분류 정확도를 이용한 두 표본 검정: 고차원에서의 이론과 실용적 함의
본 논문은 분류기의 정확도가 우연보다 ε만큼 높을 때, 해당 정확도를 검정통계량으로 사용하면 두 표본 검정이 가능함을 보인다. 고차원( d,n →∞) 상황에서 퍼뮤테이션 검정과 가우시안 근사 검정이 모두 일관성을 가지며, 특히 가우시안 평균 차이 검정에서 LDA·나이브 베이즈와 Hotelling 검정의 검정력 차이가 상수 1/√π 정도임을 밝혀냈다. 또한 타원형 분포와 최소극값 하한을 포함한 일반화 결과를 제시한다.
저자: Ilmun Kim, Aaditya Ramdas, Aarti Singh
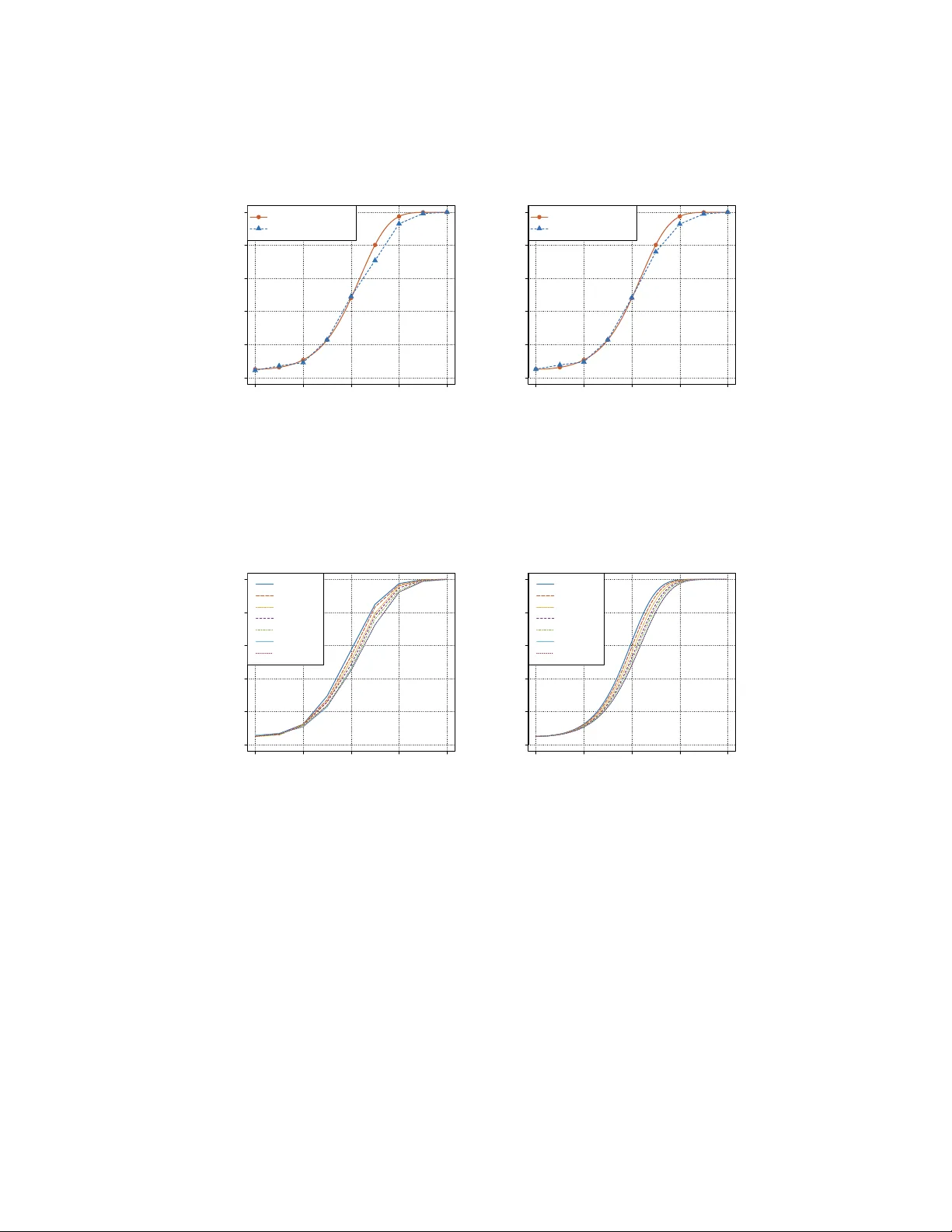
본 논문은 데이터 분석가가 분류기를 학습한 뒤 그 정확도가 우연(½)보다 유의하게 높은지를 검정함으로써 두 표본 검정을 수행한다는 사실을 이론적으로 정립한다. 먼저, 모든 차원(d)와 표본 수(n)에서 “true error가 ε>0 만큼 chance보다 작다”는 약한 가정만으로 두 가지 검정 방법이 일관성을 갖는다는 일반 결과를 제시한다. (a) 퍼뮤테이션 검정은 유한 표본에서도 정확한 수준 α를 유지하면서, 충분히 많은 퍼뮤테이션을 수행하면 파워가 1에 수렴한다. (b) null 분포를 가우시안으로 근사한 검정은 고차원 asymptotic regime에서 type‑I error를 정확히 제어하고, 동일한 ε 조건 하에 일관적이다.
