다채널 음성 향상을 위한 텐서‑트레인 기반 텐서‑투‑벡터 회귀
본 논문은 다채널 음성 향상 문제를 기존 DNN 기반 벡터‑투‑벡터 회귀에서 텐서‑트레인 네트워크(TTN)로 변환한 텐서‑투‑벡터 회귀 방식으로 재구성한다. TTN은 완전 연결층을 텐서‑트레인 형태로 압축해 파라미터 수를 크게 줄이면서도 표현력을 유지한다. 실험 결과, 단일 채널에서는 파라미터를 27 M→5 M(≈81 % 감소)으로 줄여도 PESQ 2.86→2.84 수준을 유지하고, 파라미터를 20 M까지 늘리면 PESQ 2.96까지 향상시켰다…
저자: Jun Qi, Hu Hu, Yannan Wang
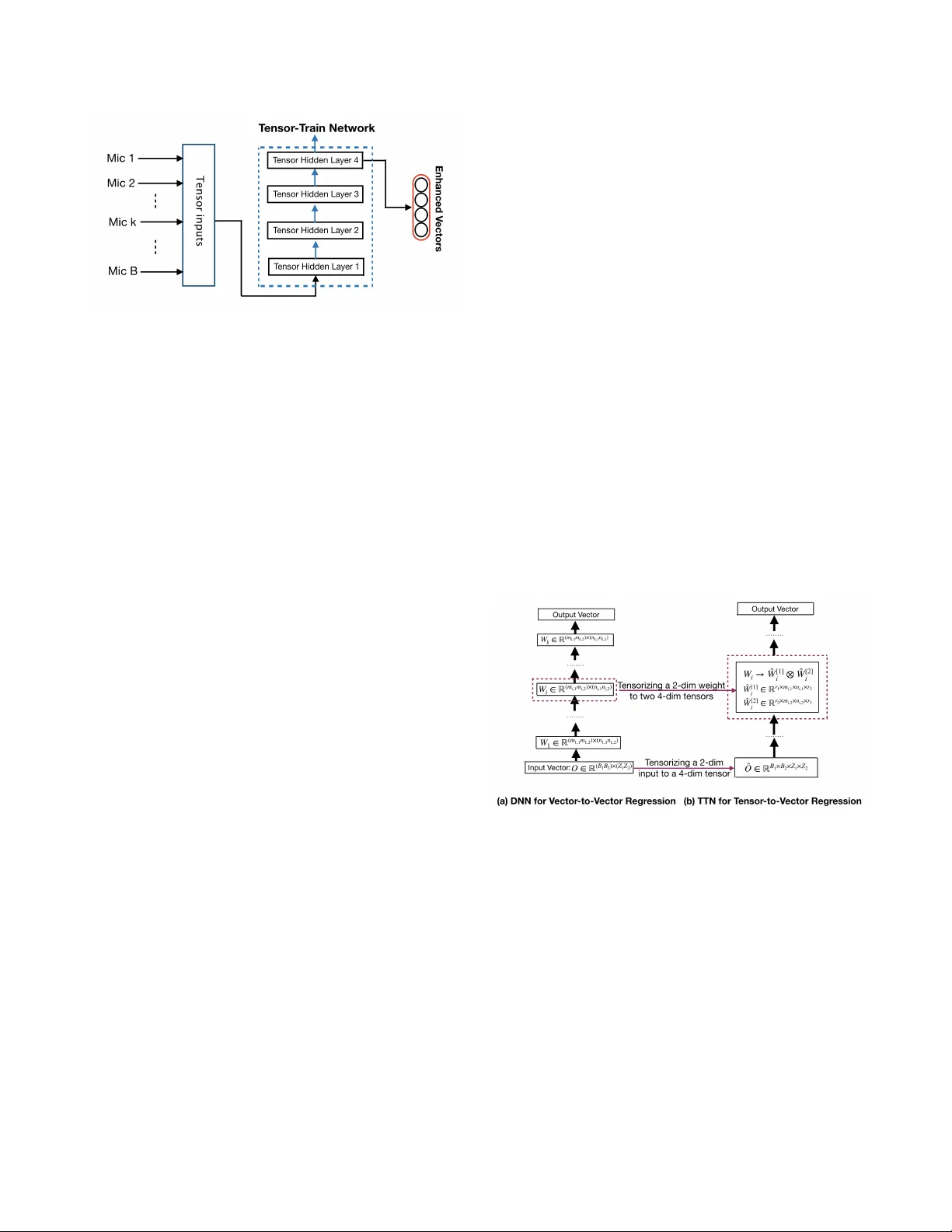
본 논문은 다채널 음성 향상에서 발생하는 입력 차원 폭발과 은닉층 규모 확대 문제를 해결하기 위해 텐서‑트레인 네트워크(TTN)를 기반으로 한 텐서‑투‑벡터 회귀 방식을 제안한다. 기존의 DNN 기반 벡터‑투‑벡터 회귀는 여러 마이크로부터 얻은 스펙트럼 특성을 단순히 연결해 고차원 입력 벡터를 만든다. 이 경우 입력 차원이 B·257·(2M+1) (B는 마이크 수, M은 컨텍스트 프레임 수)로 급증하면서, 이론적으로 각 은닉층의 최소 폭이 입력 차원+2 이상이어야 충분한 표현력을 보장한다는 기존 연구(
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기