쿠르노 게임에서 무후회 학습의 최종 수렴 분석
** 본 논문은 정보가 제한된 상황에서 플레이어가 밴딧 혹은 그래디언트 피드백을 이용해 무후회 학습을 수행할 때, 연속 행동 공간을 갖는 쿠르노 게임의 실제 행동이 유일한 내시 균형으로 수렴함을 보인다. 새로운 수렴 개념인 ‘측도 내 수렴’을 도입하고, 시간 평균과 최종 반복 모두에 대해 수렴 속도를 명시적으로 제시한다. **
저자: Yuanyuan Shi, Baosen Zhang
**
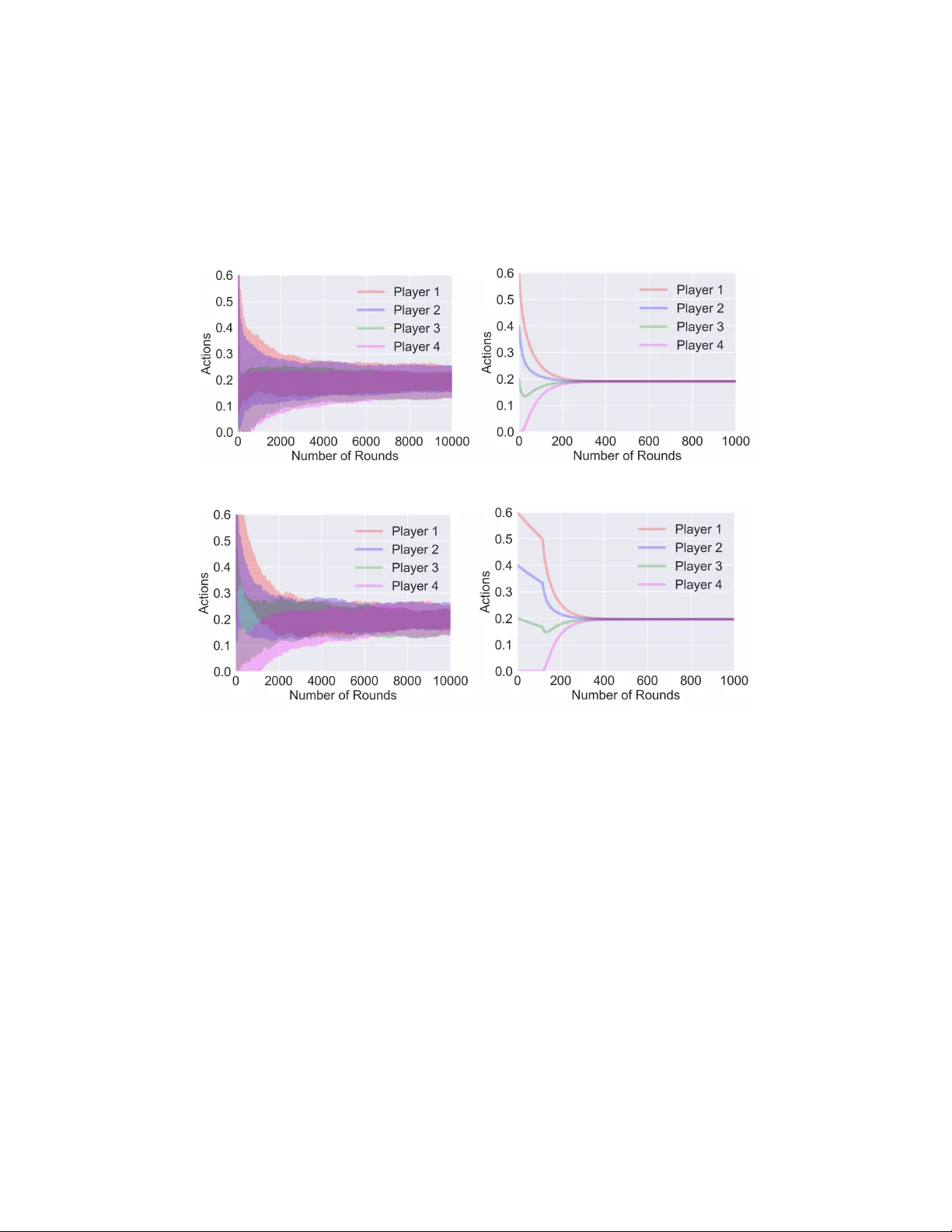
본 연구는 정보가 제한된 환경에서 플레이어들이 무후회 학습 알고리즘을 이용해 쿠르노 게임에서 어떻게 행동을 조정하고, 최종적으로 유일한 내시 균형(Nash equilibrium, NE)으로 수렴하는지를 체계적으로 분석한다. 쿠르노 게임은 N명의 기업이 동일한 제품을 생산하고, 총 생산량에 따라 시장 가격이 결정되는 전형적인 경쟁 모델이다. 각 기업 i는 생산량 x_i≥0를 선택하고, 그에 대한 이익은 π_i(x)=p(∑_j x_j)·x_i−C_i(x_i) 로 정의된다. 여기서 p(·)는 총 생산량에 대한 가격 함수이며, C_i(·)는 생산 비용 함수이다. 논문은 다음과 같은 두 가지 핵심 가정을 둔다. 첫째, 가격 함수 p는 구간
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기