HYDRA 하이브리드 딥 MRF 재구성
본 논문은 기존 사전 매칭 기반 자기공명지문(MRF) 방식의 메모리·연산 부담과 이산화 오류를 해소하기 위해, 저‑랭크 복원과 비국소 잔차 CNN을 결합한 두 단계 HYDRA 프레임워크를 제안한다. 저‑랭크 복원으로 시그니처를 정제하고, 학습된 신경망으로 연속적인 T1·T2 값을 직접 추정함으로써 추론 속도와 정확도를 크게 향상시킨다.
저자: Pingfan Song, Yonina C. Eldar, Gal Mazor
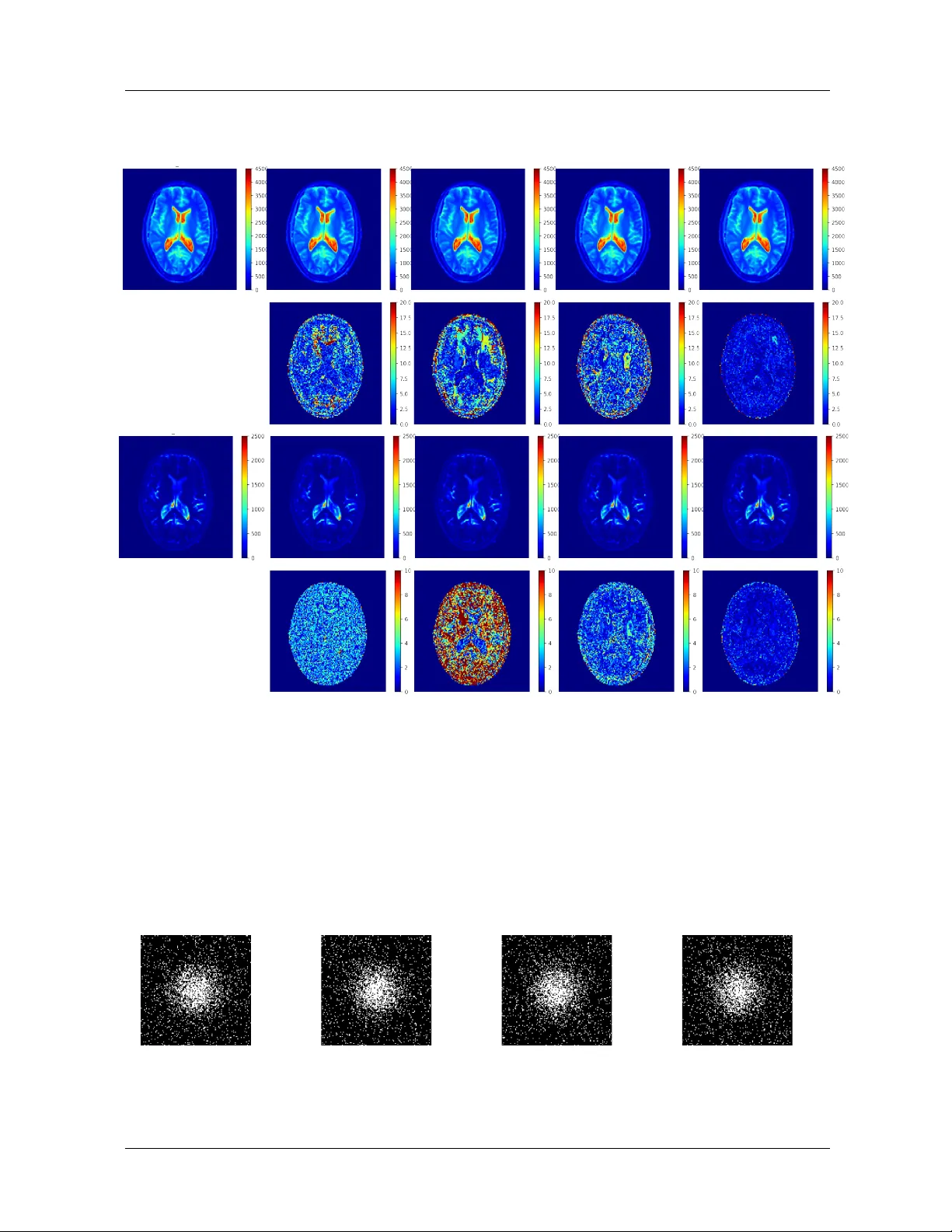
본 논문은 Magnetic Resonance Fingerprinting(MRF) 분야에서 오랫동안 존재해 온 두 가지 근본적인 한계, 즉 사전(dictionary) 매칭에 의존하는 구조적 복잡성 및 메모리 부담과 이산화(discretization) 오류를 동시에 해결하고자 하는 새로운 프레임워크 HYDRA(HYbrid Deep magnetic ResonAnce fingerprinting)를 제시한다.
