동적 요금제 최적화를 위한 딥 강화학습: 다중 진입·출구 관리 차선의 실시간 가격 결정
본 논문은 다중 진입·출구를 갖는 관리 차선(Express Lane)에서 여행자들의 가치·출발·목적지 이질성을 고려한 동적 요금제 문제를 부분관측 마코프 의사결정 과정(POMDP)으로 모델링하고, 정책경사 기반 딥 강화학습(Deep‑RL)으로 연속·확률적 톨을 실시간 관측에 따라 결정한다. 제안 알고리즘은 기존 피드백 제어 휴리스틱보다 수익을 최대 9.5%, 전체 시스템 여행시간(TSTT)을 최소 10.4% 개선했으며, 보상 설계와 전이 학습을…
저자: Venktesh P, ey, Evana Wang
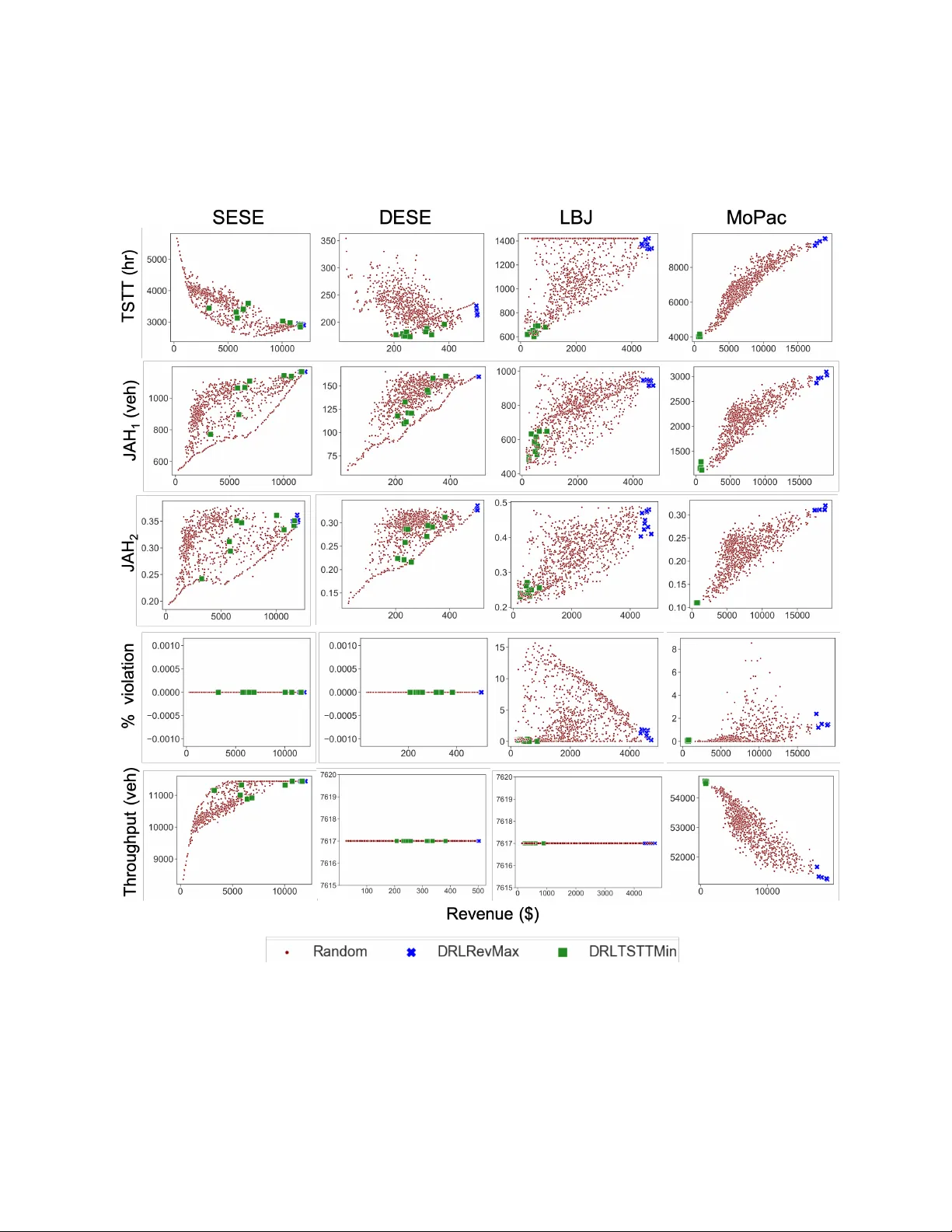
본 논문은 관리 차선(Express Lane, HOT lane)의 동적 요금제 문제를 현대 교통 시스템이 직면한 복합적인 불확실성과 이질성을 반영해 새롭게 모델링하고, 딥 강화학습(Deep‑RL) 기반의 최적 제어 방안을 제시한다. 연구 배경으로는 기존 동적 요금제 연구가 단일 출발·목적지, 완전 관측, 단일 차량 클래스, 그리고 교통 흐름의 단순 가정을 전제로 했으며, 이러한 가정이 실제 다중 진입·출구를 갖는 대규모 관리 차선 네트워크에 적용하기엔 한계가 있다는 점을 지적한다. 특히, 수익을 극대화하려는 정책이 일반 차선을 인위적으로 혼잡시켜 수익을 ‘수확’하는 ‘jam‑and‑harvest’ 현상이 비현실적이며 사회적으로 바람직하지 않다는 문제를 제기한다.
