시간 변동 궤적 추적을 위한 모델 없는 적응 동적 프로그래밍
본 연구는 알려지지 않은 시스템에 대해 최적의 추적 제어기를 학습하는 적응 동적 프로그래밍(ADP) 방법을 제안한다. 기존 방법이 시간 불변 외부 시스템 동역학을 가정하는 한계를 극복하기 위해, 참조 궤적을 매개변수화하여 명시적으로 포함하는 새로운 Q-함수를 도입한다. 이 PRADP 방법은 학습 후 추가 훈련 없이도 시간에 따라 변하는 다양한 참조 궤적을 추적할 수 있으며, 선형 이차 추적 사례에서의 분석과 시뮬레이션을 통해 기존 방법 대비 향…
저자: Florian K"opf, Simon Ramsteiner, Michael Flad
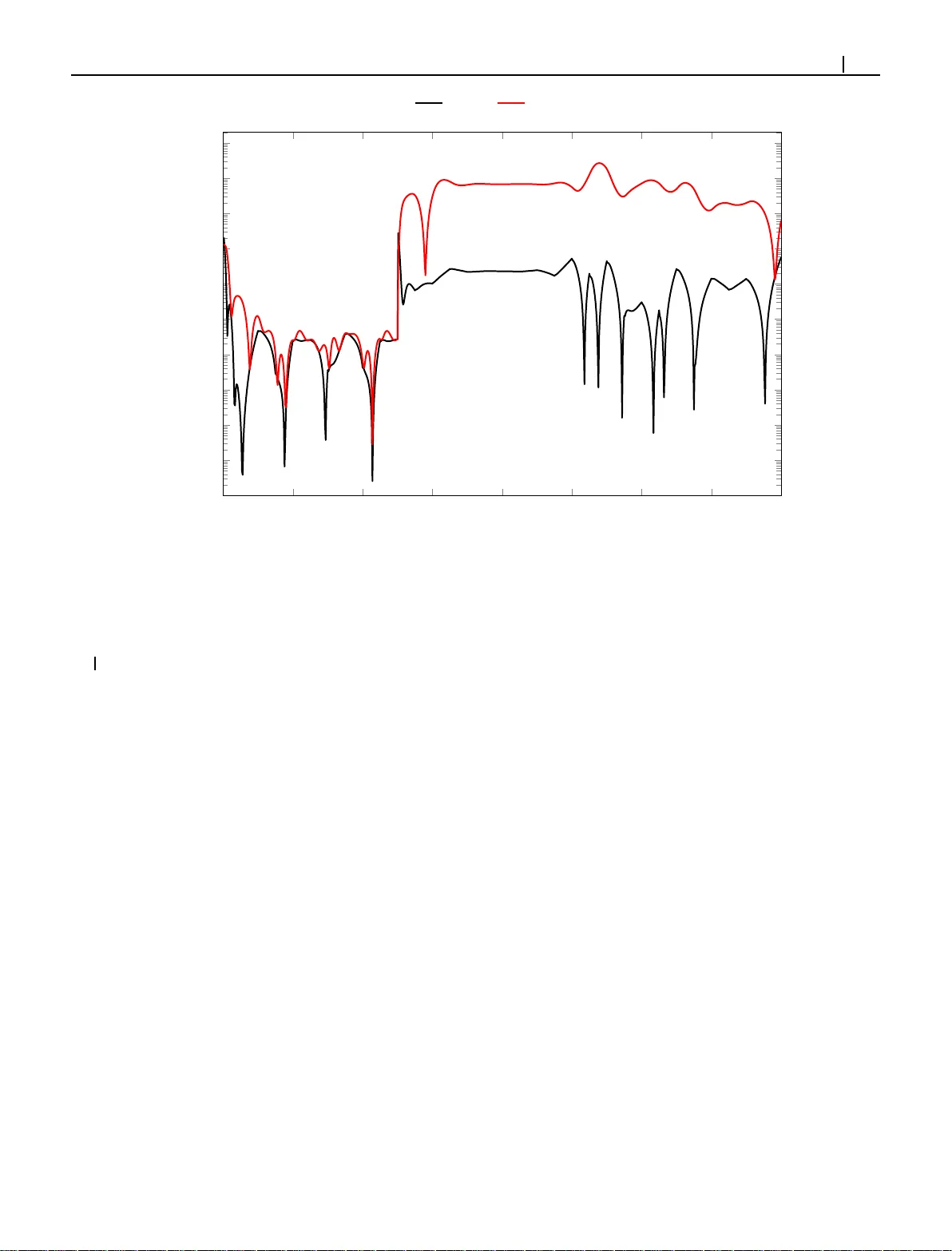
이 논문은 시스템 모델을 알지 못하는 상황에서 원하는 궤적을 추적하는 최적 제어기를 자율적으로 학습시키기 위한 새로운 적응 동적 프로그래밍(ADP) 방법을 제안한다. 기존의 ADP 기반 추적 제어 연구들은 대부분 참조 궤적이 시간 불변의 선형 동역학(외부 시스템)을 따른다고 가정하였다. 이는 참조 궤적이 변경될 때마다 제어기를 완전히 재설계하거나 재학습해야 하는 실용적인 한계를 지니며, 인간-기계 협업이나 자율 주행과 같이 유연하고 시간에 따라 변하는 궤적 추적이 필요한 많은 응용 분야에 부적합하다.
