구글 북스 코퍼스의 함정: 문화·언어 진화 추론의 한계
구글 북스 n‑gram 데이터는 방대한 양을 제공하지만, 한 권당 한 권만 포함되는 ‘도서관’ 특성, 과학·전문 서적 비중 증가, 그리고 저자별 편중 등으로 실제 문화적 인기와는 괴리가 있다. 특히 20세기 이후 과학 논문에서 등장하는 “Figure”와 같은 용어가 급증하면서 일반 언어 변화와 혼동된다. 이러한 한계를 극복하려면 데이터셋의 구성과 필터링 과정을 명확히 이해해야 한다.
저자: Eitan Adam Pechenick, Christopher M. Danforth, Peter Sheridan Dodds
이 논문은 구글 북스(Google Books) n‑gram 코퍼스가 문화·언어 진화 연구에 널리 사용되고 있음에도 불구하고, 데이터 자체가 가지고 있는 구조적 한계와 편향을 체계적으로 분석한다. 먼저, 구글 북스 코퍼스는 ‘도서관’ 형태로, 각 책이 한 번씩만 포함된다. 따라서 베스트셀러와 같은 실제 독자 선호도가 반영되지 않으며, 출판량이 많은 작가가 코퍼스 전체 어휘 변동에 과도한 영향을 미칠 수 있다. 저자들은 이러한 특성을 ‘lexicon‑like’이라고 정의하고, 텍스트 자체가 아니라 어휘 집합으로서의 성격을 강조한다.
다음으로, 코퍼스에 포함된 과학·전문 서적 비중이 20세기 초부터 급격히 증가했다는 점을 지적한다. 이는 “Figure”, “Table”, “citation” 등 학술적 용어가 1960년대 이후 급증하는 현상으로 나타난다. 특히 전체 영어 데이터셋(Version 1, Version 2)에서는 대문자 “Figure”가 소문자 “figure”를 앞서며, 이는 대학 도서관을 중심으로 한 과학 서적이 대량 디지털화된 결과로 해석된다. 반면, 두 번째 버전의 영어 Fiction 데이터셋은 이러한 과학 용어가 거의 사라져, 순수 문학적 어휘 변화를 반영한다는 점에서 차별화된다.
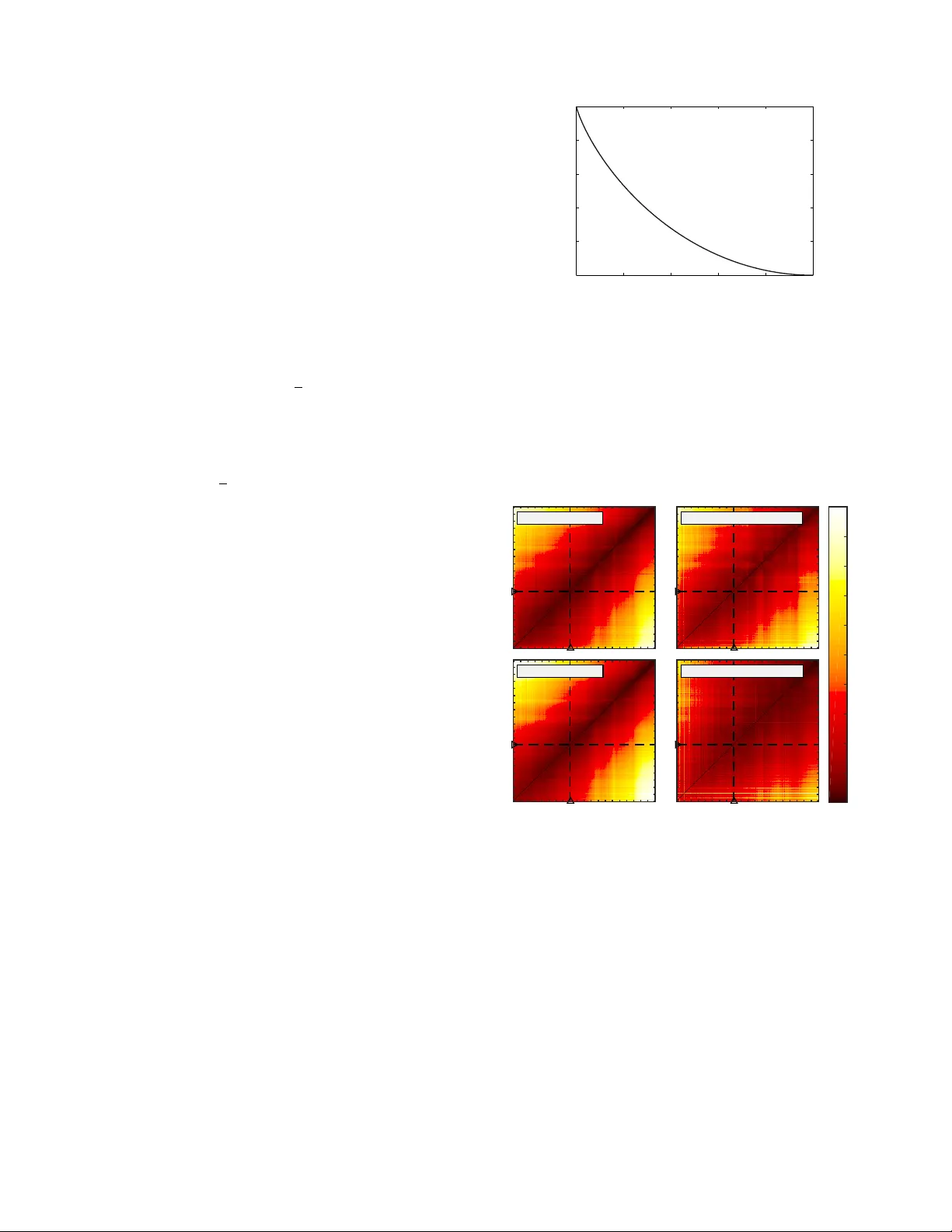
