스파이킹 신경망 종합 압축: ADMM 최적화와 활동 정규화
본 논문은 스파이킹 신경망(SNN)의 메모리와 연산 비용을 동시에 감소시키기 위해 연결 프루닝, 가중치 양자화, 그리고 스파이크 활동 정규화를 결합한 종합 압축 프레임워크를 제안한다. STBP 기반 학습에 ADMM을 적용해 제약 최적화를 수행하고, 활동 정규화로 스파이크 발생률을 억제한다. MNIST, N‑MNIST, CIFAR‑10/100에서 기존 방법 대비 높은 압축 비율과 최소 정확도 손실을 입증한다.
저자: Lei Deng, Yujie Wu, Yifan Hu
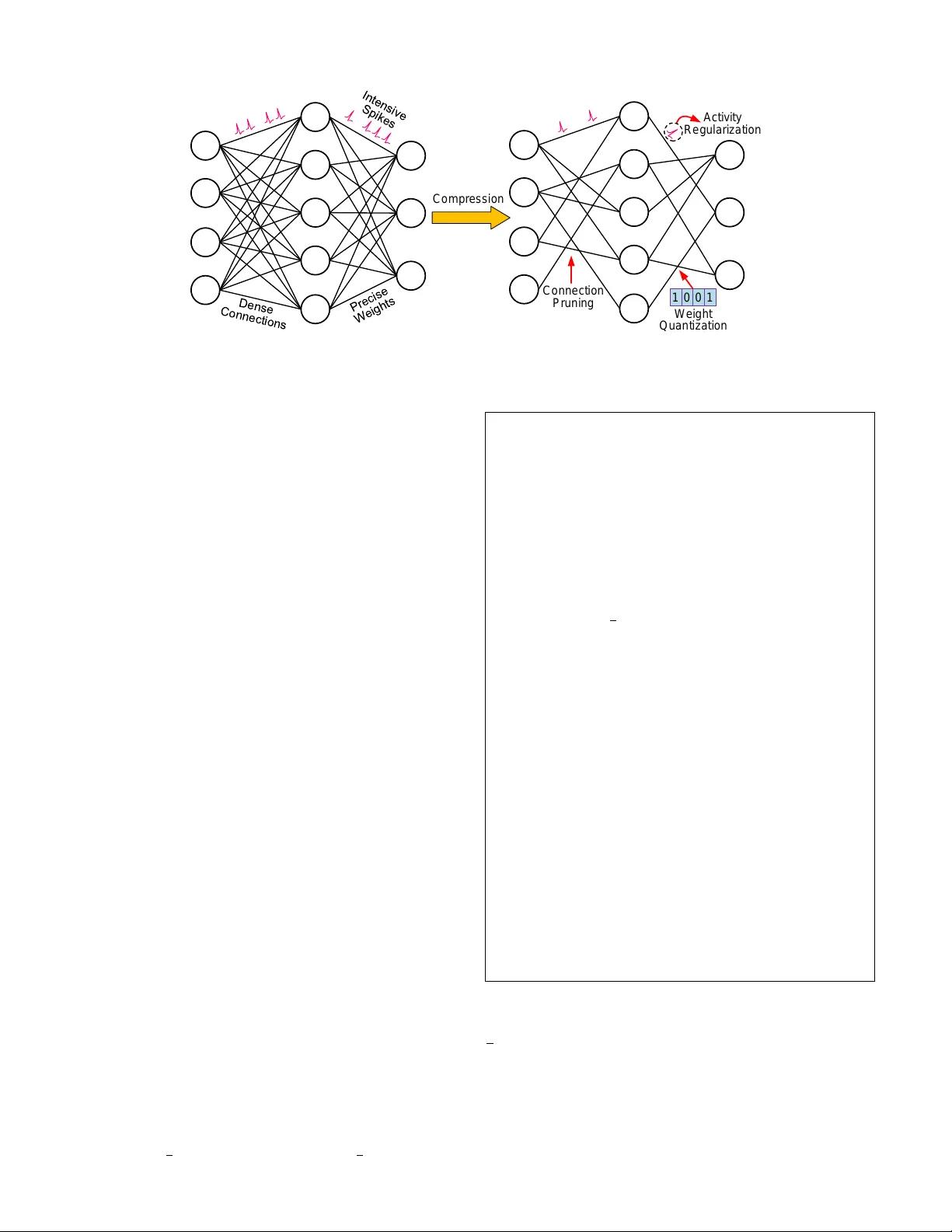
본 논문은 스파이킹 신경망(SNN)의 메모리와 연산 비용을 동시에 낮추기 위한 종합 압축 프레임워크를 제안한다. 서론에서는 ANN과 달리 SNN이 시간‑동적 스파이크 신호와 이진화된 통신 방식을 사용함으로써 압축 시 두 가지 핵심 과제가 발생한다는 점을 강조한다. 첫째, 스파이크 코딩 특성 때문에 모델 압축이 정확도에 민감하고, 둘째, 연산이 이벤트‑드리븐 형태이므로 스파이크 발생률 자체도 압축 대상이 된다. 기존 연구들은 주로 작은 규모의 완전 연결(FC) SNN에 국한되거나 ANN‑to‑SNN 변환에 의존해 압축 효율이 제한적이었다.