이러한 문제 인식에서 출발하여, 본 연구에서는 참조 궤적을 명시적으로 Q-함수에 통합하는 근본적으로 새로운 접근법을 소개한다. 구체적으로, 참조 궤적 𝒓(𝑡)을 매개변수 행렬 𝑷_𝑘와 기저 함수 벡터 𝝆(𝑡)의 곱으로 근사화한다(𝒓(𝑷_𝑘, 𝑡) = 𝑷_𝑘 𝝆(𝑡)). 이 매개변수 𝑷_𝑘는 시간 𝑘에 따라 변할 수 있어 시간 변동 궤적을 표현할 수 있다. 저자들은 기존의 상태-제어 Q-함수 대신, 상태 𝒙_𝑘, 제어 입력 𝒖_𝑘, 그리고 참조 매개변수 𝑷_𝑘를 모두 입력으로 하는 새로운 '매개변수화 참조 Q-함수' 𝑄(𝒙_𝑘, 𝒖_𝑘, 𝑷_𝑘)를 정의한다. 이 Q-함수의 값은 현재 상태에서 현재 제어를 적용하고, 이후 현재 참조 매개변수 𝑷_𝑘로 정의된 궤적을 따라갈 때 발생할 것으로 예상되는 총 예상 할인 비용을 나타낸다.
이 Q-함수의 핵심 속성은 Bellman 최적성 원리를 만족시킨다는 점이다. 이를 통해 최적 Q-함수 𝑄∗를 알면, 주어진 상태와 참조 궤적에 대해 비용을 최소화하는 최적 제어 입력을 𝒖∗_𝑘 = argmin_𝒖 𝑄∗(𝒙_𝑘, 𝒖, 𝑷_𝑘)로 바로 계산할 수 있다. 시스템 모델을 모르기 때문에, 저자들은 이 Q-함수를 선형 함수 근사화 𝑄̂(𝒙, 𝒖, 𝑷) = 𝒘̂⊺ 𝝓(𝒙, 𝒖, 𝑷)로 표현하고, 시스템과의 상호작용으로 수집된 데이터를 바탕으로 미지의 가중치 벡터 𝒘를 추정하는 방법을 제시한다. 데이터는 (𝒙_𝑘, 𝒖_𝑘, 𝑷_𝑘, 비용, 𝒙_𝑘+1, 𝑷_𝑘+1) 형태의 튜플로 구성된다. 학습 알고리즘은 정책 평가와 정책 개선 단계를 반복하는 LSPI(Least-Squares Policy Iteration)를 채택하며, TD 오차를 최소화하는 최소자승 문제를 풀어 가중치를 업데이트한다. 이 방법은 오프-폴리시 학습이므로, 탐색을 위한 행동 정책과 학습의 대상이 되는 탐욕적 목표 정책을 분리할 수 있다.
이 일반적인 방법론의 유용성과 구조를 입증하기 위해 저자들은 선형 시스템과 이차 비용 함수로 정의되는 중요한 특수 경우인 선형 이차(LQ) 추적 문제를 심층 분석한다. 이 경우 최적 제어 법칙이 선형 상태-피드백과 참조 궤적의 선형 조합으로 나타난다는 기존의 알려진 해법을 활용하여, 이론적인 최적 Q-함수 𝑄∗가 상태, 제어, 참조 매개변수의 이차 형식으로 표현됨을 보여준다. 이는 함수 근사화를 위한 기저 함수 𝝓(⋅)를 이차 항들(예: 𝒙⊗𝒙, 𝒖⊗𝒖, vec(𝑷)⊗vec(𝑷) 등의 크로네커 곱 항)로 구성해야 함을 명시적으로 알려주며, 이를 통해 함수 근사화의 정확도를 보장할 수 있다.
마지막으로, 저자들은 2차원 선형 시스템을 이용한 수치 시뮬레이션 예제를 통해 PRADP의 성능을 입증한다. 학습 단계에서는 다양한 참조 매개변수 𝑷_𝑘에 대해 탐색 노이즈를 포함한 데이터를 수집하여 Q-함수의 가중치를 학습한다. 테스트 단계에서는 학습 과정에서 보지 못한 새로운 시간 변동 참조 궤적(예: 서로 다른 주파수를 가진 정현파)을 제시한다. 실험 결과, 제안된 PRADP 방법은 기존의 시간 불변 외부 시스템 동역학을 가정한 ADP 방법보다 현저히 낮은 추적 오차와 누적 비용을 기록하며, 이론적으로 계산된 최적 제어기 성능에 매우 근접하는 것을 확인한다. 이는 PRADP가 단일의 학습된 Q-함수로 광범위한 시간 변동 궤적을 성공적으로 추적할 수 있음을 의미한다. 논문은 이 방법이 모델에 대한 지식이 부족하고 참조 궤적이 유연하게 변화해야 하는 실세계 제어 문제에 효과적인 해법이 될 수 있음을 결론지으며, 미래 연구 방향으로 비선형 시스템으로의 확장을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기