방법론적으로 저자들은 연도별 1‑gram 분포 차이를 정량화하기 위해 Jensen‑Shannon Divergence(JSD)를 사용한다. JSD는 KL 발산의 대칭적·유계 버전으로, 두 확률 분포 사이의 차이를 0~1 비트 범위로 측정한다. 논문은 JSD를 각 단어별 기여도로 분해하는 수식을 제시하고, 기여도는 평균 출현 빈도(m_i)와 비율(r_i = p_i/m_i)에 의해 결정된다고 설명한다. 이를 통해 흔히 사용되는 단어라도 작은 비율 변화가 큰 기여를 할 수 있고, 희귀 단어는 큰 비율 변화가 필요함을 시각화한다.
분석은 1800년부터 2000년까지의 데이터를 ‘십년 단위’로 평균화하여 수행되었다. 연도 간 JSD 히트맵을 통해 전쟁기(예: 1910‑1919, 1939‑1945)와 같은 급격한 언어 변동이 두드러졌으며, 특히 1880년을 기준으로 한 연도별 JSD 곡선은 전후로 큰 비대칭성을 보였다. 이는 전후 반세기 사이에 언어 사용이 크게 달라졌음을 의미한다.
또한, 저자별 편중 효과를 사례 연구로 제시한다. 특정 다작 작가가 특정 시기에 등장하는 새로운 용어나 고유명사를 대량 삽입함으로써 전체 코퍼스의 어휘 분포를 왜곡시킬 수 있음을 보여준다. 이는 특히 전체 영어 데이터셋에서 두드러지며, 문학 전용 데이터셋에서는 이러한 현상이 크게 감소한다.
결론적으로, 구글 북스 코퍼스를 문화·언어 트렌드 분석에 활용하려면 다음 세 가지 전제가 필요하다. 첫째, 코퍼스가 ‘도서관’ 특성을 갖고 있어 실제 독자 선호와는 차이가 있음을 인지한다. 둘째, 과학·전문 서적 비중이 시기별로 변동함을 보정한다. 셋째, 가능한 경우 필터링이 강화된 데이터셋, 특히 영어 Fiction 2nd version을 선택한다. 이러한 전제 하에만 코퍼스가 제공하는 어휘 변화가 실제 문화·언어 진화를 반영한다고 볼 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기