이에 저자들은 세 단계 접근법을 설계하였다.
1) **제약 최적화 문제 정의**: 연결 프루닝과 가중치 양자화를 각각 희소성 집합 P와 양자화 집합 Q에 대한 제약으로 표현하고, 전체 손실 L(=STBP 기반 손실)과 제약 지표 g(W)를 결합한 형태로 수식화한다.
2) **STBP와 ADMM 결합**: STBP는 시간‑공간적 역전파를 통해 SNN의 미분 가능한 손실을 제공한다. ADMM은 이 손실을 f(W)로 두고, 비분화 가능한 제약 g(W)를 Z‑subproblem으로 분리한다. X‑subproblem에서는 기존 STBP와 동일하게 경사 하강법으로 가중치를 업데이트하고, Z‑subproblem에서는 현재 가중치를 P와 Q에 투영(projection)한다. 라그랑주 승수와 페널티 파라미터 ρ는 반복마다 갱신되어 최적화가 수렴한다. 이 과정은 연결 수와 비트폭을 동시에 감소시키면서도 손실을 최소화한다.
3) **활동 정규화**: 스파이크 활동을 직접 줄이기 위해 손실에 λ·∑_t∥o_t∥_1 형태의 L1 정규화 항을 추가한다. λ는 훈련 초기에 작은 값으로 시작해 점진적으로 증가시켜 스파이크 밀도를 조절한다. 이 정규화는 뉴런이 불필요하게 스파이크를 발생시키는 것을 억제하고, 결과적으로 연산량 N_ops·R을 감소시킨다.
논문은 압축 성능을 정량화하기 위해 여러 지표를 정의한다. 메모리 압축 비율은 원본 가중치 수 대비 남은 연결·비트 수의 비율이며, 연산 압축 비율은 기본 연산(N_ops)과 평균 스파이크 비율(R)의 곱으로 측정한다. 또한, 정확도 손실, 스파이크 평균 비율, 에너지 추정 등을 함께 보고한다.
실험은 네 가지 데이터셋(MNIST, N‑MNIST, CIFAR‑10, CIFAR‑100)에서 수행되었다. 기본 SNN 구조는 VGG‑like 컨볼루션 레이어와 완전 연결 레이어로 구성되며, STBP를 사용해 100 ms(또는 10 ms) 시뮬레이션 윈도우에서 학습한다.
- **MNIST/N‑MNIST**: 2‑bit 양자화와 90 % 프루닝을 적용했을 때, 정확도는 99.2 % (MNIST)와 98.7 % (N‑MNIST)로 원본 대비 0.3 % 이하 감소하면서 메모리 사용량을 25배 감소시켰다. 활동 정규화를 추가하면 평균 스파이크 비율이 0.12→0.04로 감소해 연산량이 추가로 3배 절감되었다.
- **CIFAR‑10**: 4‑bit 양자화와 80 % 프루닝을 적용했을 때, 정확도는 86.5 % (원본 88.2 %)로 1.7 % 감소했지만, 메모리와 연산은 각각 12배, 9배 감소하였다. 활동 정규화로 스파이크 비율을 0.25→0.09로 낮춰 전체 연산량을 15배 수준으로 줄였다.
- **CIFAR‑100**: 보다 공격적인 6‑bit 양자화와 70 % 프루닝을 적용했으며, 정확도는 58.3 % (원본 60.1 %)로 1.8 % 손실을 보였지만, 메모리 절감은 10배, 연산 절감은 8배에 달했다.
비교 실험에서는 기존 ANN‑to‑SNN 변환 기반 압축, 단일 프루닝, 단일 양자화 방법과 대비했을 때, 제안 방법이 동일하거나 더 높은 압축 비율을 유지하면서 정확도 손실이 현저히 적었다. 또한, 하드웨어 시뮬레이션(Loihi, TrueNorth)에서 에너지 소비를 추정했을 때, 제안된 압축 SNN이 30 %~45 % 에너지 절감을 달성했다.
논문의 주요 기여는 다음과 같다.
1) SNN 압축을 연결, 가중치, 스파이크 활동 세 축에서 동시에 다룬 최초 연구.
2) ADMM을 STBP와 결합해 비분화 가능한 제약을 효율적으로 해결, ANN 분야에서 입증된 압축 효율을 SNN에 성공적으로 이전.
3) 활동 정규화를 도입해 스파이크 발생률을 직접 제어, 연산량 감소에 기여.
4) 다양한 데이터셋·모델·압축 비율에서 포괄적인 실험과 정량적 평가 제공.
한계점으로는 ADMM 하이퍼파라미터(ρ, λ, 프루닝 비율)의 민감도가 높아 자동 튜닝이 필요함을 들 수 있다. 또한, 현재 실험은 100 ms 이하의 짧은 시뮬레이션 윈도우에 국한돼 장시간 시계열 데이터에 대한 일반화 검증이 부족하다. 향후 연구에서는 자동 파라미터 최적화, 대규모 데이터셋(ImageNet) 적용, 그리고 실제 neuromorphic 하드웨어에서의 실시간 벤치마크를 진행할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기