큰 모델과 더 많은 데이터가 오히려 성능을 떨어뜨린다: 딥 더블 디센트 현상
이 논문은 모델 크기와 학습 에폭을 늘릴수록 테스트 오류가 처음에는 증가했다가 다시 감소하는 “더블 디센트(double‑descent)” 현상을 다양한 딥러닝 작업에서 실험적으로 입증한다. 저자들은 이를 설명하기 위해 “Effective Model Complexity(EMC)”라는 새로운 복잡도 척도를 정의하고, EMC가 데이터 샘플 수와 비교될 때 나타나는 세 구역(언더‑파라미터, 크리티컬, 오버‑파라미터)에서 테스트 성능이 어떻게 변하는지를…
저자: Preetum Nakkiran, Gal Kaplun, Yamini Bansal
본 논문은 현대 딥러닝에서 관찰되는 “더블 디센트(double‑descent)” 현상을 다각도로 조사한다. 전통적인 통계학에서는 모델 복잡도가 일정 수준을 넘으면 과적합으로 인해 테스트 오류가 단조롭게 증가한다는 편향‑분산 트레이드오프가 지배적이다. 그러나 최근 딥러닝 모델은 파라미터 수가 수백만에 달해 무작위 라벨까지도 학습할 수 있음에도 불구하고, 오히려 큰 모델이 더 좋은 성능을 보이는 경우가 많다. 저자들은 이러한 모순을 해소하기 위해 두 가지 축(모델 크기와 학습 에폭)에서 더블 디센트를 실험적으로 재현하고, 이를 설명할 새로운 복잡도 척도인 “Effective Model Complexity(EMC)”를 제안한다.
EMC는 특정 학습 절차가 평균 훈련 오류를 ε 이하로 만들 수 있는 최대 샘플 수로 정의된다. 즉, 모델 자체의 파라미터 수뿐 아니라 옵티마이저, 학습 스케줄, 라벨 노이즈 등 모든 학습 요인이 복합적으로 작용해 실제 “복잡도”를 결정한다. 저자들은 EMC와 실제 훈련 샘플 수 n 사이의 관계에 따라 세 구역을 구분한다.
1. **언더‑파라미터 구역 (EMC ≪ n)** – 모델이 데이터 전체를 충분히 설명하지 못해 편향이 크게 작용한다. 이 구역에서는 모델 크기·학습 시간 증가가 테스트 오류를 감소시킨다.
2. **크리티컬 구역 (EMC ≈ n)** – 모델이 처음으로 훈련 데이터를 거의 완벽히 맞추는 인터폴레이션 임계점에 도달한다. 여기서는 복잡도가 약간 증가해도 테스트 오류가 급격히 상승할 수 있다. 이는 모델이 거의 유일한 인터폴레이터가 되어 노이즈에 과도하게 민감해지기 때문이다.
3. **오버‑파라미터 구역 (EMC ≫ n)** – 모델이 충분히 과잉 파라미터화되어 다수의 인터폴레이터가 존재한다. SGD와 같은 옵티마이저는 노이즈를 “흡수”하면서도 일반화 성능을 회복시켜, 테스트 오류가 다시 감소한다.
