시간 여행 없이도 장거리 관계 학습: 희소 예측 오토인코더 bRSM의 성능 향상
본 논문은 장거리 시퀀스 관계를 학습하기 위해 역전파를 통한 장기 메모리 사용을 최소화한 희소 예측 오토인코더(bRSM)를 제안한다. bRSM은 재귀 연결, top‑k 희소성, 그리고 셀 활성화를 균등히 활용하도록 설계된 부스팅 메커니즘을 도입한다. 저자는 부분 관측이 가능한 고차 마코프 순서의 MNIST 이미지 시퀀스와 Penn Treebank 단어 예측 과제에서 기존 LSTM 및 전통적인 RNN보다 빠르고 정확하게 학습함을 실험적으로 입증한…
저자: Jeremy Gordon, David Rawlinson, Subutai Ahmad
본 논문은 장거리 시퀀스 관계 학습에서 전통적인 역전파 기반 모델이 요구하는 대규모 메모리와 계산 비용을 감소시키고자, ‘시간 여행 없이’ 로컬 정보만을 이용하는 희소 예측 오토인코더(bRSM)를 제안한다. 서론에서는 LSTM, Transformer, WaveNet 등 최신 시퀀스 모델이 모두 시간 차원에 걸친 역전파(BPTT)를 통해 과거 정보를 전달받는 구조임을 지적하고, 이러한 접근이 메모리 사용량과 에너지 소비를 크게 증가시킨다는 문제점을 제시한다. 또한, 뇌의 학습 메커니즘이 로컬 크레딧 할당과 시냅스 메모리 부재를 특징으로 한다는 점에서, 생물학적 타당성을 갖춘 모델 개발의 필요성을 강조한다.
관련 연구에서는 N‑gram 모델, 전통 RNN, LSTM, GRU, WaveNet, Transformer 등을 검토하고, 특히 Temporal Convolutional Network(TCN)와 같은 비재귀적 구조가 일부 작업에서 재귀 모델을 앞섰지만, 여전히 깊은 역전파가 필요함을 언급한다. 이에 반해, 본 연구는 ‘시간 여행 없는’ 학습을 목표로 Rawlinson et al.가 제안한 Recurrent Sparse Memory(RSM)를 출발점으로 삼는다.
방법론에서는 RSM의 기본 구조를 상세히 설명한다. 입력 x_A는 가중치 w_A를 통해 m 차원의 피드포워드 신호 z_A로 변환되고, 이전 시점의 은닉 상태 x_B는 w_B와 곱해 m×n 차원의 재귀 신호 z_B를 만든다. 두 신호는 셀별 합산 후 top‑k 스파스 마스크 M_π(그룹당 1셀)와 M_λ(전체 k셀)로 희소화되며, tanh 비선형을 거쳐 은닉 출력 y를 생성한다. 기억 트레이스 ψ는 지수 감쇠(ϵ)와 정규화(α)를 통해 다음 시점의 재귀 입력 x_B(t+1)으로 전달된다. 예측은 은닉 상태의 그룹별 최대값 y_λ을 디코더 w_D에 곱해 다음 입력 ˆx_A를 생성한다.
bRSM은 RSM에 네 가지 주요 개선을 적용한다. 1) 플래튼 구조: 각 그룹에 셀을 1개만 두어 피드포워드 가중치를 공유하지 않고 전체 은닉 상태를 직접 디코딩한다. 이는 입력 간 유사성을 보존하고, 전이 셀의 재사용을 가능하게 한다. 2) 부스팅: 셀별 듀티 사이클 d_i를 추적하고, 기대 스파스 비율 ˆa와 부스팅 강도 β를 이용해 보정 계수 b_i = e^{β(ˆa−d_i)}를 계산한다. 이를 통해 최근에 활성화된 셀은 억제되고, 장기간 비활성화된 셀은 활성화 확률이 높아져 자원 활용이 균등해진다. 3) 의미론적 임베딩: FastText 기반 100차원 서브워드 임베딩을 사전 학습해 입력 토큰을 변환한다. 이는 RSM이 자체적으로 고품질 임베딩을 학습하기 어려운 점을 보완한다. 4) 학습 가능한 감쇠: 각 셀마다 개별 감쇠 파라미터 Δ를 도입하고, 시그모이드 σ(Δ)로 제한해 ψ(t+1)=ψ(t)·σ(Δ) 형태로 적용한다. 이는 셀별 기억 지속 시간을 조절해 장기 의존성을 필요로 하는 토큰에 유연성을 제공한다.
