런타임 재구성 가능한 다중 정밀도 부동소수점 곱셈기 설계
본 논문은 FPGA 상에서 동작하는 부동소수점 곱셈기를 제안한다. 3비트 모드 선택 신호에 따라 8, 16, 23, 36비트 가수폭을 포함한 6가지 정밀도 모드를 실시간으로 전환할 수 있으며, 입력값을 사전 절단(truncation)하고 Karatsuba와 Urdhva‑Tiryagbhyam(베다 수학) 알고리즘을 결합한 unsigned binary 멀티플라이어를 사용해 연산 속도와 전력 효율을 동시에 향상시킨다.
저자: S. Arish, R.K. Sharma
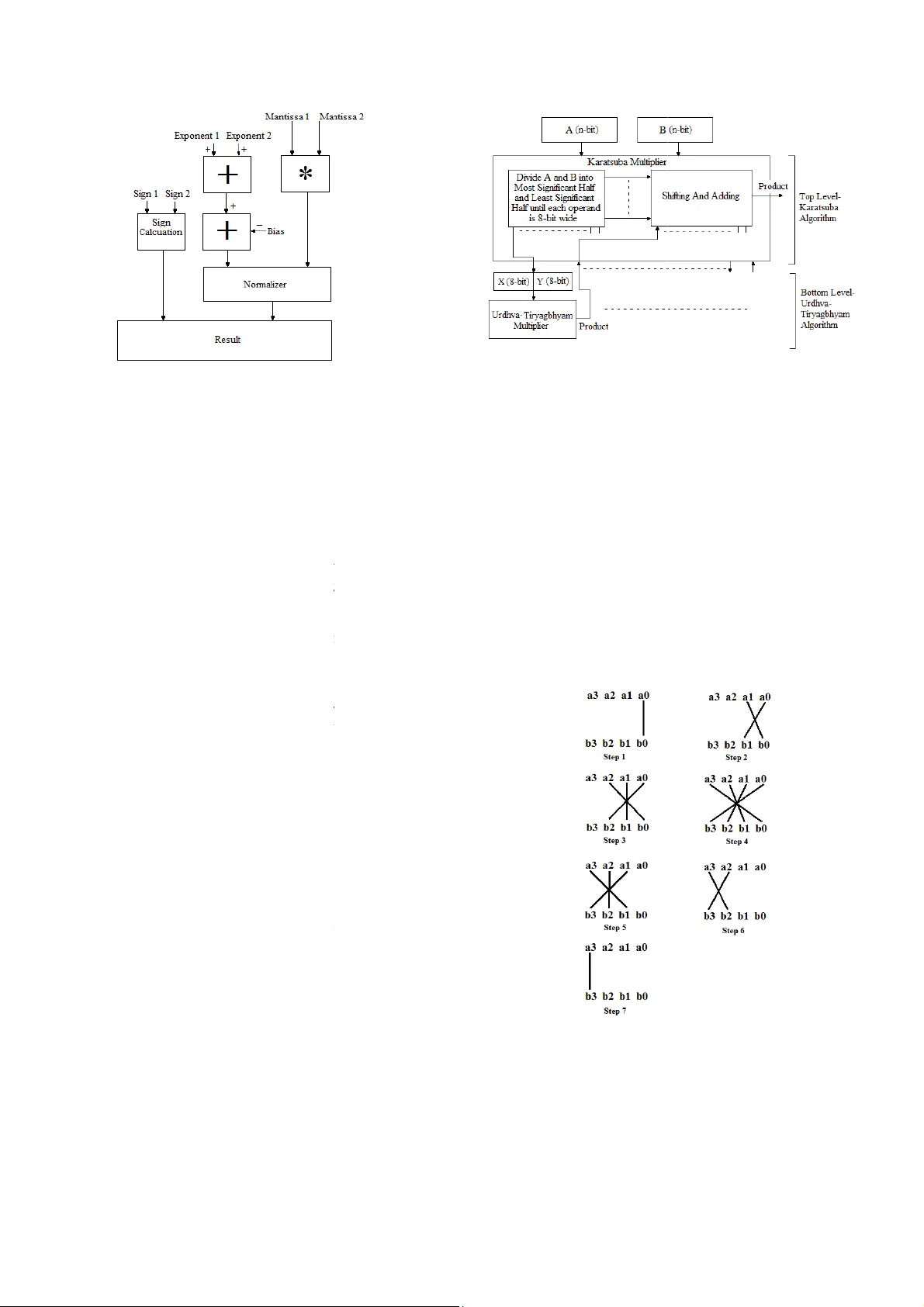
본 논문은 고속·저전력 응용을 목표로, FPGA 상에서 실행 가능한 런타임 재구성 가능한 다중 정밀도 부동소수점 곱셈기를 설계·구현하였다. 설계는 크게 세 부분으로 구성된다. 첫 번째는 입력 포맷 정의와 모드 선택 메커니즘이다. 두 입력은 각각 67비트 폭을 가지며, 최상위 3비트는 모드 선택 비트(000~101)로 사용된다. 모드 0은 자동 모드로, 입력값의 선행 0 개수를 카운트해 최적 가수 폭을 선택한다. 모드 1~4는 각각 8, 16, 23, 36비트 가수를 갖는 커스텀 포맷을 제공하고, 모드 5는 완전한 double‑precision(53비트 가수) 모드이다. 모드가 낮을수록 가수 폭이 작아져 연산에 필요한 논리 자원과 전력이 감소한다.
