협업 로봇을 위한 파트너 모델링 기반 시뮬레이션 가속 강화학습
본 논문은 다중 에이전트 연속 제어 환경에서 파트너의 행동을 온라인으로 추정하고, 이를 시뮬레이션에 통합해 강화학습을 수행하는 “Partner Approximating Learner(PAL)” 프레임워크를 제안한다. 파트너 모델은 경험 재생(ER) 기반으로 지속 업데이트되며, 가상 복제 시스템에서 RL 에이전트가 정책을 학습한다. 실험은 두 에이전트가 토크를 가하는 진자 스윙업 과제에 적용돼, 실제 데이터 사용량을 크게 줄이면서 빠른 수렴과 파…
저자: Florian K"opf, Alex, er Nitsch
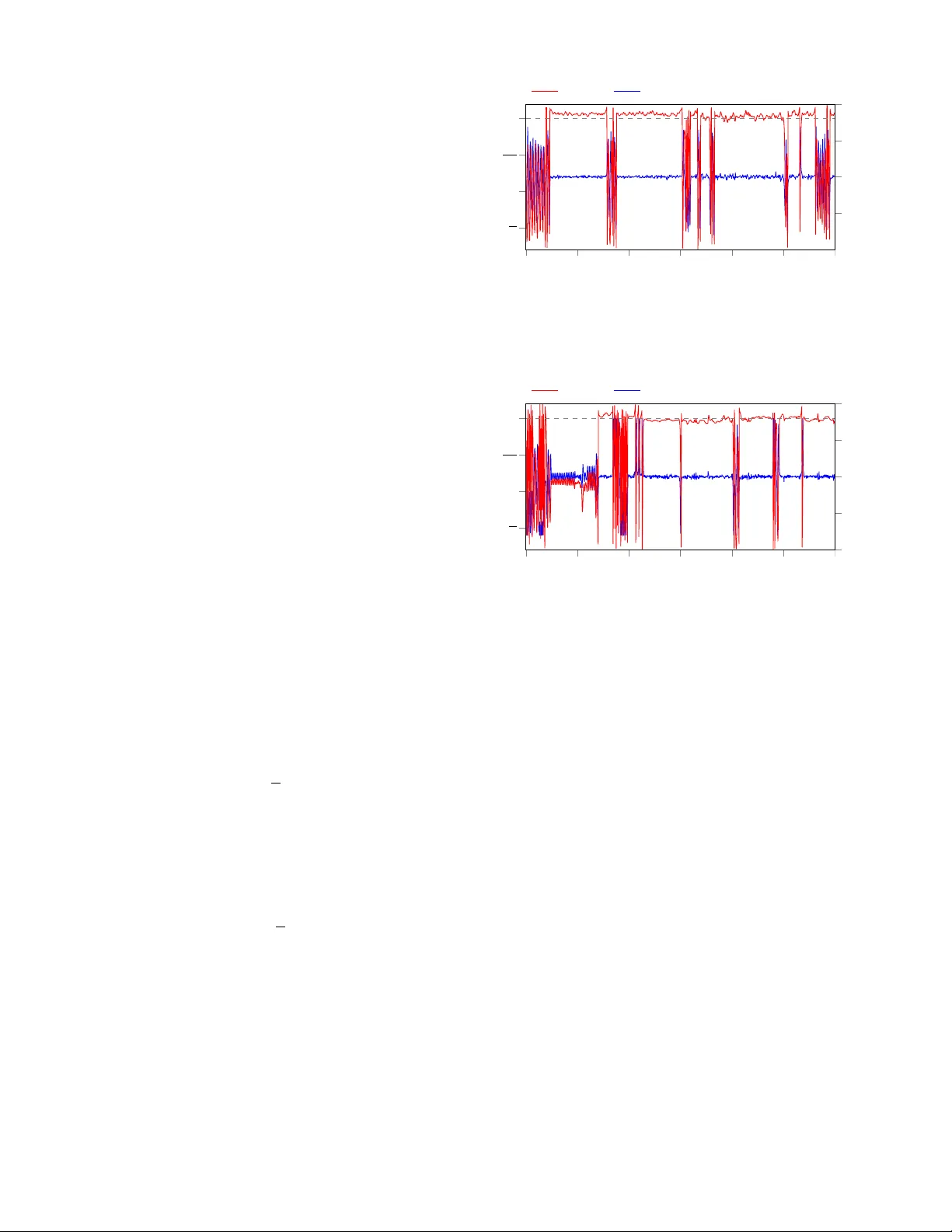
본 논문은 인간‑기계 혹은 로봇‑로봇과 같이 각기 다른 목표와 보상 구조를 가진 다중 에이전트 시스템에서, 에이전트가 서로의 제어 정책을 알지 못하고 통신도 없는 상황을 다룬다. 이러한 혼합 협력‑경쟁(mixed cooperative‑competitive) 환경에서는 기존의 독립 학습자(independent learner)가 비정상성(non‑stationarity) 때문에 성능이 급격히 저하되며, 완전 시뮬레이션 기반 학습은 파트너의 실제 행동 변화를 반영하지 못한다는 한계가 있다. 이를 해결하기 위해 저자들은 “Partner Approximating Learner(PAL)”라는 프레임워크를 제안한다. PAL은 세 가지 핵심 구성요소로 이루어진다.