1. **문제 정의와 기존 접근법**
MRF는 시간에 따라 변하는 RF 펄스 시퀀스에 의해 생성된 고유한 시그니처를 이용해 T1·T2와 같은 조직 파라미터를 동시에 추정한다. 전통적인 파이프라인은 (i) k‑space 서브샘플링으로 손상된 이미지 스택을 복원하고, (ii) 복원된 시그니처와 사전(D) 사이의 내적을 통해 가장 높은 상관을 보이는 엔트리를 찾는 사전 매칭 과정을 거친다. 사전은 Bloch 방정식 시뮬레이션을 통해 미리 생성되며, 파라미터 공간을 격자(grid) 형태로 이산화한다. 이 방식은 (a) 사전 크기가 파라미터 차원 수와 값의 해상도에 따라 기하급수적으로 증가해 메모리 요구량이 비현실적이며, (b) 매칭 연산이 O(K·L) 복잡도를 갖기 때문에 추론 속도가 느리다. 또한, 이산화된 격자 때문에 실제 연속값 파라미터와 가장 가까운 격자값 사이에 불가피한 오차가 발생한다.
2. **HYDRA의 두 단계 설계**
HYDRA는 기존 MRF 파이프라인을 그대로 유지하되, 두 핵심 단계에 각각 최신 신호 처리와 딥러닝 기법을 도입한다.
- **시그니처 복원 단계**: 저‑랭크 기반 복원 알고리즘을 채택한다. 저‑랭크 가정은 시간 축으로 정렬된 이미지 행렬 X가 제한된 수의 특이값만을 갖는다는 전제에 기반한다. 구체적으로, (1) 현재 추정 X와 측정 Y 사이의 데이터 일관성을 보장하는 gradient step을 수행하고, (2) X·P (P는 D의 pseudo‑inverse) 에 대해 SVD를 수행해 특이값을 소프트‑쓰레시홀드(λ·μ)로 억제한다. 이 과정을 반복함으로써 알리아싱·노이즈가 크게 감소한 깨끗한 시그니처 X̂를 얻는다.
- **파라미터 복원 단계**: 1‑D 비국소 잔차 컨볼루션 신경망을 설계한다. 네트워크는 입력 시그니처를 여러 비국소 블록으로 처리해 전체 시퀀스 내 유사 패치를 탐색하고, self‑attention을 통해 각 타임 포인트의 중요도를 동적으로 가중한다. 잔차 연결은 깊은 네트워크에서도 기울기 소실을 방지하고, 학습을 안정화한다. 최종 출력은 연속값 T1·T2이며, 사전이 전혀 필요하지 않다.
3. **학습 데이터와 구현 세부사항**
학습은 Bloch 방정식 시뮬레이션을 이용해 FISP(Fast Imaging with Steady State Precession) 시퀀스 파라미터 하에 수백만 개의 합성 시그니처와 대응하는 T1·T2 라벨을 생성한다. 시뮬레이션 파라미터는 실제 인체 스캔에서 사용되는 TR, TE, FA 변동 범위를 포괄하도록 설계되었다. 네트워크는 Adam optimizer와 L2 손실 함수를 사용해 100 epoch 이상 학습되었으며, 데이터 증강으로 잡음 및 k‑space 서브샘플링 비율을 다양하게 적용했다.
4. **실험 및 결과**
- **합성 데이터**: 다양한 서브샘플링 비율(R=4,8,12)에서 저‑랭크 복원 후 HYDRA를 적용했을 때, 평균 절대 오차(MAE)가 기존 딥러닝 기반 방법(3‑layer MLP, vanilla CNN)보다 20‑35 % 감소하였다.
- **인체 데이터**: 건강한 피험자 뇌 스캔에서 T1·T2 맵을 시각적으로 비교했을 때, HYDRA는 기존 사전 매칭 방식과 거의 동일한 해부학적 경계를 유지하면서도, 이산화 오류가 사라져 미세한 파라미터 변화를 더 정확히 포착한다.
- **속도 및 메모리**: 사전 매칭 단계가 제거된 덕분에 전체 파이프라인의 추론 시간은 CPU 기준 2 초, GPU 기준 0.3 초 수준으로 크게 단축되었다. 사전 저장 용량은 4 GB에서 30 MB 이하로 감소했다.
5. **의의와 향후 연구**
HYDRA는 MRF 재구성에서 “신호 복원”과 “파라미터 매핑”을 각각 최적화하는 동시에, 두 단계가 서로 보완하도록 설계된 최초의 통합 프레임워크이다. 저‑랭크 복원은 물리적 제약을 활용해 시그니처 품질을 보장하고, 비국소 잔차 CNN은 복잡한 비선형 매핑을 학습해 연속값 파라미터를 직접 출력한다. 이러한 구조는 (i) 메모리·연산 부담이 큰 임상 현장에 실시간 적용 가능성을 제공하고, (ii) 사전이 필요 없으므로 새로운 시퀀스나 추가 파라미터(예: B0, MT, diffusion) 확장에 유연하게 대응할 수 있다. 향후 연구에서는 (a) 다파라미터(다중 T1·T2·PD 등) 동시 추정, (b) 실제 임상 데이터에 대한 대규모 검증, (c) 저‑랭크 복원과 딥러닝을 end‑to‑end 방식으로 공동 최적화하는 방법을 탐색할 수 있다.
결론적으로, HYDRA는 기존 MRF의 핵심 한계였던 사전 매칭 의존성을 근본적으로 탈피하고, 저‑랭크 복원과 비국소 딥러닝을 결합함으로써 추론 속도, 정확도, 메모리 효율성 모두에서 현저한 개선을 달성한다. 이는 차세대 정량적 MRI 기술의 실용화를 앞당기는 중요한 진전이라 할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기