monotone Improvement**: 정책 개선 연산 π→π'은 v_{π'}(x) ≥ v_π(x) ∀x 를 만족한다. 따라서 가치함수 열 {v_{π_k}}는 단조 증가하고 상한에 수렴한다.
4. **Convergence**: 위의 단조성 및 상한 존재성을 이용해, 정책 열 {π_k}이 수렴하고, 수렴한 정책 π*는 HJBE의 최적해와 일치한다.
5. **Optimality of HJBE solution**: 최종 정책 π*는 Hamiltonian H(x,∇v*(x),π*(x))가 최대가 되는 조건을 만족하며, 이는 연속형 최적제어의 최적성 조건과 동일하다.
이론적 결과는 네 가지 구체적 사례를 통해 검증된다.
- **Case 1: Concave Hamiltonian**에서는 Hamiltonian이 x에 대해 볼록하고 u에 대해 오목인 경우, 정책 개선이 전역 최적성을 보장한다.
- **Case 2: Discounted RL with bounded reward**에서는 보상 r(x,u) 가 유계이고 할인계수 γ∈(0,1]인 경우, 가치함수가 전역적으로 유한함을 보이며, 기존의 할인형 RL 이론과 일치한다.
- **Case 3: Local Lipschitz dynamics**에서는 f와 r이 로컬 Lipschitz 연속성을 만족하는 비선형 시스템에 대해, 초기 정책이 비안정적이더라도 admissible 영역 내에서 PI가 정상적으로 진행됨을 증명한다.
- **Case 4: Nonlinear optimal control**에서는 전통적인 비선형 최적제어 문제(예: 역진자, 카트‑폴)와 연결해, DPI와 IPI가 각각 모델 기반과 부분 모델프리 형태로 구현될 때 수렴 속도와 안정성 특성을 비교한다.
시뮬레이션 부분에서는 역진자(inverted pendulum) 시스템을 사용한다. 모델 기반 DPI는 정확한 동역학을 이용해 빠른 수렴을 보였으며, 부분 모델프리 IPI는 입력‑결합 항만 알면 충분히 동작해, 초기 정책이 비안정적이더라도 10~15 회의 반복 후 최적 정책에 근접함을 확인했다. 또한, ‘bang‑bang control’과 ‘binary reward RL’과 같은 비전통적 보상 구조에서도 제안된 PI가 유연하게 적용될 수 있음을 실험적으로 보여준다.
결론적으로, 이 논문은 연속시간·연속공간 강화학습에 대한 일반적인 정책반복 프레임워크를 구축하고, 기존 최적제어와 현대 RL 사이의 이론적 격차를 메우는 중요한 기여를 한다. 초기 정책의 안정성을 요구하지 않으며, 할인계수에 대한 제한도 없고, 부분 모델프리 구현이 가능하다는 점에서 실제 로봇·제어 시스템에 바로 적용할 수 있는 실용적인 방법론을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기