데이터가 더 많을수록 해가 될 수 있다: 샘플 기반 이중 하강 현상
선형 회귀에서 차원(d)이 샘플 수(n)보다 클 때, 최소 노름 무정규화 해를 gradient descent로 구하면 테스트 위험이 n에 따라 비단조적으로 변한다. 특히 n = d에서 위험이 급격히 상승하는 ‘샘플‑와이즈 이중 하강’ 현상이 나타난다. 이는 과잉 파라미터화 영역에서 편향은 감소하지만 분산이 급증하기 때문이다.
저자: Preetum Nakkiran
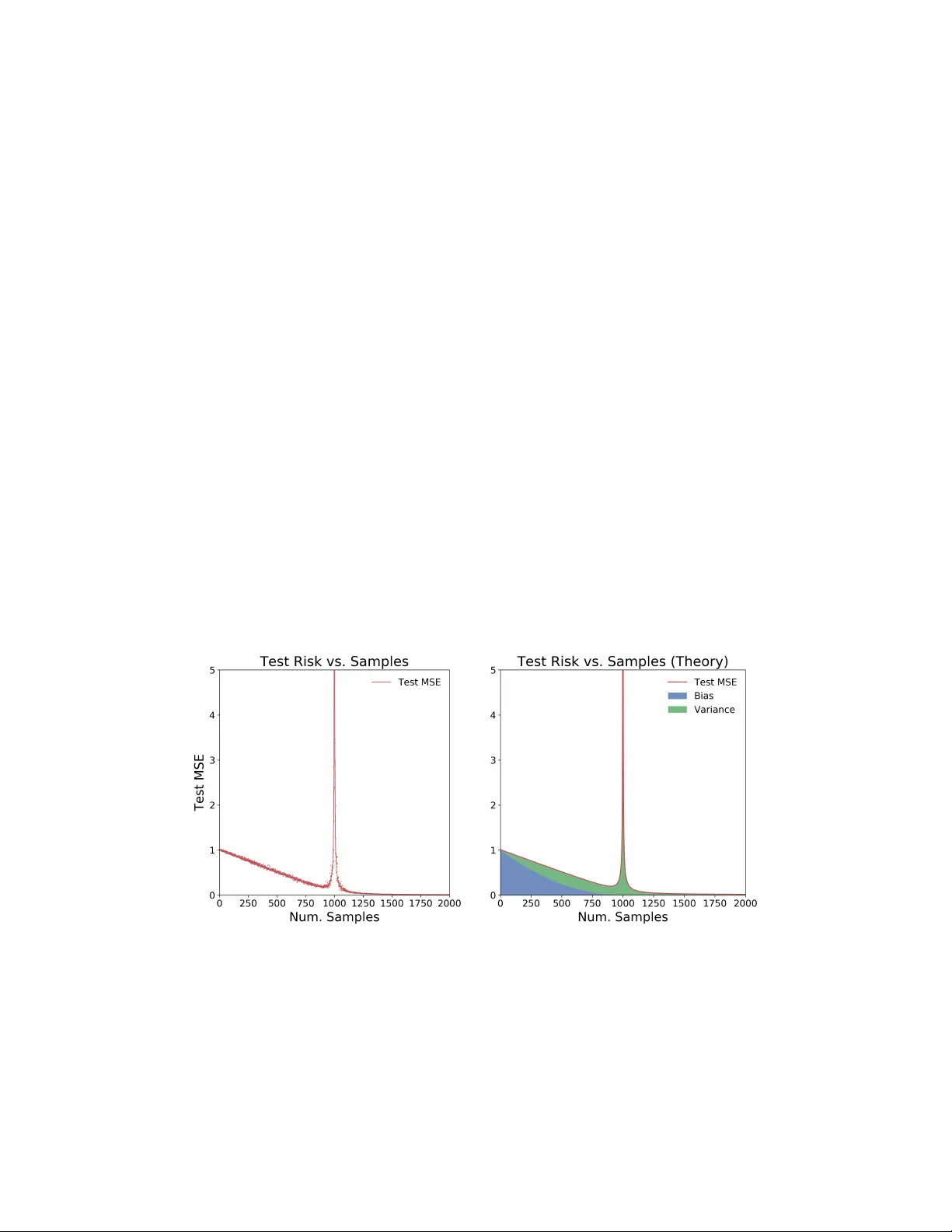
본 논문은 “샘플‑와이즈 이중 하강(sample‑wise double descent)”이라는 현상을 선형 회귀 모델에서 명확히 보여준다. 저자는 차원 d가 고정된 상황에서 샘플 수 n을 변화시켜, 최소 노름 무정규화(ridgeless) 회귀 해를 gradient descent로 구했을 때 테스트 평균제곱오차(MSE)의 비단조적 변화를 관찰한다. 실험(Figure 1a)에서는 n이 d에 가까워질수록 위험이 급격히 상승하고, n > d가 되면 다시 감소하는 전형적인 이중 하강 곡선이 나타난다.
문제 설정은 다음과 같다. 입력 x∈ℝ^{d}는 표준 정규분포 N(0,I_d)를 따르고, 응답 y는 y = xᵀβ + ε, ε∼N(0,σ²) 형태이며 ‖β‖₂≤1이다. n개의 i.i.d. 샘플 {(x_i, y_i)}_{i=1}^{n}을 이용해 최소 노름 해 β̂ = X†y를 구한다. 여기서 X∈ℝ^{n×d}는 데이터 행렬, †는 Moore‑Penrose 의사역이다.
분석은 크게 두 부분으로 나뉜다. 첫째, β̂의 형태를 n과 d의 비율에 따라 구분한다. n ≥ d(언더파라미터화)에서는 유일한 최소제곱 해가 존재하고, n < d(오버파라미터화)에서는 무수히 많은 해가 존재하지만 gradient descent는 ‖β̂‖₂가 최소인 해를 찾는다. 둘째, 기대 초과 위험 E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기