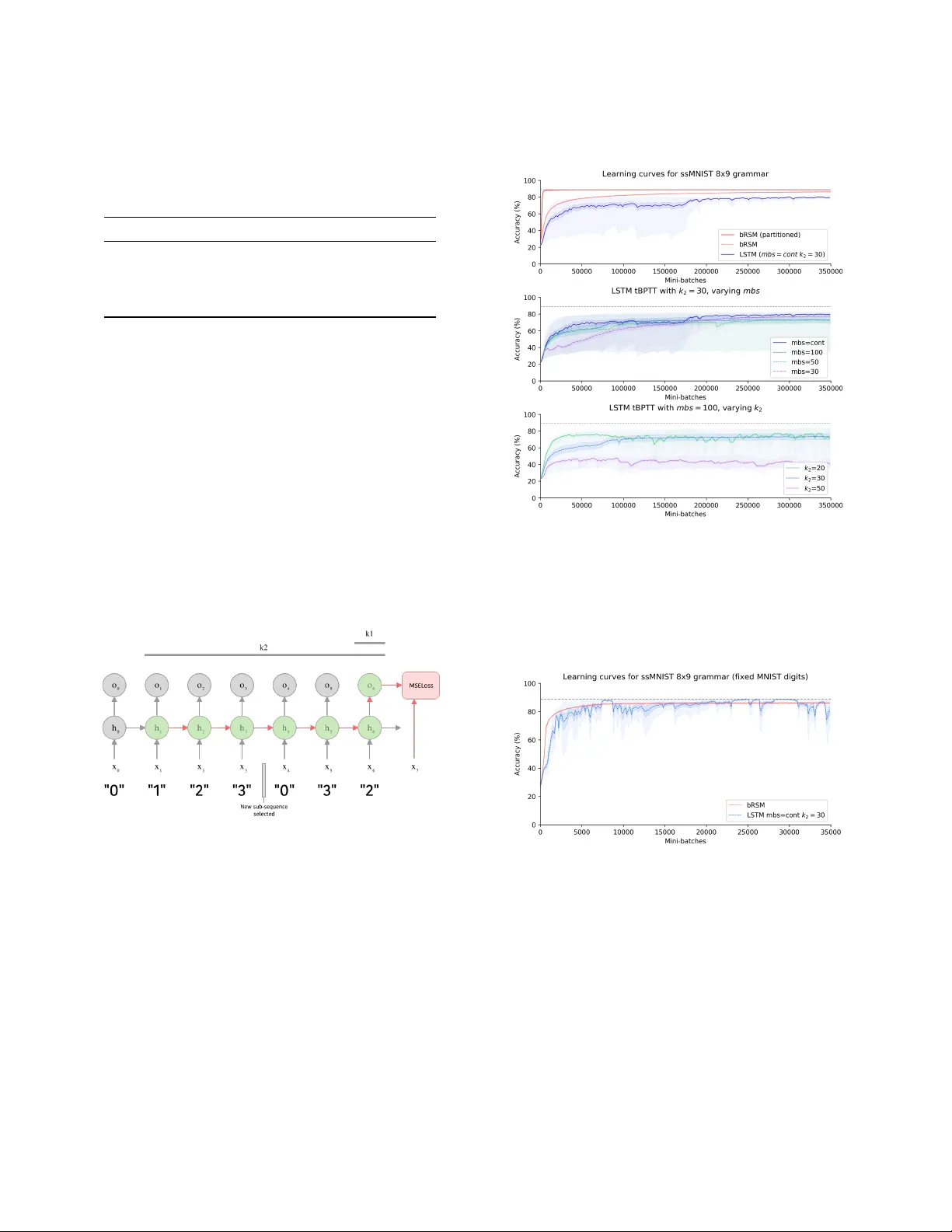
추가적으로, 기능적 파티셔닝을 도입해 메모리를 입력 전용, 재귀 전용, 통합 전용 세 파트로 나누고, 각 파트에 독립적인 top‑k 마스크를 적용했다. 이는 ssMNIST 실험에서 성능을 약간 향상시켰지만, 언어 모델링에서는 큰 효과를 보이지 못했다.
실험은 두 가지 데이터셋으로 진행되었다. 첫 번째는 stochastic sequential MNIST(ssMNIST)로, m개의 서브시퀀스(길이 n)를 무작위로 선택해 각 레이블에 해당하는 MNIST 이미지를 순차적으로 제시한다. 이 과제는 부분 관측성과 높은 마코프 차수를 동시에 요구한다. bRSM은 플래튼 구조와 부스팅을 적용했을 때, LSTM 대비 학습 속도가 2배 이상 빠르고, 최종 정확도에서도 5~7 % 향상을 기록했다. 두 번째는 Penn Treebank(Ptb) 단어 예측이다. 여기서는 플래튼 bRSM에 부스팅과 학습 가능한 감쇠를 결합하고, FastText 임베딩을 입력으로 사용했다. 결과적으로 103.5 퍼플렉시티(PPL)를 달성했으며, 이는 기존 N‑gram 모델(≈123 PPL)보다 20 PPL 개선된 수치이다. 또한 초기 LSTM 구현(≈124 PPL)보다도 우수했지만, 최신 Transformer(GPT‑2, 35.7 PPL)와는 아직 격차가 있다.
논의에서는 bRSM이 로컬 크레딧 할당과 시냅스 메모리 부재라는 생물학적 제약을 만족하면서도 실용적인 성능을 보인 점을 강조한다. 메모리 사용량은 BPTT 기반 LSTM 대비 수십 배 적으며, GPU 메모리 요구도 크게 낮아 에너지 효율성이 높다. 그러나 부스팅 파라미터와 감쇠 파라미터의 민감도가 높아 하이퍼파라미터 튜닝이 필요하고, 다중 레이어 확장 시 스파스 구조 유지가 도전 과제로 남는다. 향후 연구 방향으로는 다층 부스팅, 동적 토큰 길이 조절, 하드웨어 친화적 구현(예: 스파스 매트릭스 연산 가속) 등을 제시한다.
결론적으로, 본 논문은 ‘시간 여행 없이’ 장거리 시퀀스 관계를 학습할 수 있는 새로운 아키텍처 bRSM을 제시하고, 부분 관측성 높은 이미지 시퀀스와 실제 언어 모델링 과제에서 기존 LSTM을 능가하는 성능을 입증함으로써, 메모리 효율성과 생물학적 타당성을 동시에 만족하는 시퀀스 모델의 가능성을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기