에너지 효율적인 ReRAM 기반 신경망 학습 가속기 PANTHER
PANTHER는 ReRAM 교차점 배열을 활용해 외적 누적(OPA) 연산을 고정밀 비트 슬라이싱 기법으로 구현하고, 이를 MVM과 결합한 ISA‑프로그램 가능한 학습 가속기이다. 세 가지 훈련 알고리즘에 맞춘 교차점 구조와 컴파일러 지원을 통해 완전 연결, 합성곱 등 다양한 레이어를 가속하며, 기존 디지털 가속기 대비 최대 103배, GPU 대비 16배의 에너지·시간 효율을 달성한다.
저자: Aayush Ankit, Izzat El Hajj, Sai Rahul Chalamalasetti
1. 서론 및 배경
딥 뉴럴 네트워크(DNN)의 학습은 대규모 행렬 연산과 반복적인 가중치 업데이트로 인해 막대한 전력과 시간 비용을 요구한다. 기존 디지털 가속기와 하이브리드 디지털‑아날로그 가속기(특히 ReRAM 교차점 배열 기반)는 MVM 연산을 아날로그적으로 수행해 에너지 효율을 크게 개선했지만, 학습 단계에서 필수적인 가중치 외적 누적(OPA) 연산은 여전히 직렬적인 셀 읽기·쓰기 방식에 의존해 전체 효율을 저해한다.
2. 문제점 정의
- 기존 OPA 구현은 2~5비트 저정밀도에 국한되어 실제 학습에 필요한 16~32비트 정밀도를 제공하지 못한다.
- OPA는 가중치가 실시간으로 변하기 때문에 오버플로우와 포화 관리가 필요하지만, 기존 설계는 이를 고려하지 않는다.
- 현재는 SGD(배치 1)와 완전 연결 레이어에만 적용 가능해, 합성곱, 미니배치, 대규모 배치 학습에 확장성이 부족하다.
3. 비트‑슬라싱 기법
저자들은 OPA 연산을 16비트 입력·출력으로 확장하기 위해 세 가지 핵심 아이디어를 제시한다.
① 행 입력은 1비트씩 PWM 방식으로 시간에 따라 스트리밍한다. 이는 DAC 해상도를 높이지 않아도 되므로 전력 소모를 최소화한다.
② 열 입력은 p비트씩 PAM 방식으로 슬라이스해 여러 교차점 배열에 동시에 적용한다. 열 입력을 왼쪽으로 n비트씩 시프트하면서 각 슬라이스에 할당한다.
③ 가중치 자체를 여러 교차점 배열에 이질적으로(bit‑heterogeneous) 분할 저장한다. 각 슬라이스는 기본 비트와 오버플로우를 저장할 추가 비트를 포함한다. 이렇게 하면 누적 과정에서 발생하는 캐리를 손실 없이 보존할 수 있다.
4. 하드웨어 아키텍처
세 가지 변형 구조가 제안된다.
- Variant‑1: 단일 교차점 배열 기반 SGD 전용 구조. 낮은 배치 크기에 최적화돼 최소 지연을 제공한다.
- Variant‑2: 미니배치 SGD용 다중 교차점 배열. 배치당 여러 OPA 연산을 병렬 처리해 처리량을 높인다.
- Variant‑3: 대규모 배치 학습용 파이프라인 구조. 입력 스트리밍과 슬라이스 연산을 단계별 파이프라인화해 메모리 대역폭 요구를 완화한다.
각 변형은 ADC/DAC 정밀도, 슬라이스 수, 오버플로우 비트 수 등을 레이어와 배치 크기에 맞게 동적으로 조정한다. 또한, 부호‑크기(signed‑magnitude) 표현과 중앙 바이어스 방식을 도입해 양극·음극 업데이트를 동일하게 처리한다. 이를 위해 교차점 배열에 하나의 보조 열을 추가하는 최소 오버헤드만 필요하다.
5. ISA 및 컴파일러
PANTHER는 명령어 집합에 MVM, MT‑MVM, OPA, 비트‑슬라이스 제어, 오버플로우 관리 등을 포함한다. 컴파일러는 고수준 딥러닝 프레임워크 모델을 받아 레이어별 연산 유형을 분석하고, 최적 슬라이스 구성·스케줄링을 자동 생성한다. 이를 통해 개발자는 기존 프레임워크 코드를 크게 수정하지 않고도 PANTHER를 활용할 수 있다.