이 세 구역은 모델‑와이드, 에폭‑와이드, 샘플‑와이드 세 차원에서 각각 관찰된다.
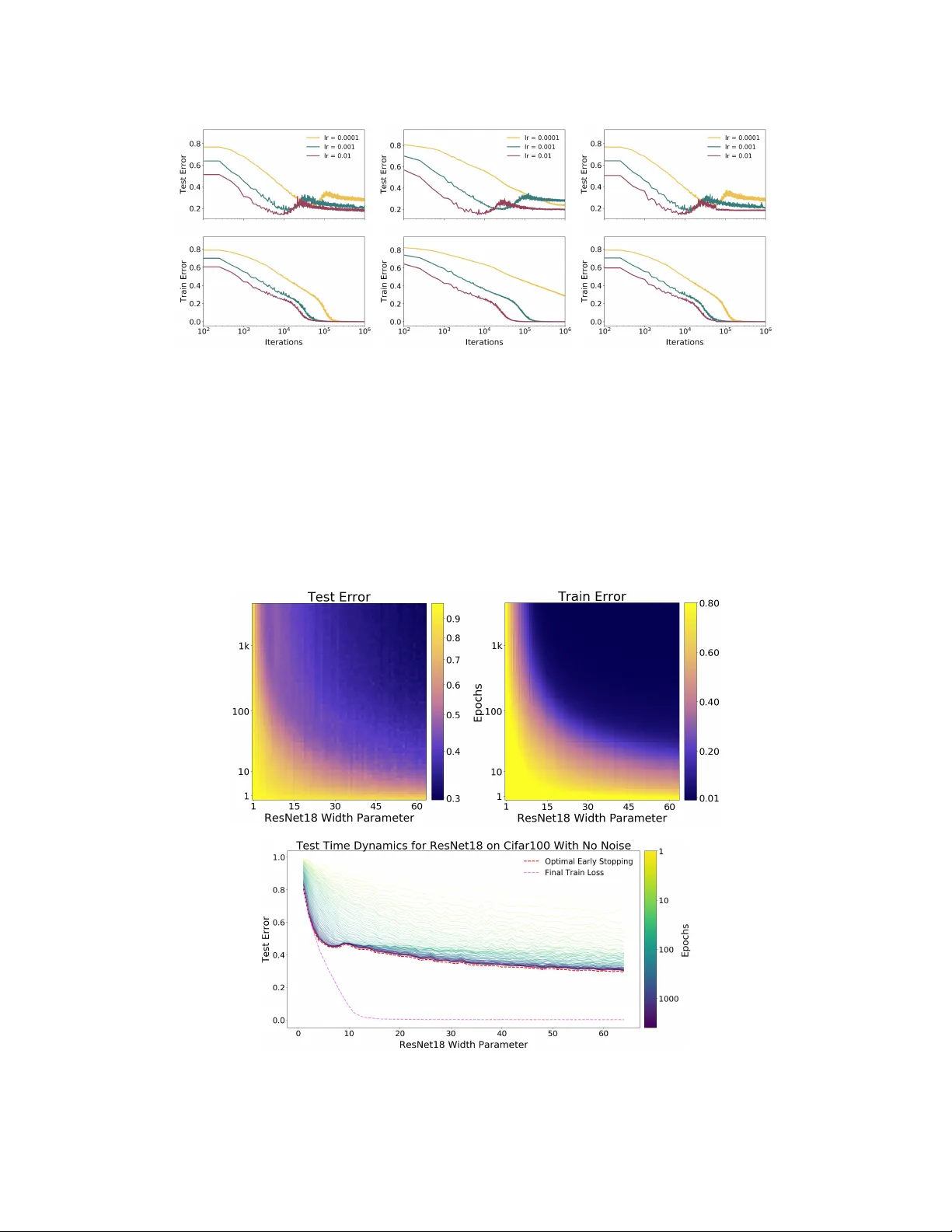
**모델‑와이드 더블 디센트**에서는 ResNet‑18, 5‑layer CNN, 6‑layer Transformer 등 다양한 아키텍처를 폭넓게 스케일링한다. 모델 폭을 늘릴수록 테스트 오류는 처음 감소하다가 인터폴레이션 임계점에서 피크를 형성하고, 그 이후 다시 감소한다. 라벨 노이즈 비율을 높이면 피크가 더 뚜렷해지며, 데이터 증강이나 훈련 샘플 수 증가도 피크를 오른쪽으로 이동시킨다.
**에폭‑와이드 더블 디센트**는 고정된 대형 모델을 장시간 학습시켜 관찰한다. 초기 학습 단계에서는 오류가 감소하지만, 훈련 오류가 거의 0에 도달하는 순간 테스트 오류가 급등한다. 이후 학습을 계속하면 오류가 다시 감소해, 충분히 긴 학습이 과적합을 “교정”할 수 있음을 보여준다. 이는 조기 종료가 크리티컬 구역에만 유효함을 시사한다.
**샘플‑와이드 비단조성**은 동일 모델·학습 절차에 대해 훈련 샘플 수를 변화시킨다. 일반적으로 샘플 수가 늘어나면 테스트 오류가 감소하지만, 크리티컬 구역을 지나면서 피크가 오른쪽으로 이동한다. 따라서 경우에 따라 더 많은 데이터가 오히려 성능을 악화시킬 수 있다. 논문은 IWSLT‑14 독일‑영어 번역 실험에서 4k 샘플 대비 18k 샘플을 사용했을 때 퍼플렉시티가 상승하는 현상을 제시한다.
라벨 노이즈가 있는 경우 더블 디센트 현상이 더욱 강조되지만, 라벨이 깨끗한 상황에서도 피크 혹은 평탄한 “플래토”가 관찰된다. 특히 ResNet‑18을 CIFAR‑100에 적용했을 때 라벨 노이즈 없이도 뚜렷한 피크가 나타난다.
저자들은 선형 최소제곱 회귀에 대한 기존 이론(예: Belkin et al., Bartlett et al.)과 연결해, 인터폴레이션 임계점에서 모델이 거의 유일하게 데이터에 맞춰질 때 노이즈에 민감해져 오류가 급증하고, 파라미터가 충분히 많아지면 다수의 인터폴레이터가 존재해 SGD가 노이즈를 흡수한다는 메커니즘을 제시한다.
결론적으로, 논문은 모델 크기·학습 시간·데이터 양이 서로 얽힌 복잡한 일반화 현상을 “Effective Model Complexity”라는 통합된 개념으로 설명하고, 실무에서 무조건적인 모델 확대·데이터 증강이 최선이 아님을 경고한다. 특히 크리티컬 구역에서는 조기 종료, 적절한 정규화, 혹은 데이터 품질 개선이 더 큰 효과를 낼 수 있음을 시사한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기