이후 고차원 가우시안 평균 차이 검정(공통 공분산 Σ, d/n→c∈(0,∞))에 초점을 맞춘다. Fisher LDA를 샘플 스플리팅으로 추정하고, 그 정확도를 중심·표준화한 통계량 Tₙ을 정의한다. 정리 5.1에 의해 Tₙ는 null와 local alternative 모두에서 N(0,1)으로 수렴한다. 이를 이용해 검정력 식 (6.7)을 도출했으며, 이는 Hotelling T², Bai‑Saranadasa, Srivastava‑Du 등 기존 두 표본 평균 검정의 파워와 동일함을 확인한다. 다만 LDA 기반 검정은 상수 1/√π 만큼 효율이 낮아, 균형 샘플( n₁≈n₂ )에서 ARE≈0.564를 보인다.
공분산이 알려지지 않은 경우에도 “naïve Bayes”(공분산을 대각선으로 근사)와 같은 선형 분류기를 사용하면 동일한 파워 식을 얻으며, ARE 역시 1/√π이다(정리 7.1). 이는 고차원에서 공분산 추정이 어려운 현실을 반영한다.
타원형 분포(유한 kurtosis)로 일반화한 결과(정리 8.1)에서는 가우시안 경우와 동일한 형태의 파워 식이 나오지만, 상수는 √2·fₓ(0) 로 조정된다. 특히 다변량 t‑분포와 같이 꼬리가 무거운 경우, 이 상수가 1보다 커져 LDA 기반 검정이 Hotelling보다 상대적으로 더 효율적일 수 있음을 보여준다.
논문은 또한 고차원 두 표본 평균 검정의 minimax 하한을 정확히 구하고(명제 3.1), d=o(n) 일 때 Hotelling T²가 이 하한을 달성함을 증명한다(정리 4.1). 이는 기존에 “Hotelling은 고차원에서 무력하다”는 인식을 정정한다.
실험에서는 가우시안, t‑분포, 실제 뇌영상 데이터 등을 사용해 제안한 LDA/naïve Bayes 기반 검정과 Hotelling, 그래프 기반 검정(k‑NN, MST 등)을 비교한다. 시뮬레이션 결과는 이론적 파워 식과 매우 일치하며, 차원·표본 비율이 0.5~2 사이일 때 LDA 기반 검정이 실용적으로 충분히 강력함을 확인한다.
실용적 메시지는 두 가지로 정리된다. 첫째, 데이터가 구조화되지 않았거나 대체 검정통계량을 설계하기 어려운 경우, 복잡한 분류기(예: CNN, Random Forest)를 이용한 정확도 검정이 합리적인 선택이 될 수 있다. 둘째, 데이터가 충분히 풍부하고 구조가 명확하면, Hotelling이나 고차원 전용 검정(스케일된 T², 그래프 검정 등)을 사용하는 것이 파워 면에서 더 유리하다.
결론적으로, 이 연구는 머신러닝 실무에서 흔히 사용되는 “분류 정확도”를 고차원 가설 검정의 엄밀한 통계적 도구로 전환하는 이론적 토대를 제공한다. 퍼뮤테이션 검정과 가우시안 근사 검정 모두 일관성을 보이며, LDA 기반 검정은 Hotelling에 비해 상수 수준의 효율 손실만을 가지고 있다. 이는 실무에서 복잡한 분류기를 활용해 두 표본 차이를 검정하고자 하는 연구자들에게 강력한 근거를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기