모델링 단계에서 저자들은 관리 차선과 일반 차선을 각각 상향·하향 링크로 구분하고, 램프를 통해 진입·출구가 이루어지는 그래프 구조를 정의한다. 시간은 Δt 간격으로 이산화하고, 톨은 매 Δτ=m·Δt마다 업데이트된다. 수요는 OD 쌍별로 평균 d_rs(t)와 표준편차 σ_d를 갖는 정규분포로 가정하지만, 운영자는 이를 알지 못한다. VOT는 이산형 집합 V에 할당되고, 각 VOT 비율 p_v 역시 관측되지 않는다. 이러한 부분관측 상황을 POMDP로 공식화한다. 관측은 제한된 센서(루프 디텍터 등)에서 얻는 밀도 데이터만을 사용한다.
정책은 연속적인 톨 값을 출력하는 피드포워드 신경망으로 구현되며, 정책경사 기반 알고리즘(주로 PPO)을 적용한다. 보상 함수는 단일 목표(수익, TSTT)뿐 아니라 다목적 가중합 형태로 설계된다. 수익 중심 보상에 교통 혼잡 페널티를 추가해 ‘jam‑and‑harvest’ 행동을 억제하는 보상 shaping 기법을 도입한다. 또한, 정책 학습 과정에서 탐험‑활용 균형을 맞추기 위해 가우시안 노이즈를 톨에 직접 적용한다.
실험은 네 개의 실제 교통 네트워크(텍사스 LBJ TEXpress, 캘리포니아 I‑80, 뉴욕 I‑495 등)를 대상으로 수행된다. 각 네트워크는 다중 진입·출구와 다양한 OD 페어를 포함하며, 셀 전송 모델 기반의 미시·중간 규모 시뮬레이션으로 교통 흐름을 재현한다. 비교 대상은 기존 피드백 제어 휴리스틱으로, 실시간 밀도에 비례해 톨을 조정한다. 실험 결과는 다음과 같다. (1) 수익 최대화 목표에서 딥‑RL 정책이 평균 9.5% 높은 수익을 달성한다. (2) 전체 시스템 여행시간 최소화 목표에서는 평균 10.4% 낮은 TSTT를 기록한다. (3) 보상 shaping을 적용하지 않은 경우 ‘jam‑and‑harvest’ 현상이 관찰되었으나, shaping 후에는 이러한 비현실적 행동이 사라진다. (4) 학습된 정책을 새로운 수요 분포에 적용했을 때 성능 저하가 미미해 전이 학습 가능성을 확인한다. (5) 정책 네트워크를 경량화하고 GPU 가속 추론을 활용하면 실시간 적용(≤100 ms)도 가능하다.
코드와 시뮬레이션 환경은 GitHub(https://github.com/venktesh22/ExpressLanes_Deep‑RL)에서 오픈소스로 제공되어 재현성을 보장한다. 실시간 구현을 위한 권고사항으로는 (a) 정책 재학습 주기 설정(예: 30분~1시간), (b) 센서 노이즈와 결함을 고려한 robust learning, (c) 다중 구역 간 협조를 위한 멀티‑에이전트 확장, (d) 정책 검증을 위한 오프라인 시뮬레이션 배틀 테스트 등이 제시된다. 논문의 한계로는 (i) 실제 사고·날씨 등 비정상 상황에 대한 견고성 검증 부족, (ii) 다중 에이전트 간 협조 전략 미탐색, (iii) 정책 해석 가능성(black‑box) 문제 등이 있다. 향후 연구는 이러한 제한을 보완하고, 실제 톨링 운영기관과의 파일럿 테스트를 통해 현장 적용성을 검증하는 방향을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기