6. 평가 및 결과
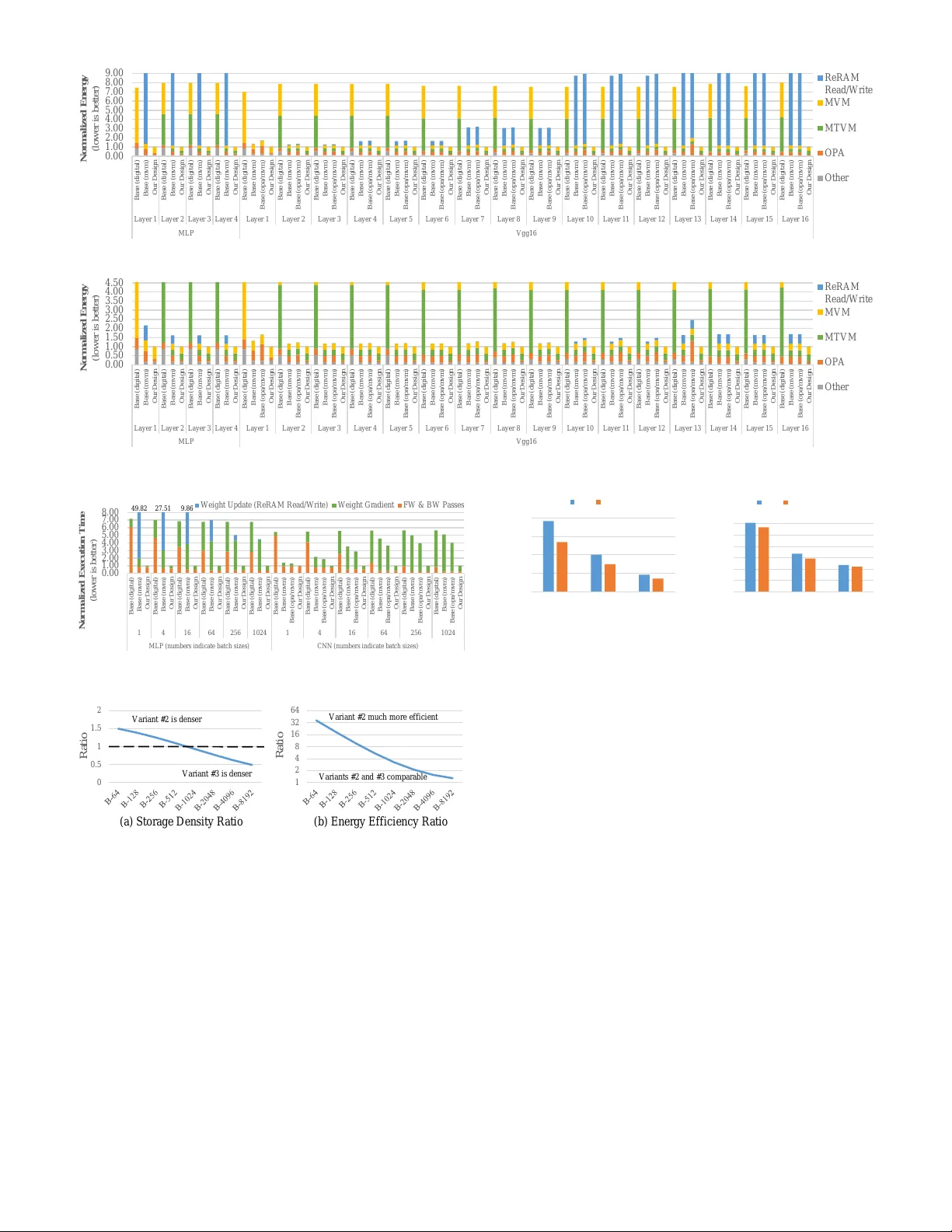
- 실험 환경: CIFAR‑10, ImageNet, ResNet‑50, VGG‑16 등 표준 모델을 대상으로 16‑bit 고정소수점 훈련을 수행.
- 에너지 효율: 디지털 전용 가속기 대비 최대 8.02배, 기존 ReRAM 기반 가속기 대비 54.21배, GPU 대비 103배 절감.
- 실행 시간: 디지털 가속기 대비 7.16배, 기존 ReRAM 가속기 대비 4.02배, GPU 대비 16배 가속.
- 정확도 손실: 비트‑슬라싱으로 인한 양자화 오차는 <0.2% 수준으로, 기존 32‑bit 부동소수점 기준과 거의 동일한 학습 결과를 얻었다.
7. 논의 및 향후 과제
- 비트‑슬라싱 기법은 ReRAM 외에도 PCM, MRAM 등 다른 비휘발성 메모리에도 적용 가능하다는 점에서 범용성을 가진다.
- 현재는 128×128 교차점 배열을 기준으로 설계했지만, 더 큰 배열이나 3D 적층 구조와 결합하면 면적·전력 효율이 더욱 개선될 전망이다.
- 온칩 온도·노이즈에 대한 내성 및 장기 신뢰성 평가가 필요하며, 이를 위한 보정 회로와 오류 정정 기법이 향후 연구 과제로 제시된다.
결론적으로, PANTHER는 ReRAM 교차점 배열의 아날로그 연산 장점을 학습 단계 전체에 확장함으로써, 고정밀·고효율 신경망 학습을 실현한 최초의 프로그래머블 가속기라 할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기