트리 스택 메모리 유닛으로 구성 일반화 달성
본 논문은 수학적 추론 벤치마크에서 기존 트리‑LSTM·Transformer보다 뛰어난 구성 일반화를 보이는 새로운 재귀 신경망 구조인 트리 스택 메모리 유닛(Tree‑SMU)을 제안한다. 각 노드는 미분 가능한 스택을 메모리로 갖고, 자식 노드의 상태와 스택을 게이팅하여 읽고 쓰는 연산을 수행한다. 스택은 장거리 의존성을 보존하고 자식들의 순서를 유지함으로써 깊고 복잡한 식에서도 정확한 계산이 가능하도록 한다. 네 가지 구성 일반화 테스트(로…
저자: Forough Arabshahi, Zhichu Lu, Pranay Mundra
본 논문은 “구성 일반화”(compositional generalization)라는 문제에 초점을 맞추어, 기존 신경망이 새로운 개념 조합을 제로샷으로 처리하는 데 한계를 보이는 현상을 해결하고자 한다. 이를 위해 저자들은 “Tree Stack Memory Unit”(Tree‑SMU)이라는 새로운 재귀 신경망 구조를 제안한다. Tree‑SMU는 기존 Tree‑LSTM·Tree‑RNN과 달리 각 노드에 미분 가능한 스택 메모리를 부착한다. 스택은 LIFO 구조를 유지하면서도 연산은 연속적인 soft push·pop 게이트를 통해 미분 가능하게 구현된다.
구조적 세부 사항은 다음과 같다. 각 노드 j는 은닉 차원 n과 스택 깊이 p를 갖는 스택 S_j∈ℝ^{p×n}을 보유한다. 입력 i_j는 두 자식 노드의 상태 h_{c_j1}, h_{c_j2}를 연결한 벡터이며, 이를 기반으로 (1)‑(2)식에서 자식 스택을 가중합하는 forget‑like 게이트 f_{j1}, f_{j2}를 계산한다. 이어서 (3)‑(4)식에서 push·pop 게이트 a_{push}, a_{pop}를 구하고, (5)‑(6)식에 따라 스택을 업데이트한다. 필요에 따라 no‑op 게이트 a_{no‑op}를 추가해 스택을 그대로 유지할 수도 있다. 최종 출력 h_j는 top‑k(또는 top‑1) 스택 원소를 선택해 o_j·tanh 연산을 적용해 얻는다. 이러한 설계는 (1) 장거리 의존성 보존, (2) 자식 순서 유지, (3) 파라미터 수는 기존 Tree‑LSTM과 비슷하면서도 메모리 용량을 크게 확장한다는 장점을 제공한다.
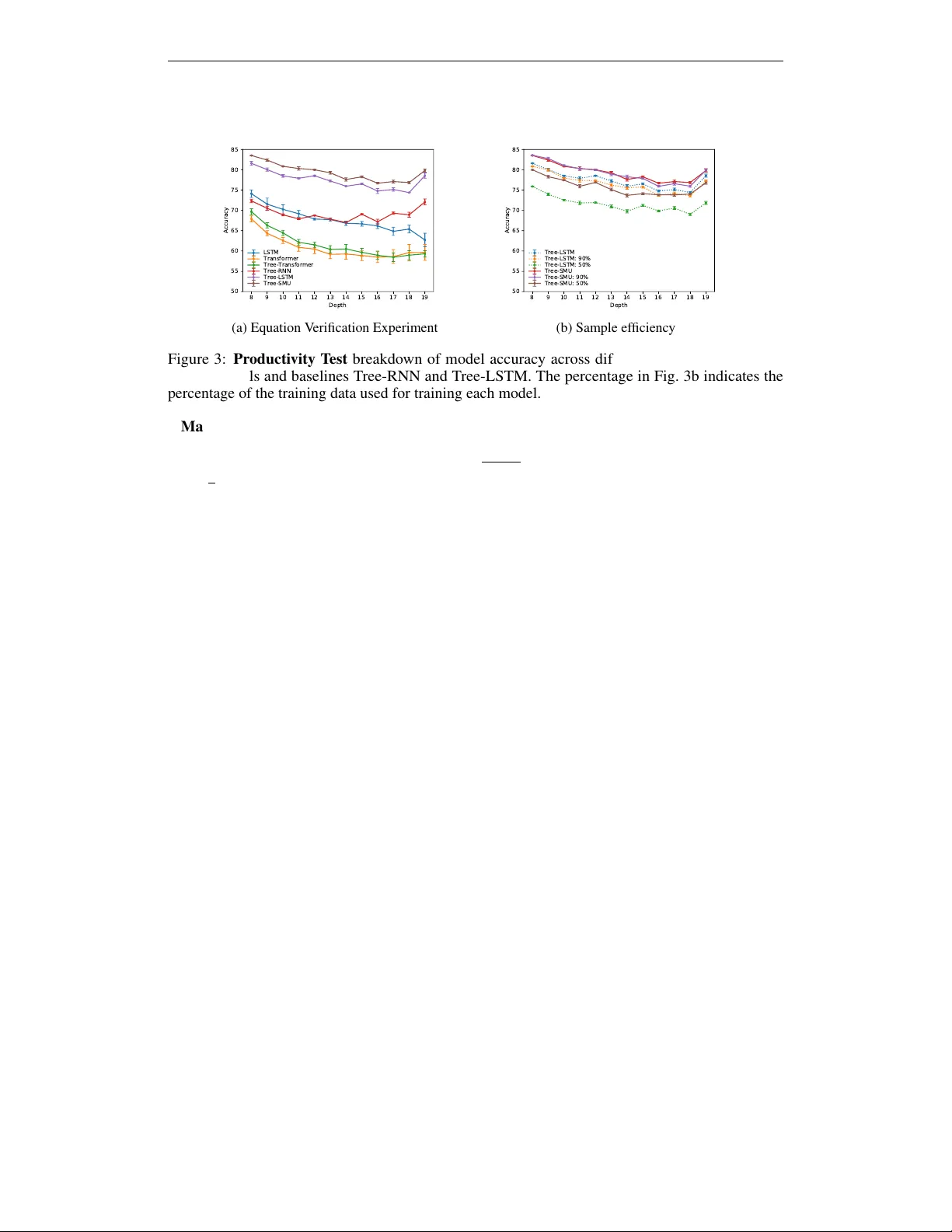