1. **온라인 파트너 식별(Identification)**
- 각 에이전트는 파트너들의 집합적 제어 입력 u_p를 관측하고, 이를 입력‑출력 쌍 (x_k, u_p,k) 형태로 식별 버퍼 B_ID에 저장한다.
- 경험 재생(Experience Replay) 기법을 적용해 과거 데이터를 무작위 혹은 우선순위에 따라 샘플링하고, 다층 퍼셉트론(MLP) 등 강력한 함수 근사기로 파트너 모델 π̂_p(x) 를 학습한다.
- 파트너가 학습하거나 환경이 변할 경우에도 최신 데이터를 빠르게 반영하도록 CER(Combined Experience Replay)이나 PER(Prioritized Experience Replay) 등을 활용한다.
2. **내부 시뮬레이션(Internal Simulation)**
- 시스템 동역학 f는 사전에 알려져 있거나 모델링 가능하다는 전제 하에, 실제 제어 루프를 가상으로 복제한다.
- 복제된 루프는 현재 정책 π_i, 시스템 모델 f, 그리고 최신 파트너 모델 π̂_p를 결합해 하나의 MDP를 만든다.
- 이 MDP에서 연속적인 상태·액션·보상 데이터를 생성하고, 이를 RL replay buffer B_RL에 저장한다.
3. **강화학습(RL) 및 정책 전이(Policy Transfer)**
- 저자는 연속 제어에 적합한 DDPG(Deep Deterministic Policy Gradient)를 사용했으며, 이는 액터‑크리틱 구조로 정책 π_i와 가치 함수 Q를 동시에 학습한다.
- 시뮬레이션에서 학습된 정책은 실제 제어 루프에 바로 적용된다. 이후 실제 시스템에서 관측된 파트너 행동을 다시 식별 버퍼에 저장해 파트너 모델을 갱신하고, 이 과정을 반복한다.
실험은 두 에이전트가 동시에 토크를 가하는 진자 스윙업 과제로 수행되었다. 진자는 각 에이전트가 -5~+5 rad/s² 범위의 토크를 적용할 수 있으며, 목표는 진자를 수직으로 세우고 유지하는 것이었다. 실험 설정은 다음과 같다.
- **시스템 모델**: OpenAI Gym의 pendulum 모델을 기반으로, 두 토크 입력을 동시에 적용하도록 확장.
- **파트너 모델**: MLP (2 hidden layers, ReLU) 로 구현, CER을 통해 실시간 업데이트.
- **RL 알고리즘**: DDPG (actor와 critic 각각 2‑layer MLP), 경험 재생 버퍼 크기 1e6, 배치 크기 128.
- **비교 대상**: 독립 DDPG (파트너 모델 없이), 그리고 중앙집중식 MADDPG(통신 가정).
결과는 다음과 같다. PAL을 적용한 DDPG‑PAL은 독립 DDPG에 비해 학습 초기 200 에피소드 내에 평균 보상이 2.5배 상승했으며, 파트너가 목표 위치를 바꾸거나 제어 전략을 바꿨을 때도 정책 재학습이 1~2 에피소드 내에 이루어졌다. 또한 실제 물리 실험이 아닌 가상 ‘실제 시스템’ 시뮬레이션에서도 파트너 모델 업데이트만으로 현실과 거의 동일한 동작을 재현했다. 이는 PAL이 데이터 효율성을 크게 향상시키고, 비정상성을 효과적으로 다룰 수 있음을 보여준다.
논문의 주요 기여는 다음과 같다.
- **파트너 모델링과 시뮬레이션 기반 RL의 통합**: 기존 Dyna‑architecture를 다중 에이전트 연속 제어에 확장.
- **경험 재생 기반 온라인 식별**: 파트너 행동을 지속적으로 추정해 비정상성에 대응.
- **모듈성 및 확장성**: 파트너 식별 알고리즘, RL 알고리즘, 시스템 모델을 자유롭게 교체 가능.
- **실제 적용 가능성**: 인간‑기계 협업, 로봇 협동, 자동 운전 등에서 실시간 데이터 수집이 제한적인 상황에 적합.
한계점으로는 시스템 동역학이 정확히 알려져 있거나 고품질 모델링이 가능한 경우에만 적용 가능하다는 점, 파트너 모델의 오차가 누적될 경우 시뮬레이션 정책이 실제와 괴리될 위험이 있다는 점을 들 수 있다. 향후 연구에서는 베이지안 신경망을 이용한 불확실성 추정, 파트너 모델과 정책을 공동 최적화하는 메타‑학습, 그리고 인간 파트너의 비선형·비정형 행동을 다루는 확장 등을 제안한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기