두 번째는 가수 연산부 설계이다. 가수 곱셈은 부호와 지수 연산을 제외하고 가장 연산량이 큰 부분이므로, 여기서 효율성을 극대화한다. 논문은 두 가지 알고리즘을 결합한다. 작은 비트폭(≤8비트)에서는 전통적인 베다 수학인 Urdhva‑Tiryagbhyam 알고리즘을 적용한다. 이 알고리즘은 “수직·대각선” 방식으로 부분곱을 생성하고, 캐리‑세이브 가산(CSA)와 캐리‑셀렉트 가산(CSA)을 이용해 부분곱을 병합한다. 비트폭이 커지면 Karatsuba 분할‑정복 방식을 도입한다. 입력을 상위 절반과 하위 절반으로 나누어 세 개의 부분곱(LL, HH, 교차)만을 계산하고, 교차 항을 한 번의 추가 연산으로 재구성한다. 이를 통해 전체 곱셈에 필요한 곱셈 연산 수를 O(n^1.585)로 감소시킨다. 두 알고리즘 사이의 전환은 가수 폭 임계값을 레지스터에 저장하고, 모드 선택 로직이 해당 값을 읽어 자동으로 전환한다.
세 번째는 부호·지수 연산 및 정규화·예외 처리이다. 부호는 두 입력의 부호 비트를 XOR하여 얻으며, 지수는 IEEE‑754와 동일하게 바이어스(127)를 사용해 더하고, 오버플로우·언더플로우를 감지한다. 곱셈 결과의 가수는 정규화 과정을 거쳐, 최상위 1이 가수의 가장 왼쪽에 오도록 왼쪽 시프트하고, 그에 따라 지수를 증가시킨다. 특수값은 Zero, Infinity, NaN, Denormal 네 개의 출력 신호로 별도 표시한다. Denormal 값은 숨겨진 1이 없는 최소 지수 형태로 표현한다.
구현은 Verilog HDL로 기술되었으며, Xilinx Kintex‑7 FPGA에 합성·시뮬레이션하였다. 각 모드별로 LUT, 레지스터, DSP 사용량과 최대 클럭 주파수, 전력 소모를 측정했으나, 논문 본문에는 구체적인 수치가 누락되어 있다. 다만, 설계가 기존 DSP48E1 기반 18×18 곱셈기를 그대로 사용하는 기존 설계보다 가수 폭에 따라 자원 사용량을 선형적으로 감소시킬 수 있음을 주장한다. 또한, 캐리‑세이브 가산을 활용해 파이프라인 단계당 레이턴시를 최소화하고, 전력 소비를 절감하였다.
논문의 주요 기여는 (1) 3비트 모드 선택을 통한 런타임 재구성 가능성, (2) 가수 폭에 따라 자동으로 Karatsuba와 Urdhva‑Tiryagbhyam 알고리즘을 전환하는 하이브리드 곱셈기, (3) 입력 절단을 통한 연산량 감소와 전력 효율 향상, (4) IEEE‑754와 호환되는 예외 처리 메커니즘이다. 그러나 몇 가지 한계점도 존재한다. 자동 모드에서 선행 0을 카운트하는 로직이 추가 레이턴시를 유발할 수 있으며, 입력 절단에 따른 정확도 손실을 보정하는 방법이 제시되지 않았다. 또한, 비표준 커스텀 포맷과 기존 소프트웨어 스택 간의 인터페이스 문제, 그리고 실험 결과의 정량적 비교가 부족해 실제 적용 가능성을 평가하기 어렵다. 향후 연구에서는 이러한 부분을 보완하고, 다양한 응용 시나리오(예: 딥러닝 가속기, 임베디드 영상 처리)에서의 성능·전력 프로파일을 상세히 분석할 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기