논문은 두 가지 수학적 추론 벤치마크를 실험에 사용한다. 첫 번째는 방정식 검증(Equation Verification)으로, 기호·수치 방정식이 올바른지 판단한다. 두 번째는 방정식 완성(Equation Completion)으로, 빈칸에 들어갈 올바른 수식을 찾는다. 데이터는 Arabshahi et al. (2018)의 코드 기반으로 깊이 1‑19까지 균등하게 생성했으며, 훈련·검증은 40k 샘플, 테스트는 약 200k 샘플을 사용했다.
구성 일반화 평가는 Hupkes et al. (2020)의 5가지 테스트 중 4가지를 채택했다. (1) 로컬리즘: 깊은 식(5‑13)으로 학습하고 얕은 식(1‑4)에서 테스트한다. (2) 생산성: 깊이 1‑7로 학습 후 깊이 >7에서 테스트한다. (3) 대체성: 의미적으로 동등한 서브식이 임베딩 공간에서 가깝게 매핑되는지를 t‑SNE 시각화로 확인한다. (4) 체계성: 동일 깊이 범위 내에서 재조합 능력을 측정한다.
성능 결과는 다음과 같다. Equation Completion에서 Tree‑SMU는 Top‑5 정확도가 Tree‑LSTM보다 6% 높았으며, t‑SNE 시각화에서 표현이 보다 부드럽고 의미론적 변형에 강인함을 보였다. Equation Verification에서는 얕은 식에 대해 7%·깊은 식에 대해 2%의 정확도 향상을 기록했고, Transformer·Tree‑Transformer 대비 각각 18.5%·17.5%의 큰 격차를 보였다. 동일 깊이에서의 비교에서도 Tree‑SMU는 5‑6% 정도의 소폭 우위를 유지했으며, 파라미터 수는 동일한 은닉 차원 기준으로 Tree‑LSTM과 거의 차이가 없었다. 즉, 메모리 용량을 늘리는 것이 아니라 스택 기반 오류 보정 메커니즘이 핵심임을 입증한다.
샘플 효율성 실험에서는 훈련 데이터 비율을 감소시켜도 Tree‑SMU가 비교적 높은 정확도를 유지함을 보여, 데이터 효율성도 향상됨을 확인했다.
한계점으로는 스택 깊이 p와 top‑k k 같은 하이퍼파라미터가 도메인에 따라 민감하게 작용한다는 점, 현재 구현이 이진 트리 구조에 초점을 맞추었다는 점, 미분 가능한 스택 연산이 계산 비용을 증가시킬 수 있다는 점을 들 수 있다.
향후 연구 방향은 (1) 스택 외에 큐·덱·링 버퍼 등 다양한 메모리 구조를 혼합한 하이브리드 모델, (2) 자연어·시각적 도메인에서의 구성 일반화 테스트 확대, (3) 메모리 관리와 게이트 학습을 강화하는 정규화 기법 도입, (4) 메모리 압축 및 양자화 기법을 통한 경량화 등이 있다. 이러한 확장은 Tree‑SMU가 단순 수학 추론을 넘어 복합적인 인지 작업에서도 강력한 구성 일반화 능력을 발휘하도록 할 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기